
近年来,随着人工智能技术的迅速发展,大模型与知识图谱成为了人工智能领域的研究热点。大模型具有强大的特征表示能力和泛化性能,而知识图谱则是一种语义网络,可以表达实体、概念和它们之间的关系。因此,将大模型与知识图谱构建相结合,可以进一步提高人工智能系统的性能和实用性。本文将介绍知识图谱的基本构建流程,包括知识表示与建模、图谱构建、图谱应用三个环节。并着重介绍大模型在图谱构建环节中的应用,主要体现在对非结构化文档的信息抽取中。
知识图谱构建
从知识图谱构建的流程开始,传统的知识图谱构建主要包括以下几个步骤:
步骤1:知识表示与建模
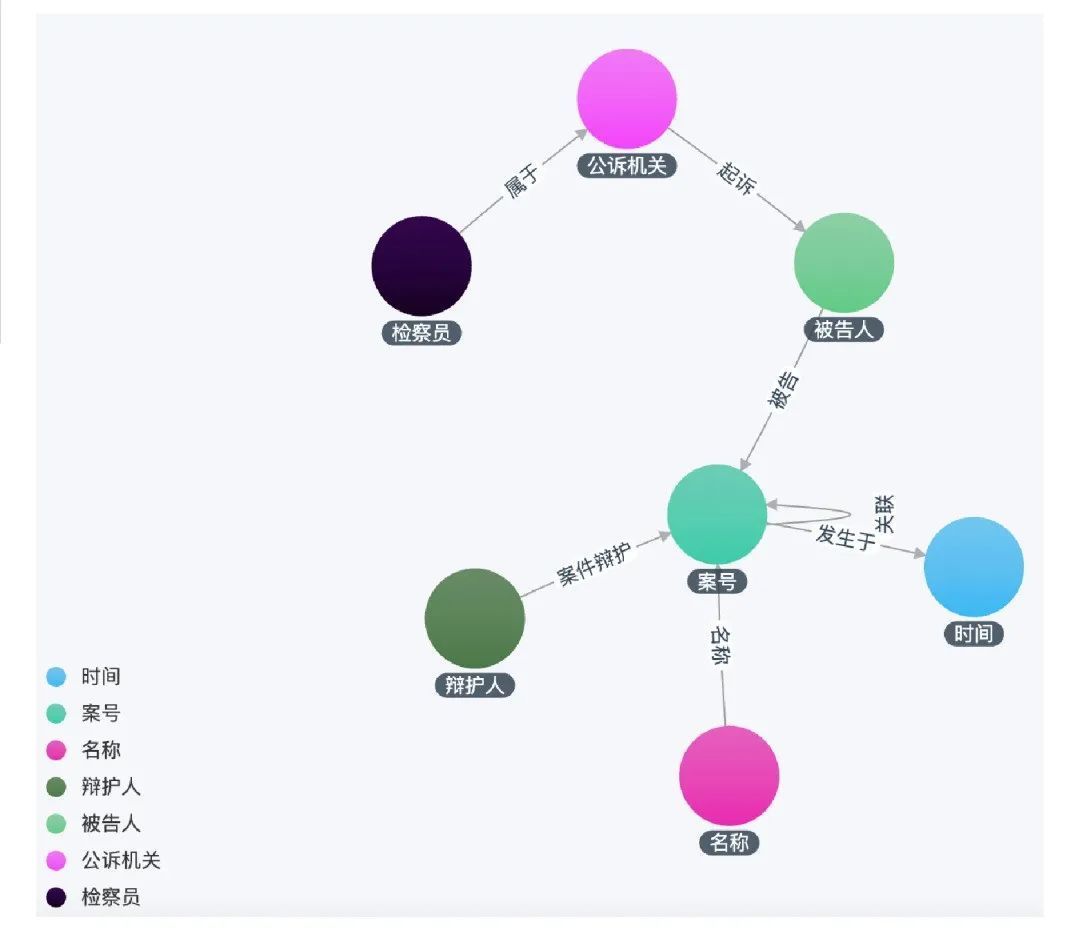
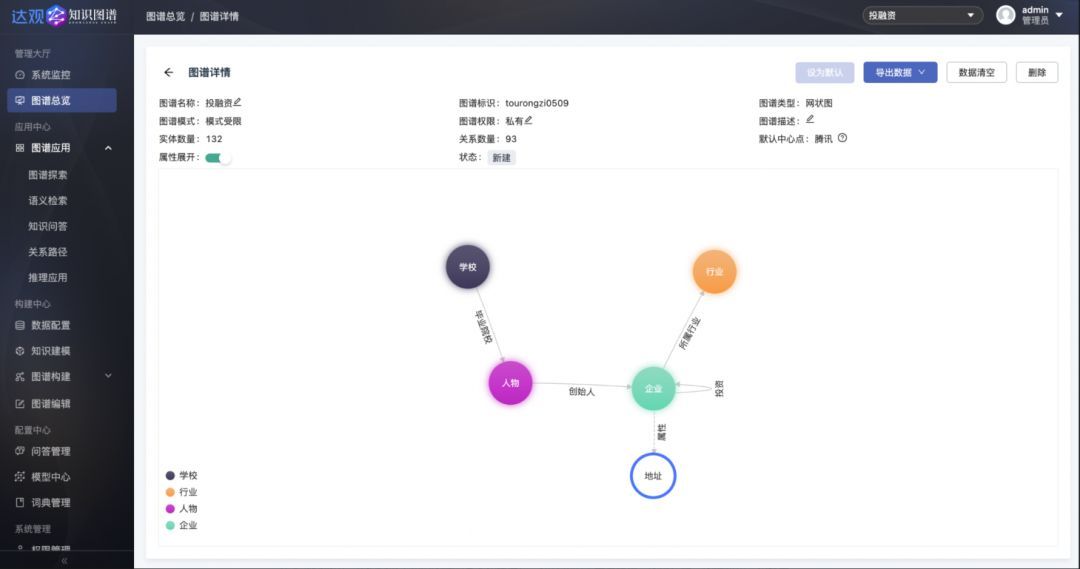
也称图谱模式建立,指从现实世界中抽象出概念、实体及其关系,以结构化的形式进行描述,表达成计算机可存储和计算的结构。以投融资知识图谱为例:
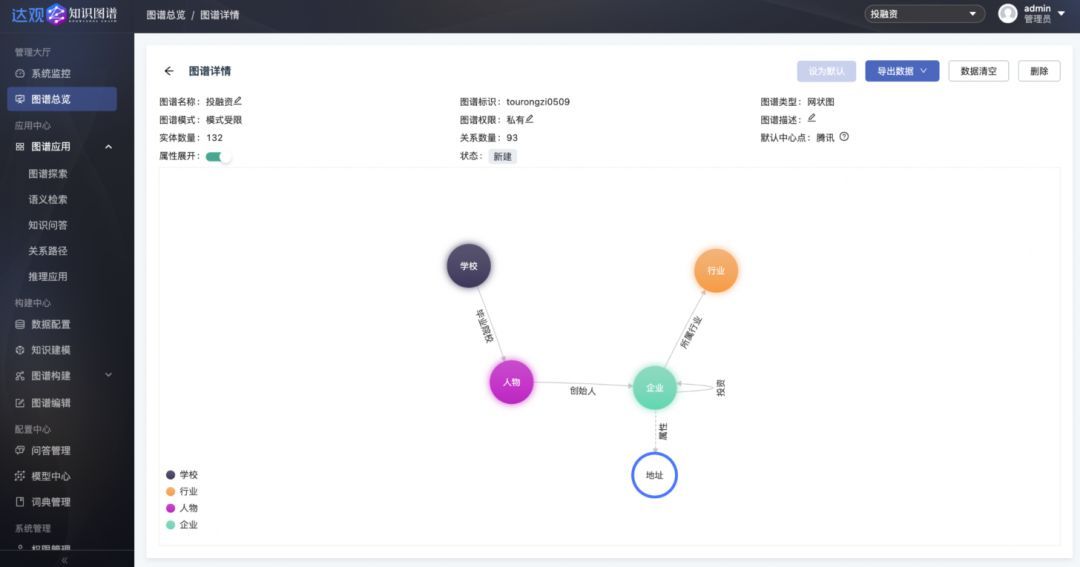
可以看到,整个图谱模式包括【学校】、【人物】、【企业】、【行业】四个实体类型,不同实体之间存在不同关系,并且给【企业】实体增加了地址属性。
步骤2:图谱构建
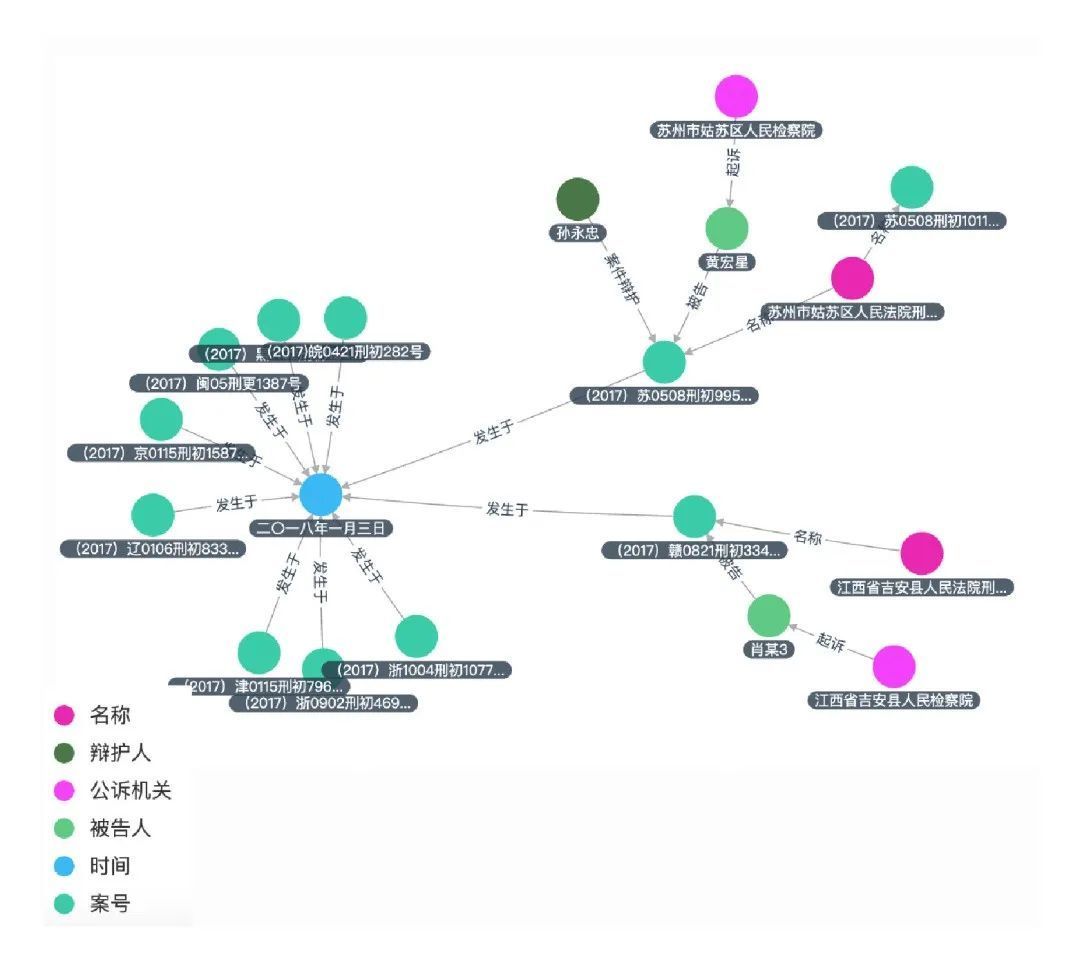
基于已定义的图谱模式,从外界数据将符合图谱模式的数据进行实例化,形成图结构的语义网络。这种图谱语义网络去冗余地表达了我们所关注的语义信息,同时提供了更直接的数据交互体验。以投融资图谱模式为例,部分实例化数据如下所示:
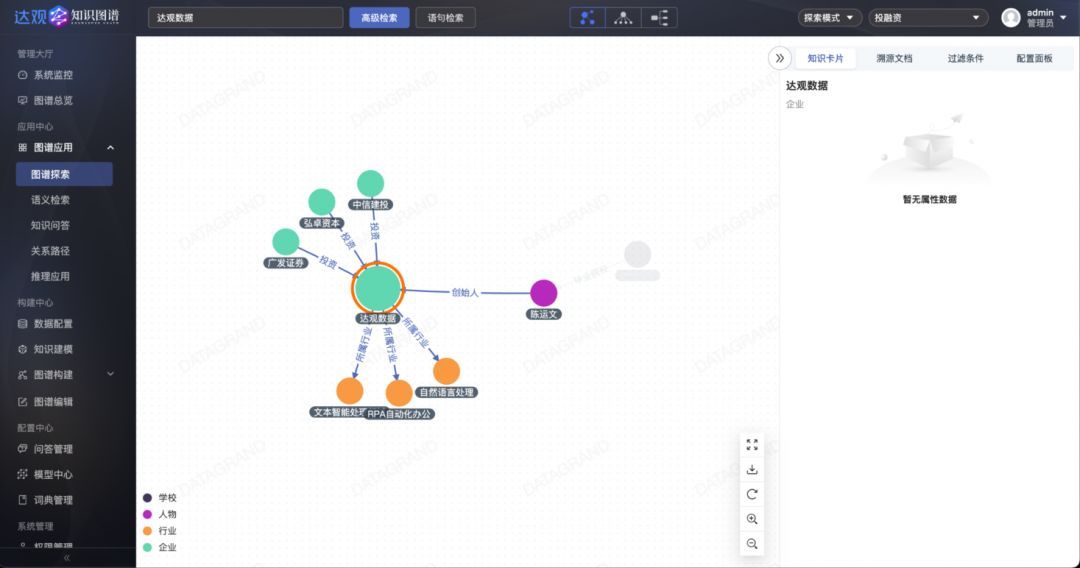
在图谱构建中,往往会面临不同类型的数据(如word、pdf、ppt、xml等),也因此给构建过程带来困难。传统的信息抽取工作,包含大量的人工参与(如样本标注、模型迭代、定制化开发等),所以对信息的抽取往往是整个图谱构建过程中最关键的一点,因此,与大模型结合的图谱构建就是为了改善图谱构建过程中的信息抽取带来的困难。
步骤3:图谱应用
图谱应用是图谱的下游环节,通常包括图谱探索、路径分析、语义检索、知识问答等基础功能,以及针对不同业务场景的定制化功能。这里是知识图谱结合大模型为业务直接赋能的环节。(也是大模型发挥更多价值的地方)。
大模型抽取
大模型与图谱构建相结合的主要应用集中在对图谱的实体和关系的抽取上。接下来介绍一些常用的大模型抽取思路和实现步骤。
一、思路介绍
大模型信息抽取目的是从非结构化文档的文本中,通过prompt输入大模型,抽取出符合图谱模式的实体、关系、属性。由于与传统信息抽取模型不同,大模型的抽取缺少显式的标注和训练迭代的过程,这导致我们需要抓住更多有关图谱的特征,用于对大模型做提示生成,确保抽取的结果能够符合图谱模式的定义。具体的抽取思路可参考下图:
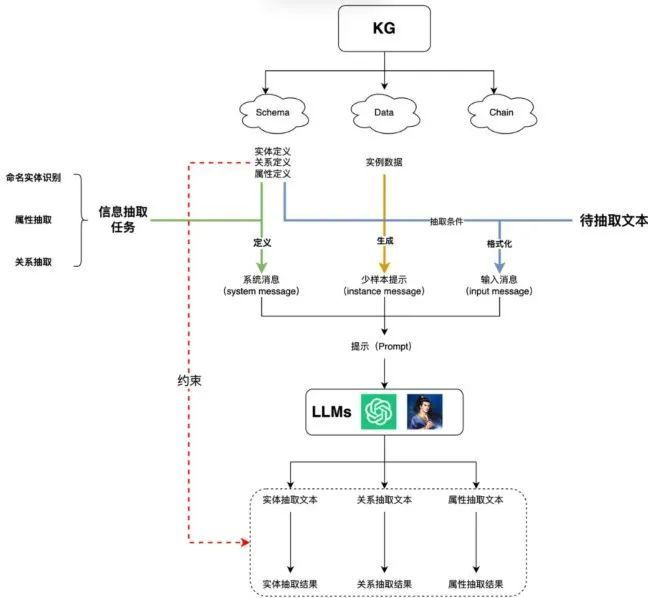 如上图所示。大模型(LLMs)&知识图谱(KG)结合在信息抽取方向的应用,主要根据两者特征进行拆解,对拆解后的特征考虑在信息抽取领域的结合方案。
如上图所示。大模型(LLMs)&知识图谱(KG)结合在信息抽取方向的应用,主要根据两者特征进行拆解,对拆解后的特征考虑在信息抽取领域的结合方案。


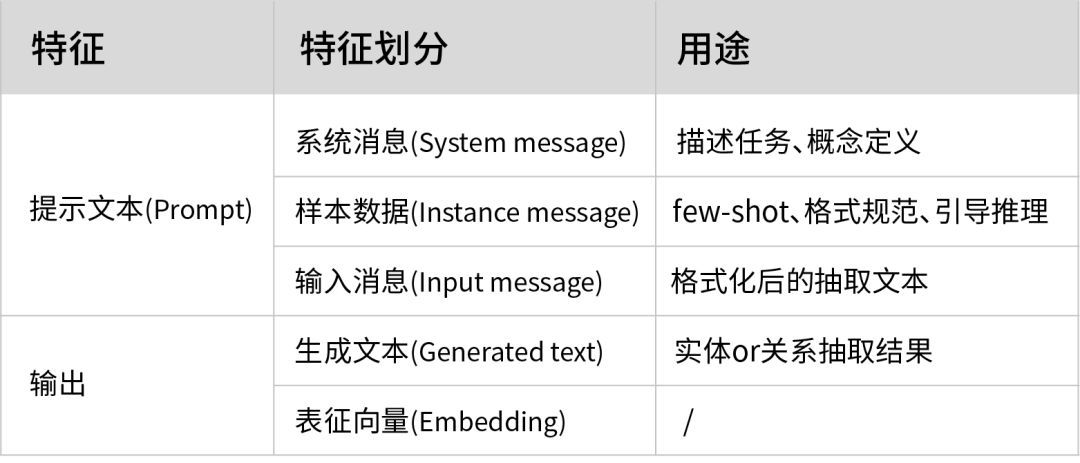
而大模型由于其黑盒性质,只能从输入和输出上进行拆解。输入即常说的Prompt和生成文本。Prompt可以由三类消息(Message)组成,分别是系统消息(System message)、少样本提示(Instance message)和输入消息(Input message)。而输出可以分为文本和向量表征(embedding),在不考虑引入其他模型的情况下,我们只需考虑输出生成文本的情况。
二、抽取步骤
1.系统消息(System Message)
这里根据图谱的Schema和抽取任务定义,对整个生成任务做背景约定,如:

上述message中描述了NER任务、任务描述以及遵循条件。
2.少样本(few-shot)提示(Instance Message)本质就是引入上下文学习(In-Context Learning,ICL)。如下例所示:

few-shot样本主要源于图谱中的标注数据,用于提供原始文本、抽取类型和抽取标签。主要用于few-shot和格式化输出。
3.输入消息(Input Message)
输入消息主要用于实例化当前的抽取任务。结合原始文本和抽取条件,生成与few-shot中相同格式的query,让大模型输出对应的抽取结果。最后,将上述消息组合成完整的Prompt,送入大模型完成相关任务。
三、输出规范与后处理
目前大模型主流训练任务是NTP(Next Token Prediction),作为概率生成模型,尽管在prompt中定义了一些约束,但是仍然会存在生成文本与实际需求不符的情况。尤其是对于图谱领域的任务,对输出的要求和限制更为明显。如实体类型不符、关系的头尾实体不在schema定义中、擅自生成不存在的关系名称等等…
在NER-RE任务的约束上,需要根据实际需求背景和图谱模式定义,引入规则或其他后处理手段,对生成文本进行抽取和校验。提取出符合图谱规范的实体或关系属性。常用的一些手段包括:
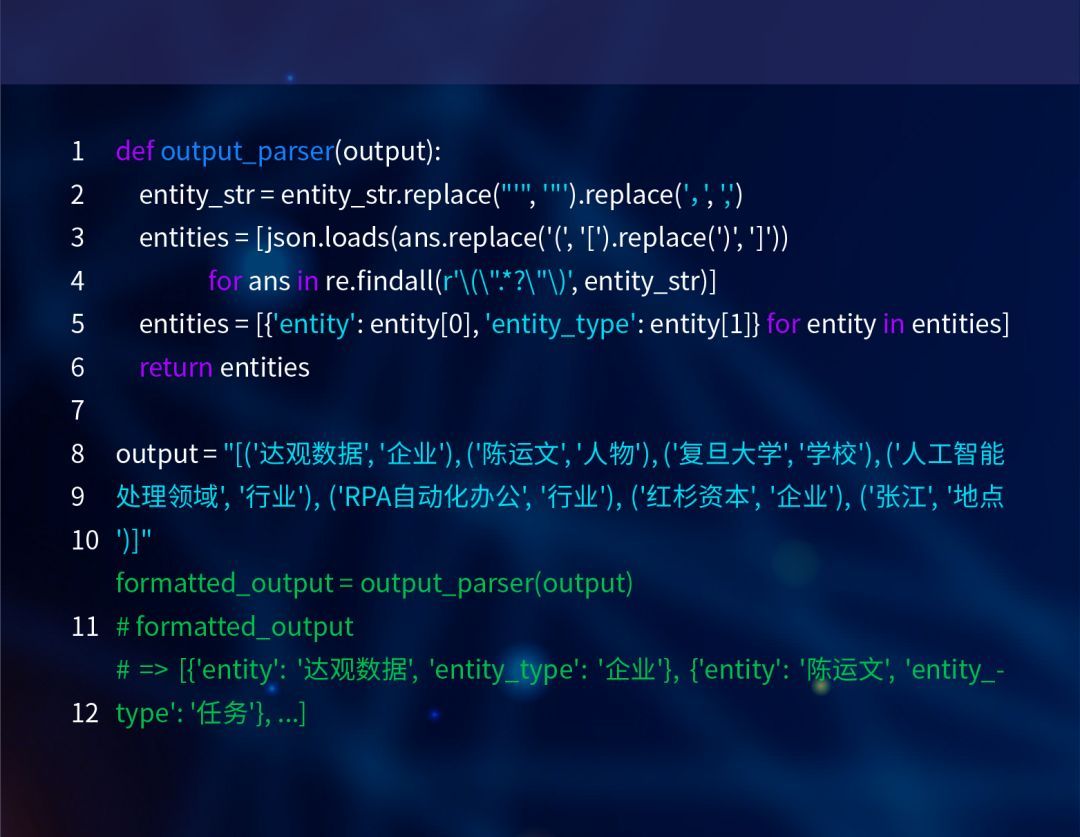
1.输出解析:我们常用的大模型接口一般以字符串(流)的形式输出结果,在信息抽取中,我们往往需要对这些字符串(流)进行解析并格式化为如json,list等数据结构。以实体抽取为例,大模型的输出为字符串变量output,经解析函数output_parser,得到格式化结果formatted_output。
2.存在性检验:基于格式化结果,我们需要对抽取出的实体是否存在于待抽取文本中进行检验,过滤掉大模型产生幻觉或擅自总结的情况(一般我们需要在prompt中做提示,尽量避免这一类情况)。
3.图谱模式校验:基于前2个步骤的输出,我们需要对抽取的结果进行进一步校验,确保每一个实体或关系三元组满足图谱模式的定义。如最终的格式化结果为:

图谱模式定义为:
我们可以看到,实体“张江”并不属于图谱中的任一实体定义(应该是实体“企业”的属性),因此需要将该实体丢弃。诸如此类的数据应当在完成基本的解析验证后,与图谱模式进行校验,保证输出的合理性。
总结
大模型信息抽取的思路来源于对抽取任务、图谱特征和大模型特征三方面的分析和结合。在不同的抽取任务中,结合当前图谱模式定义,加以少量的样本提示,实现完整的抽取提示工程,让大模型充分理解图谱的定义和需要完成的任务,输出符合的文本抽取结果。最后,通过若干后处理和校验手段,对所有结果进行验证、筛选,最终完成对非结构化文本的抽取。




