
引言
国语有之“防民之口,甚于防川,”一句很简单的话却深刻地体现出了民众舆情的重要性,由此可见,放在商业环境下“听到客户的声音,对企业来说非常重要”。在如今移动互联网时代,我们身边充斥着各种各样的数据与信息,这些数据与信息成为重要的企业、用户舆情分析来源,有非常大的价值,那么如何高效地处理、分析这些数据,都有哪些业务场景,让我们来一起了解下。

一、做企业、客户洞察分析,非结构化的数据处理能力是关键

企业想要做大数据洞察分析要解决的问题有很多,从数据角度看关键的还是非结构化的处理能力。结构化的数据比如企业内部管理系统数据:ERP、CRM、客服系统以及各个终端的用户行为数据等,半/非结构化常见的如行网站留言、产品评论、微博评论、论坛、分析报告等,传统的分析系统面对结构化数据有较为成熟的解决方案,但是面对海量的半/非结构化数据却很难应用起来,有些企业甚至还依赖一些传统的操作方式,比如企业舆情人员在接受到任务后,直接从各种可能的信息源中查找出有参考价值的资料,手工整理、汇总后实现信息发现。
依靠人力只能分析局部信息,想要观察某行业、某群体的趋势、声量等,基本难以实现,因此如何从海量半/非结构化数据中提炼出价值信息,并将其转为结构化数据用来统计、分析是目前众多企业亟需解决的难题。
二、非结构化数据处理,需要NLP能力
达观自研NLP平台融合多种机器学习算法,结合达观数据独特的语义理解、分析引擎,能够对文本数据进行词汇级、句法级、篇章级的理解,一站式满足用户文本语义分析、文本分类、文本实体抽取、关系抽取、情感分析等需求,用户无需拥有丰富的算法背景,仅需小样本标注数据,即可通过平台快速创建算法模型并使用。
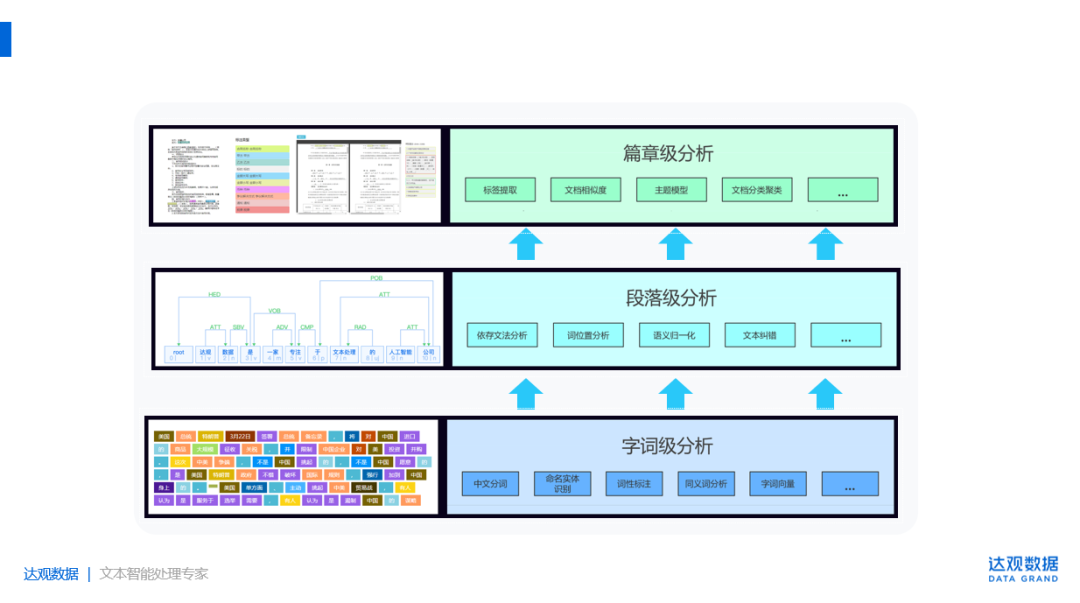
(图:达观NLP语义分析)
达观的VOC系统以自研的NLP平台为基础,能够有效地把非结构化数据转结构化,从而实现从海量且纷繁复杂的文本数据中提取有价值的信息,帮助企业实现感知社会舆论、挖掘用户需求、了解竞品动向、优化运营效率的目标。

(图:达观VOC系统架构图)
三、客户声音洞察系统场景举例
下面我们就通过几个业务场景介绍达观VOC系统的信息挖掘、分析能力。
场景1:以卡车之家论坛的用户评论数据为基础,通过对文本内容进行品牌抽取+时间维度+声量统计,能够获得某品牌的整体声量走势分析。

场景2:以卡车之家论坛的用户评论数据为基础,通过对文本内容进行品牌抽取+观点提取+情感分析+时间维度,能够获得某品牌的情感趋势分析。

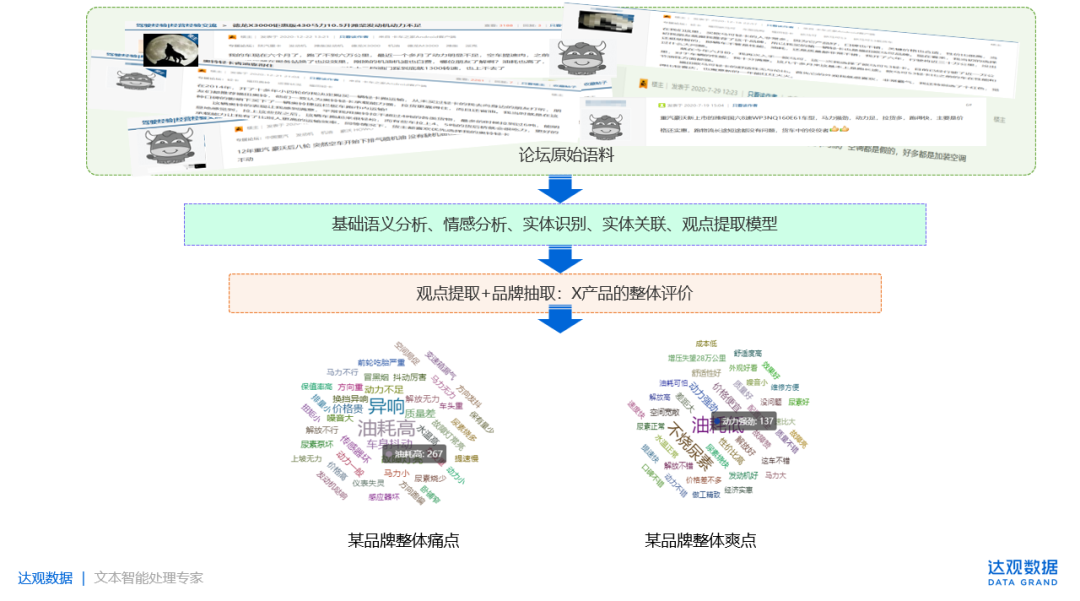
场景3:以卡车之家论坛的用户评论数据为基础,通过文本内容进行品牌抽取+观点提取+产品配置/性能分析+情感分析+时间维度,能够获得产品整体评价分析。
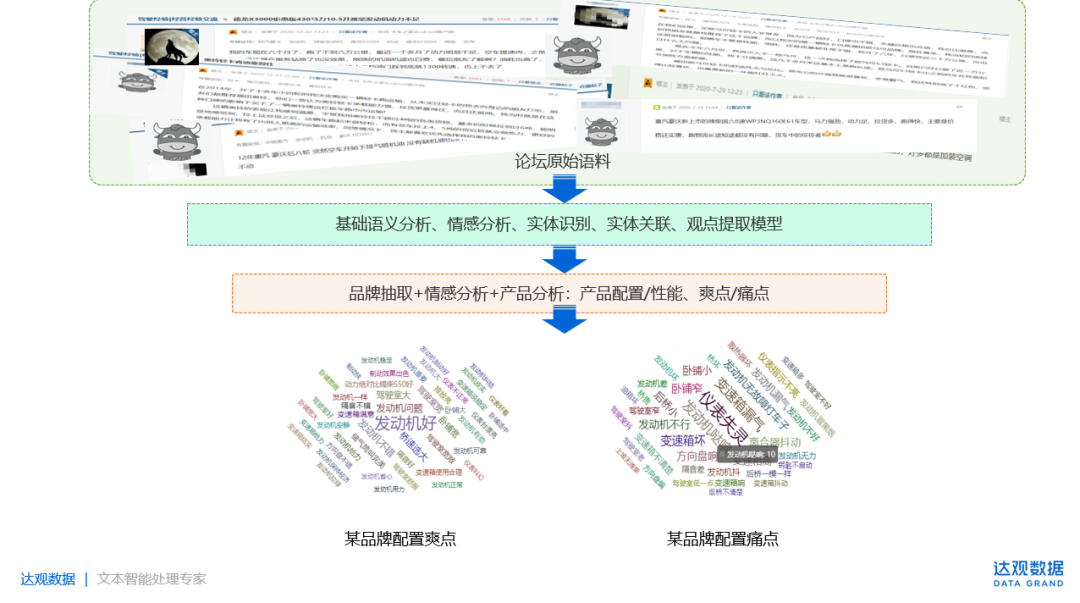
场景4:以卡车之家论坛的用户评论数据基础,通过对文本内容进行品牌抽取+观点提取+产品性能/配置分析+情感分析+时间维度,能够获得产品配置/性能分析。
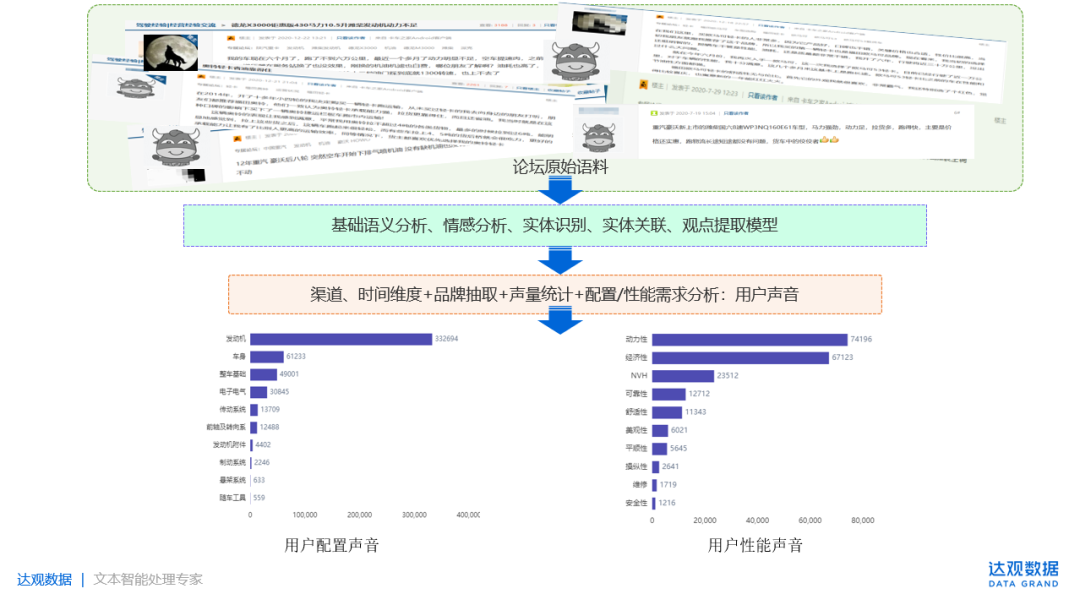
场景5:以卡车之家论坛的用户评论数据为基础,通过对文本内容进行分析,挖掘出用户对配置、性能潜在的需求分析。
场景6:以开源的资讯网站数据为基础,以企业为视角,对文本内容进行分析,挖掘出公司实体+情感分析+风险标签,能够预警相关企业风险。

场景7:以行业分析报告为基础数据,总结、提炼报告核心观点。
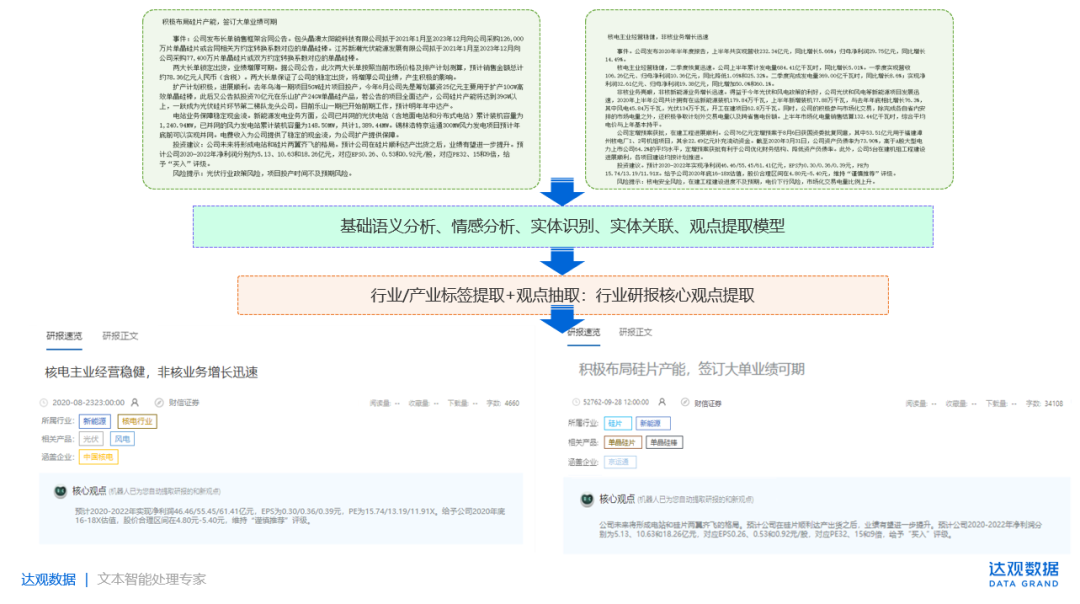
场景8:其他核心能力:数据清洗能力。
企业想要获得精准的企业、客户洞察分析,数据是基础,信息分析与挖掘能力决定系统的上限,但是往往数据的质量却是决定了系统水平的下限,垃圾数据会在整个分析过程中混淆用户视线,甚至影响用户决策,那么如何有效地清理垃圾数据呢?达观的客户声音洞察系统则通过以下2种方式解决大部分垃圾数据问题。
1、基于规则的定向清洗:基于文本标题、内容中包含某些关键词进行过滤、清洗,往往依赖业务人员梳理大量的违禁词典,效果比较精准,但是badcase较多,维护工作较为频繁。
2、基于语义理解的模型清洗:可以根据实际的业务需要定制不同类型的模型,比如想配合营销部门跟进微博、论坛、用户评论中的某款手机的产品评价,很明显评论中需要包含正/负面情感倾向以及有关于手机名字/型号的一些描述,则可以通过情感分析模型+命名实体模型过滤掉大部分垃圾数据;如果担心同一篇文章会被转载到多个渠道,或者是一些恶意刷帖、灌水等造成的数据重复问题,则可以通过文本比对模型来应对,文本相似度的阈值用户可以根据实际情况灵活配置。
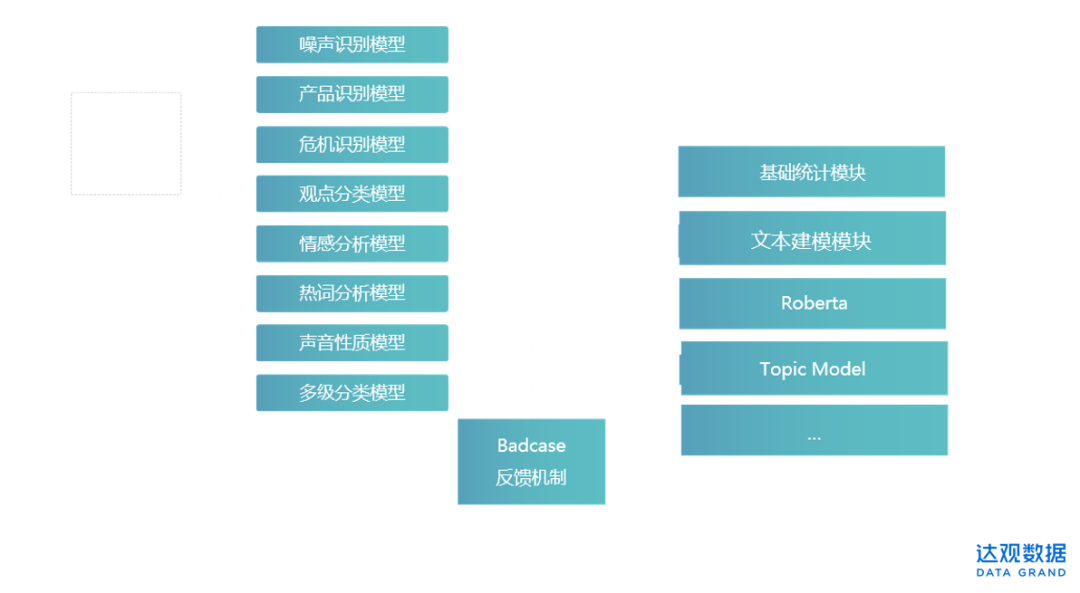
(图:达观模型自学习反馈机制)
说了这么多NLP给企业、用户洞察分析带来的优点、好处,那么应用过程中有哪些难点与挑战呢?任何一个模型都不可能是百分百精准,可能会导致信息分类、提取不准的情况。但达观的客户声音洞察系统的机器学习算法结合人工反馈机制,通过收集用户的操作、修改记录能够让模型的正样本数量与质量不停得到提升,结合算法工程师的辅助调优,从而让模型效果越用越好。
作者:达观数据万国龙




