
此论文内容来自于复旦-达观联合研究成果,发表于第 61 届国际计算语言学协会年会(ACL 2023)
关系抽取(Relation Extraction,RE)是自然语言处理领域一项重要的基础任务,旨在从非结构化文本中提取实体对之间的关系。抽取出来的关系事实在诸多下游应用中具有重大实用价值,比如智能对话系统、知识图谱、互联网信息检索等。
许多研究致力于提高关系抽取的质量。传统的有监督关系抽取针对的是在预先定义模式下的已知关系。因此,这类方法遵循封闭集设置,即训练和测试过程中涉及的关系保持不变。如今,神经网络关系抽取方法在这种封闭集设置下取得了显著成果。与之相对,开放关系抽取(OpenRE)则聚焦于发现不断涌现的未知关系。常见做法包括直接标记连接实体对的关系短语,以及对具有相同关系的实例进行聚类。然而,实际应用中的关系抽取遵循开放集设置,这意味着测试数据中既有已知关系,也有未知关系。这就要求模型不仅能够区分已知关系,还能过滤掉表达未知关系的实例。这种过滤实例的能力也被称为“以上皆非”( none-of-the-above ,NOTA)检测。
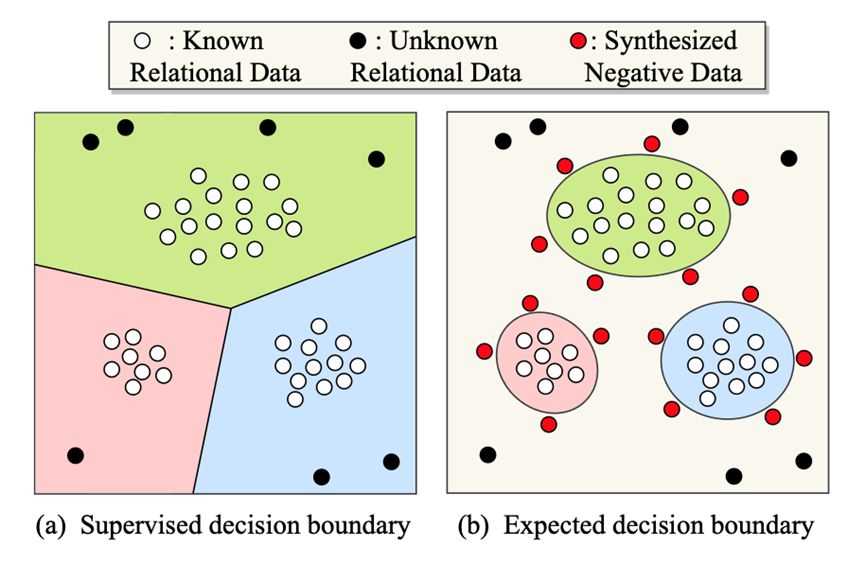
图 1 仅在已知关系上优化的决策边界无法应对开放集设置,在开放集设置中,输入可能来自训练中未见过的关系。我们旨在通过合成困难负实例来规范决策边界。
遗憾的是,一个在封闭集上表现出色的模型,在遇到未知测试数据时,仍可能做出错误的预测。如图1(a)所示,决策边界仅在已知关系数据(白点)上进行了优化,导致整个空间被划分为三个区域。因此,未知关系数据(黑点),尤其是那些远离决策边界的数据,会被以高置信度分类到某个已知关系中。相比之下,图1(b)中更紧凑的决策边界对NOTA检测更有利。然而,构建紧凑的决策边界需要使用 “困难” 的负样本数据(图1(b)中的红点),这样才能提供强大的监督信号。需要注意的是,合成这样的负样本数据并非易事。
在这项研究中,我们提出了一种未知感知训练方法,该方法能同时优化已知关系分类和NOTA检测。我们迭代生成负实例,并优化NOTA检测分数。在测试阶段,分数较低的实例会被视为NOTA并过滤掉。该方法的关键在于合成 “困难” 的负样本实例。受文本对抗攻击的启发,我们通过替换原始训练实例中的少量关键词汇来实现这一目标。这样一来,原本的关系语义就会被抹去,而模型却无法察觉。借助基于梯度的词汇(token)归因和语言规则,我们能够找到表达目标关系的关键词汇。然后,这些词汇会被使NOTA检测分数提升最大的误导性普通词汇所替换,从而合成更易被模型误判为已知关系的误导性负实例。人工评估显示,几乎所有合成的负实例都不表达任何已知关系。实验结果表明,我们提出的方法能学习到更紧凑的决策边界,并在NOTA检测性能上达到了当前最优水平。
本文的贡献主要体现在三个方面:
01
我们提出了一种新的未知感知训练方法用于开放集关系抽取。该方法在不影响已知关系分类的前提下,实现了最先进的NOTA检测;
02
与主流合成方法相比,我们合成的负实例给模型带来了更大的挑战;
03
全面的评估和分析为未来研究这一紧迫但尚未充分探索的任务提供了便利。
核心方法
01 任务定义

02 方法概述
我们提出未知感知的训练方法,该方法动态合成 “困难 ”的负实例,并优化已知关系分类和 NOTA 检测的双重目标。如图 2 所示,训练循环由两个迭代步骤组成:
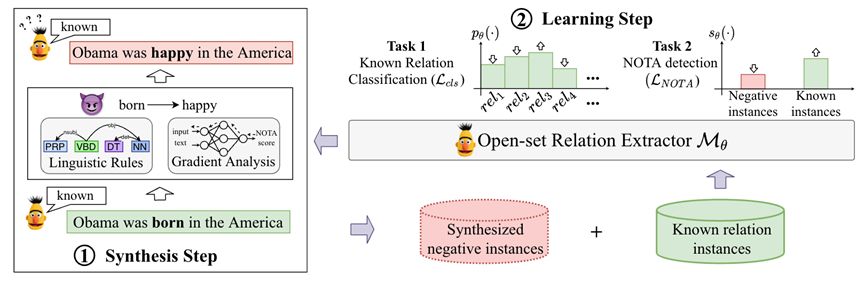
图2 提出的未知感知训练方法概述。训练循环由两个迭代步骤组成:合成步骤包括根据模型的状态自适应合成 “困难” 实例;而在学习步骤中,根据已知和合成的实例对已知关系分类和 NOTA 关系检测的双重目标进行优化。

03 开放集关系提取器
实例编码器和分类器:

NOTA 检测分数:

04 迭代式负实例合成

基于梯度的词汇归因:

基于语言规则的词汇权重调整:

误导性标记选择:

05 未知感知训练目标

实验结果
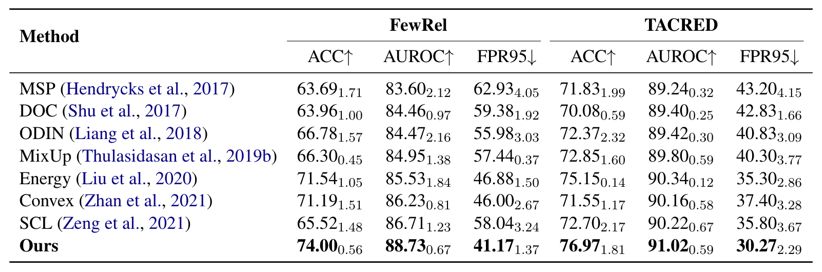
我们通过将所提出的方法与几种有竞争力的开放集分类方法进行比较来评估该方法。结果在表 1 中,从中可以观察到我们的方法实现了最先进的 NOTA 检测(通过 FPR95 和 AUROC 反映),而不会影响已知关系的分类(通过 ACC 反映)。在一些基线方法中(例如,MSP、ODIN、Energy、SCL),仅使用已知关系的实例进行训练。与它们相比,我们明确合成了负样本以完成缺失的监督信号,NOTA 检测的改进表明了未知感知训练的有效性。
表格 1开集关系提取的主要结果。下标表示相应的标准差(例如 $74.000.56$ 表示 74.00+0.56)。表 7 提供了 n 个已知关系的 ACC 结果。
为了直观地展示决策边界的变化,我们可视化了模型在输入空间中的决策边界。从图 3 可以看出,在未知感知训练的帮助下,学习到了更紧凑的决策边界。
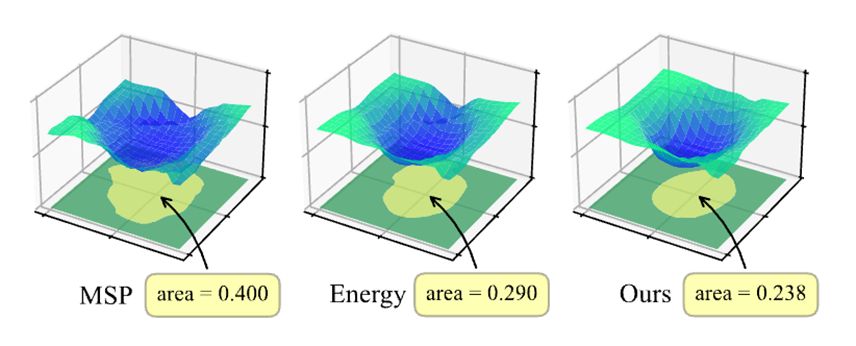
图 3 决策边界可视化。当删除未知感知训练时,能量可以被视为我们方法的退化版本。纵轴表示检测阈值 \alpha 与 NOTA 分数 s_\theta\left(x\right) 之间的差异,标准化为 [−1, 1] 的范围。当实例落在低于零的黄色区域内时,模型会将其分类为已知关系。相反,当句子落在零以上的绿色区域内时,模型会将其标识为 NOTA。




