
在企业知识管理的复杂环境中,信息的高效组织和快速检索至关重要。随着企业的发展,知识文档数量呈爆炸式增长,如何有效地管理这些文档成为了一个亟待解决的问题。达观大模型知识库所采用的文档自动重命名技术,为企业快速归纳知识提供了一种创新而高效的解决方案,极大地改善了知识管理的流程和效率。
企业内部的知识文档往往来源广泛,格式多样。不同部门、不同项目产生的文档在命名上可能缺乏统一标准,导致知识的混乱。例如,市场部门的调研报告可能命名为“市场调研 202405”,而研发部门的技术文档可能是一些随意的代码名或简单的版本号。这种混乱使得员工在寻找特定知识时,需要花费大量时间在搜索和筛选上,严重影响工作效率。
文档自动重命名能够依据一定的规则,将这些无序的命名规范化。它可以提取文档中的关键信息,如主题、项目名称、创建时间、作者等,重新赋予文档一个清晰、有意义的名称。这样,无论是市场人员查找最新的竞品分析报告,还是研发人员寻找特定版本的技术文档,都能更快速准确地定位。

在传统的文档管理模式下,企业知识检索往往依赖于关键词搜索或简单的文件夹分类。然而,关键词搜索可能因为命名不规范而遗漏重要文档,文件夹分类则在面对大量复杂知识时显得力不从心。
自动重命名后的文档能够更好地与企业知识库的索引系统配合。通过将关键信息体现在文件名中,达观大模型知识库的搜索算法可以更精准地匹配用户的查询。例如,当员工搜索“新产品 X 的市场推广策略”时,经过自动重命名的相关文档能够更快速地被检索出来,因为文件名中已经包含了“新产品 X”和“市场推广策略”等重要关键词,大大提高了知识检索的命中率和速度。
![]()
达观知识库利用先进的自然语言处理(NLP)技术来分析文档内容。NLP 技术可以对文档进行词法分析、句法分析和语义理解。在文档自动重命名过程中,首先进行词法分析,识别文档中的名词、动词、形容词等词汇,确定文档的核心词汇。例如,对于一份技术文档,它可以识别出其中的技术术语、产品名称等关键名词。
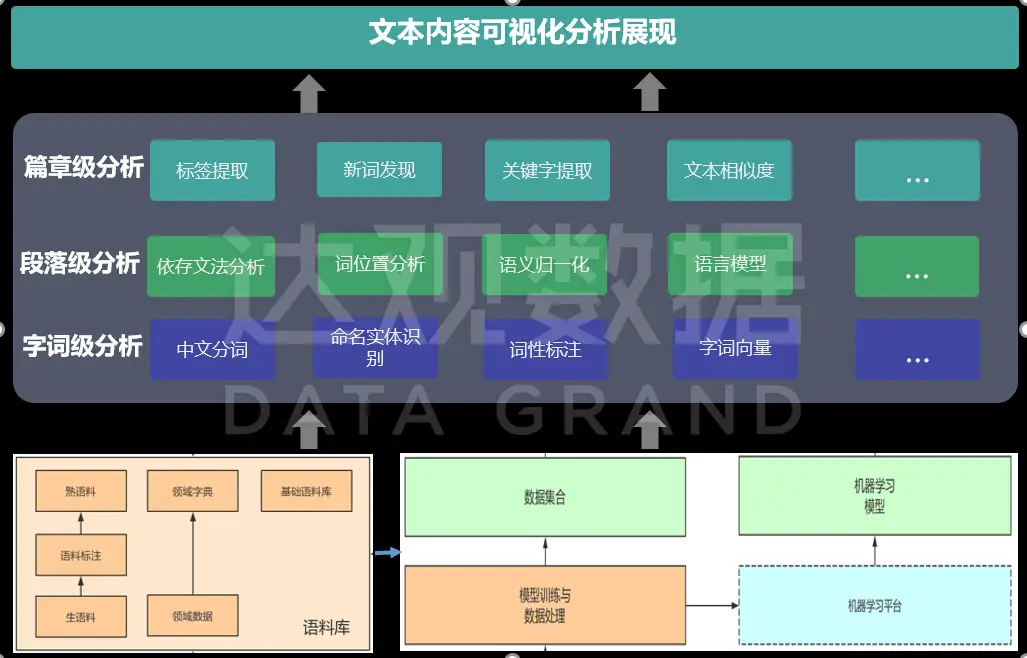
句法分析则帮助理解这些词汇在句子中的结构和关系,进一步确定文档的主题。语义理解更为深入,它可以分析文档中不同词汇和句子之间的逻辑关系,从而更准确地把握文档的核心内容。通过这些 NLP 技术的综合运用,系统能够从文档中提取出最有价值的信息用于重命名。
除了 NLP,达观大模型知识库还采用了规则引擎与机器学习相结合的方式。规则引擎中预定义了一系列的命名规则,这些规则可以根据企业的业务特点和知识管理需求进行定制。例如,对于项目文档,可以规定命名规则为“项目名称 – 文档类型 – 版本号 – 创建时间”。
机器学习算法则在大量的文档数据中不断学习和优化这些规则。它可以根据文档的实际内容和企业用户的使用习惯,对规则进行调整和补充。例如,如果发现某个部门经常按照特定的格式来命名文档,机器学习算法可以将这种格式纳入到规则引擎中,使得自动重命名更加符合企业的实际情况,提高重命名的准确性和有效性。
企业员工在搜索和整理知识文档上花费的时间成本是巨大的。据统计,员工平均每周可能花费数小时甚至更多时间在寻找合适的知识文档上。通过文档自动重命名实现快速知识归纳后,这一时间可以大大缩短。员工可以更快地找到所需知识,减少重复劳动,提高工作效率,从而为企业节省大量的人力成本和时间成本。
当知识文档能够被快速、准确地归纳后,企业员工可以更容易地获取全面的知识。他们可以在已有知识的基础上进行创新,例如研发人员可以参考过往项目的技术文档开发新的产品功能,市场人员可以借鉴成功的营销案例策划新的市场活动。同时,新员工也可以通过清晰的知识体系更快地融入企业,学习和传承企业的知识和经验,保持企业知识的连续性。
在当今竞争激烈的市场环境中,企业的竞争力在很大程度上取决于其知识管理的水平。高效的文档自动重命名和知识归纳使得企业能够更快地响应市场变化,做出更明智的决策。例如,企业可以快速整合市场信息和内部技术知识,推出更符合市场需求的产品和服务,在竞争中占据优势。
达观大模型知识库的文档自动重命名功能为企业快速归纳知识提供了一种高效、可靠的解决方案。它通过先进的技术手段,解决了企业知识文档命名混乱、检索困难等问题,在项目知识整合、部门知识梳理和企业知识地图构建等方面发挥了重要作用,为企业带来了显著的价值。在实施过程中,虽然需要注意初始设置、数据安全和员工培训等问题,但只要合理规划和有效管理,文档自动重命名将成为企业知识管理的有力工具,助力企业在知识经济时代更好地发展。




