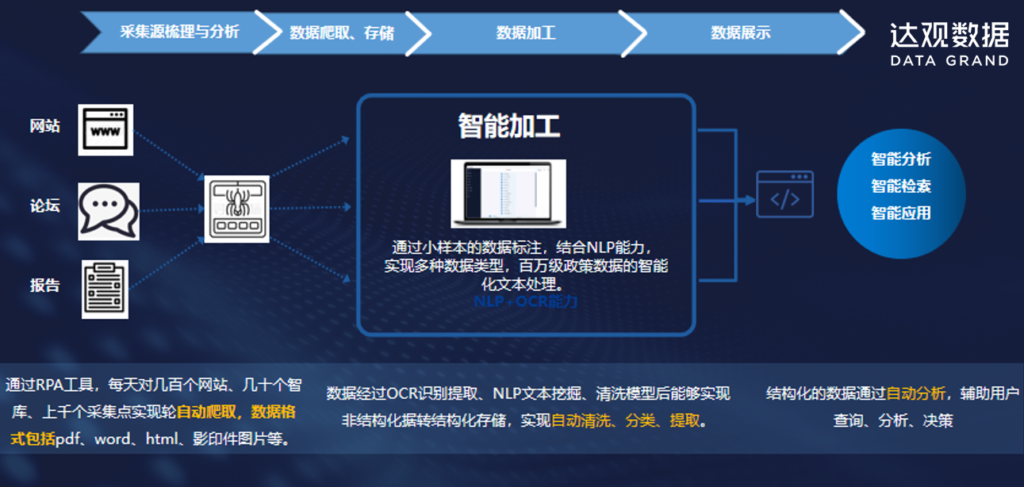
了解分析政策不仅能帮我们描绘出政策变迁的路线图、了解国家各时期的发展重点,还能在分析过程中帮我们发掘其背后的规律,发现政策的演变轨迹,从而对政策趋势进行量化呈现与规律性预判。
2014年12月01日发布的《国务院办公厅关于加强政府网站信息内容建设的意见》,明确要求各级政府要将政府网站作为政府信息公开的第一平台,第一时间发布政府的政策信息。基于以上政策要求,政策信息、政策数据的公开透明化是合法、合规且必须的,政策文献不再尘封于“深宫密闱”之中。
当分析政策时,首先要解决的就是政策数据的获取、梳理的工作,手工整理、分析政策数据不仅工作量大、且难免保证不会出错,利用传统的爬虫工具也可能导致频繁的封IP,网站版式变更、升级会导致爬取策略失效、出错,维护成本较高,甚至还有可能带来其他安全风险,采购第三方的政策数据则面临不菲的采购费用,而且后续数据的更新依赖性也较强。
随着近年来AI技术的发展,大型机构已经在政策数据获取、数据加工整合、数据分析展示等取得不错的成果。下文将从政策分析的不同场景出发,详解达观数据在政策数据获取、政策数据加工等方面的实践。
RPA“Robotic Process Automation(机器人流程自动化)”它通过模拟人的鼠标、键盘操作,代替人与业务系统进行交互,能自动完成规则明确、重复性高的业务流程,可将人类重复枯燥的基础性工作效率提高n倍,达观RPA上手简单,没有代码基础的人员也能完成相关的配置。在政策分析领域的应用上,RPA可完全胜任政策数据的采集、整理、汇编、入库等一系列操作。而且达观RPA在系统之间集成方便、软件是非侵入式、安全、高效,不会给相关网站造成安全上的隐患。
达观RPA技术”在某政策智库项目上,从政策数据的采集到加工、展示等方面的成熟应用
政策数据获取到之后,往往需要根据政策内容,把多源异构的数据进行统一类目的梳理,如做数据的打标或者分类,比如可以根据政策内容可以分为基本政策、政治政策、经济政策、社会政策、科技政策、文化政策、产业政策等,便于政策的检索和更有针对性的分析。
达观NLP的文本分类组件,让计算机通过预先阅读各个类目的文档并提取特征,完成有监督的学习,从而计算机能够自动的完成新政策的内容归类。例如上图为通过“达观NLP标签模型”按照国民经济行业分类体系对政策数据进行自动分类。
达观NLP文本分类技术”将政策智能分类在某智库系统的展示效果
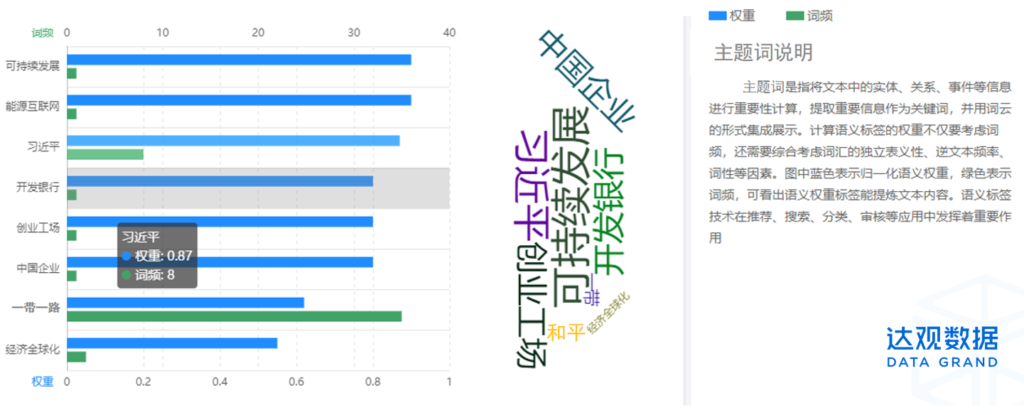
政策文献存在“主题词”结构要素,这一结构要素的词汇主要来源于国务院、科技部、教育部公文主题词表等规范性资料。如“脱贫攻坚”“一带一路”。
政策文献“主题词”起初是为了满足公文归档与分类的需要,有数量稀疏、词汇老化、对政策内容的揭示性不足等现象,如国务院主题词表786个,自1988年修订一来无更新,若完全遵循国务院公文主题词表,就会遗漏很多政策文献的重要信息与变化,因而政策分析需要在原有政策文献“主题词”的基础上进行更新补充。
“达观智能主题词提取模型”通过NLP(自然语言处理)技术,不仅可以统计“主题词”频次的高低,更能综合考虑词汇的独立表义性、逆文本频率、词性等因素,从而一定程序上揭示政策主题的热度与潜在关联。例如达观智能主题词提取模型”对习主席出席“一带一路”国际合作高峰论坛演讲稿《携手推进“一带一路”建设》进行分析后,得出的主题词如下:
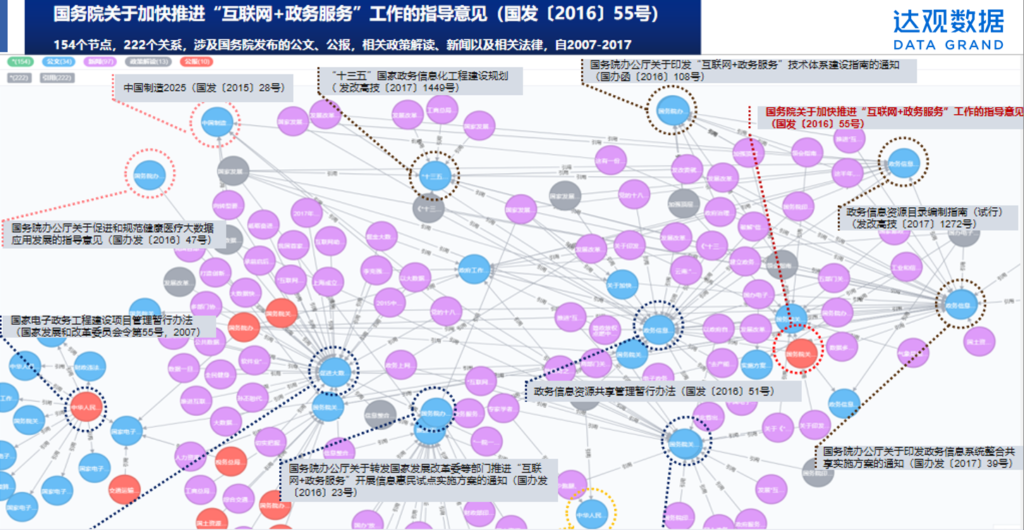
政策文献及其关联关系经过一段时间的积累后,会形成复杂的关联网络,政策分析者需要挖掘政策间的内引规律,验证定性的主观判断,呈现政策演变轨迹。
这是一项非常庞杂的工作,仅依靠文字、手工记录几乎难以实现。达观在服务客户的过程中,主要是利用RPA结合知识图谱技术、NLP技术,在政策数据的加工处理过程中,挖掘出政策间的引用、衍生关系,把非结构化的政策数据转化为图关系型数据,最终为政策分析者提供便捷、可视化的政策图谱网络。以下为达观知识图谱技术”依据《国务院关于加快推进“互联网+政务服务”工作指导意见》为政策主题,衍生出的政策关系图谱。
除了上文介绍的RPA、NLP、智能图谱在政务行业的应用场景之外,达观智能办公机器人产品矩阵已覆盖金融、法律、运营商、电商、文娱等众多行业的多场景智能化解决方案。通过机器人流程自动化(RPA)、自然语言处理(NLP)、共光学字符识别(OCR)、知识图谱、智能搜索、智能推荐、文档智能审阅等自动化与人工智能技术的结合,未来,达观数据也将继续助力企业快速实现智能化升级。