

在大数据时代,通过对目标人物的轨迹、通信、社交、出行、网络等多模态行为进行挖掘并建立人物画像模型,并依托人物基础特征和高层特征,实例化人物画像,支撑有关部门分析人员全方位了解目标人物的行为、活动、状态、基本属性等信息,同时能够基于人物画像指导人物活动规律分析、人物能力分析、人物动向分析等应用。
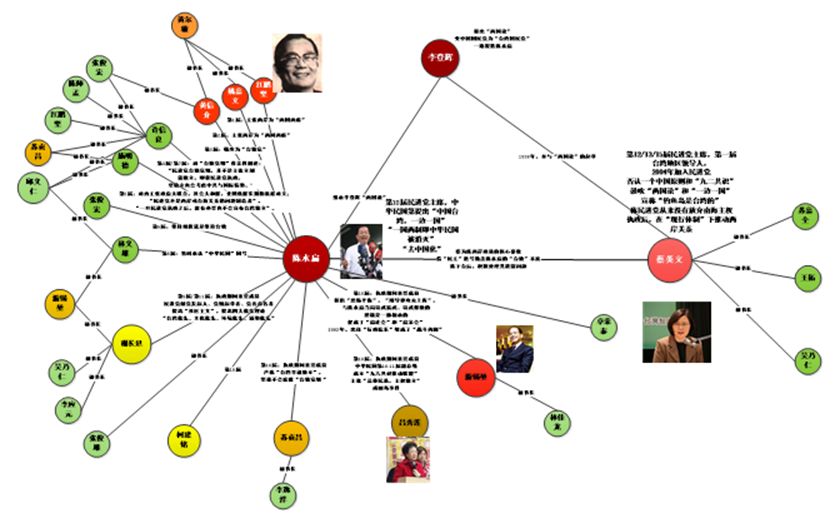
图1 某人物组织网络示例
本文将重点就人物关联关系挖掘及其关键技术进行分析。人物关联关系挖掘是网络关系挖掘中的重要一步,通过人物关联关系挖掘,可以获得关系网络中的关键结点和关键路径,进一步获取更多的人物关联关系信息。人物关联关系挖掘包括通联关系挖掘、人物群体关系挖掘、关系网络关键节点发现以及关联网络关键路径发现。

图2 人物关联关系挖掘技术结构
通联关系挖掘
通过查找选定多个人物话单人物,对多人物之间的通联关系建立网络(如图2),构建人物之间的关系网络,并计算话单人物间的亲密值权重。基于构建的关系网络可以做以下统计分析挖掘:
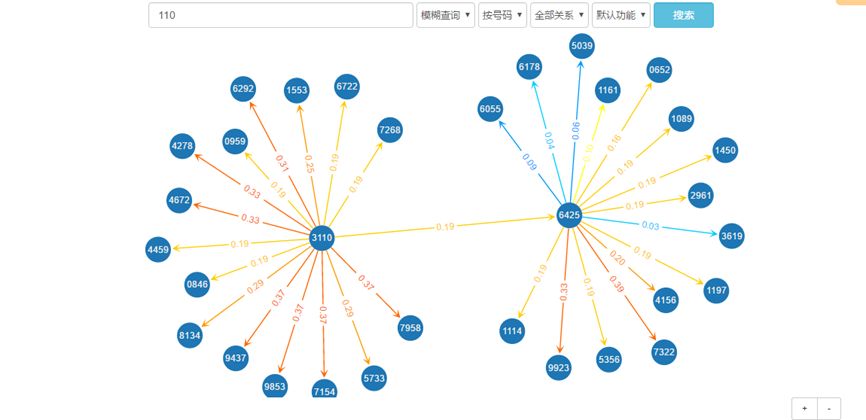
图3 多人物关系网络示意图
01关键节点发现
在构建的关系网络中,以用户为节点,通过PageRank算法量化不同粒度网络结构中不同主体的地位,发掘关系网络中的关键节点,以发现活跃及高价值人物。
02最短路径查找
在构建的关系网络中,选中两个人物,发现两个人物间的最短路径,帮助分析人员快速了解人物间的关联性。
03团体发现
在构建的关系网络中,选中多个人物,发现多人物的亲密社区。通过社区发现算法将整个网络中的人物划分成若干个群体。发现潜藏在关系网络中的未知的群体关系网络。在关系网络的关系类型、层级、强度挖掘基础之上,将利用关联分析技术,协同发现未知群体关系网络,实现关键人物的检测和群体性事件的预警与速报。
04搜索共同联系人
根据已知的多个人物人物搜索其共同联系人,从而分析人物之间的关联性,发现隐藏的关系信息。
05通联统计
选中某个人物可以查看其通讯录以及相应的统计特征,例如通联频次(分时段、收发关系)、总时长、通联关系分布、通联时段(出入度)。
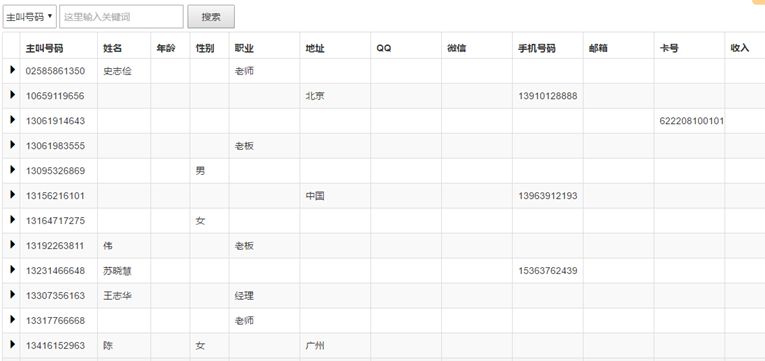
图4 短信语义分析示意图
人物群体关联关系挖掘
人物群体规律采用统计分析和关联规则发现的方法来完成规律的挖掘。
采用Aprior算法进行关联规则的挖掘。关联规则反映一个事件和其它事件之间的依赖或关联,关联规则挖掘的目的就是找出数据中隐藏的关联信息。关联可分为频繁项集关联、因果关联、时序关联、数量关联等。具体如下:
01频繁项集
通过统计得到所有对象在记录中协同出现的频次得到最常出现的k-项集。
频繁项集指的是在样本数据集中频繁出现的项的集合。如:在超市的交易系统中,记载了很多次交易,每一次交易的信息包括用户购买的商品清单。
FP-Tree算法生成频繁项集,步骤如下:
第一步:扫描事务数据库,每项商品按频数递减排序,并删除频数小于最小支持度MinSup的项。
第二步:对于每一条记录,按照第一步中的顺序重新排序。
第三步:把第二步得到的各条记录插入到FP-Tree中。
第四步:从FP-Tree中找出频繁项。
第五步:对于每一个频繁项从FP-Tree中找到所有的频繁项结点,向上遍历它的祖先结点,得到路径;对于每一条路径上的结点,其计数器都设置为当前遍历频繁项计数器的值;根据路径上结点的计数计算支持度和置信度,将大于支持度和置信度阈值的项保留,得到前件。后件即为当前遍历的频繁项。
返回到第三步,递归迭代运行,直到遍历完所有频繁项。
02因果关联
通过因果关联分析,得到事件之间的因果关系,如威胁程度为一般是阵队数量为1常在记录中同时出现,但威胁程度为一般是阵队数量为1的果。
03时序关联
通过统计得到属性取值之间时间先后情况。
04数量关联
通过Aprior算法得到数值型属性取值之间关联情况。如阵队数量的取值正相关于作战单位总数。
Aprior算法 将发现关联规则的过程分为两个步骤:
第一步通过迭代,筛选出所有频繁项集,即支持度不低于用户设定的阈值的项集;
第二步利用频繁项集构造出满足用户最小置信度的规则。
关联网络关键节点发现
关联网络关键节点发现完成知识图谱关系网络中对网络连通性和信息传播有重要影响的结点。发现信息网络中对网络连通性和信息传播有重要影响的结点。
01基于图的关键结点发现
通过计算图中结点的相关分析指标来发现图中的关键结点。
紧密中心性:图中某个结点到达其他结点的难易程度,也就是其他素有结点距离的平均值的倒数,即Cv=(|V|-1)/Σi≠vdvi。
介数中心性:图中经过某个结点的最短路径数量占总路径数量的比例,即Bv=Σi≠j,i≠v,j≠vgivj/gij。
02基于影响力的关键结点发现
如图5所示,在异构信息网络中,关键结点可能是属于某一角色。比如,在信息传播的过程中,某些结点是信息传播的起始结点,某些结点对信息传播起到推波助澜的作用,某些结点对信息传播没有任何实质性影响,对于这种情况,可以将这三类结点分别对应三种不同的角色(A、B以及C)。因此,将关键结点发现的问题转化为角色发现的问题,通过网络中结点的角色发现进而找到关键结点。给定一个网络,具有相似结构的结点属于同一角色。非监督的学习方法RolX,自动地从网络数据集中提取结构化的角色。ReFeX的优势在于,它能够处理大规模网络并且能够有效地捕捉到结点的区域性的特征。RolX大致由三个部分组成:特征提取、特征分组以及模型选择。
特征提取:ReFeX(Recursive Feature eXtraction)递归结合结点以及结点邻居的特征,然后得到结点的区域性特征。
特征分组:将具有相似结构化特征的结点分为一组。于是,我们采用软聚类方法(每个结点均具有角色分布)对结点进行聚合。对结点特征矩阵采用SVD或者非负矩阵分解近似得到矩阵,满足argminG,F ‖V-GF‖fro,s.t.G≥0,F≥0
模型选择:通过最小化ε=∑i,j(Vi,jlogVi,j/(GF)i,j-Vi,j+(GF)i,j),自动识别网络中的角色数量。
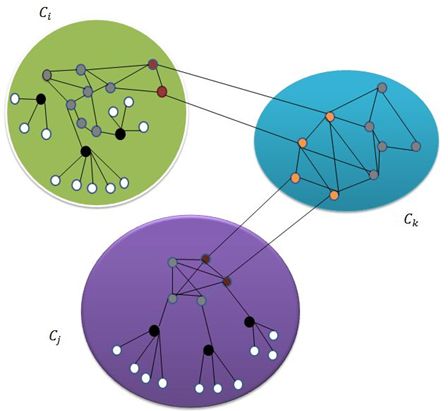
图5 结点角色结构图
03基于角色的关键结点发现
从信息传播的角度看,网络中结点的影响力越大,信息传播的速度就会越快而且范围越广。因此,可从网络重构的角度审视影响力最大化问题,将网络中关键结点发现的问题转化为最小化重构误差的问题。
DRIM(Data Reconstruction for Influence Maximization)通过影响力最大化发现网络中的关键结点。
基本定义如下:G=(V,E,T)表示当前网络, V表示顶点集合, E表示边集合, T=[ti,j]n*n表示影响力传播矩阵,其中ti,j表示影响力由结点i传播到结点j的概率,即weight(i,j)/indegree(j)。
步骤如下:
第一步:构建影响力矩阵X∈R^(N×N),其中Xi∈R^(1×N)表示结点i 对其它结点的影响力向量。结点i对结点j的影响力定义为:
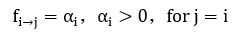
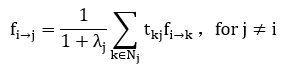
其中,Nj={j1,j2,…jm}表示结点j的邻居结点集合, αj和 λj 分别是模型的参数。由此我们可以得到结点i的影响力向量fi=[f(i→1),f(i→2),…f(i→n)],即为Xi。
第二步:从矩阵X中选择K行所代表的结点作为影响力结点。问题转化为最小化 J(A,β):
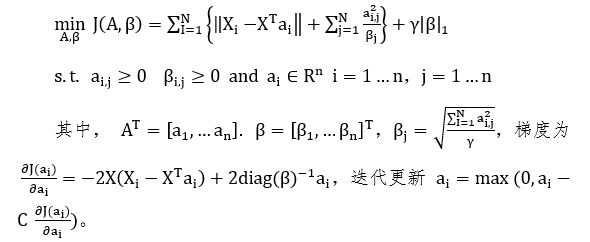
04基于节点收缩的关键节点确定
采用节点收缩方法,其原理(如图4)如下:假设Vi是网络G(V,E)中的一个节点,所谓节点收缩是指将节点Vi与其相邻节点进行融合,即用一个新节点V’i来代替融合后的节点,且与节点V’i及其邻节点相连的边转而与新节点V’i相连接,加权网络中节点收缩后如果外围节点与节点V’i及其邻节点有多条路径到达,新的连接以最短路径形式收缩。
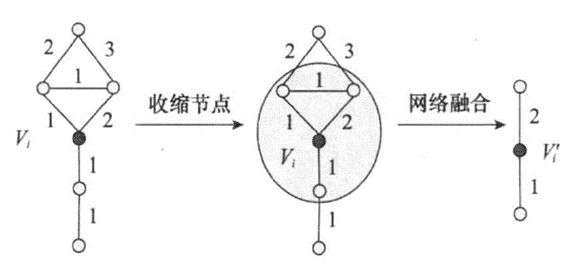
图6节点收缩原理示意图
05关联网络关键路径发现
关联网络关键路径发现完成支撑网络结构的关键路径的挖掘。
在前文角色发现的基础上,可以通过关键结点找到图中的关键路径。现假设时态网络中存在三类角色(A、B以及C),我们认为关键路径是以角色为A的结点为关键路径的初始结点,以B或者C为关键路径的终止结点的一条路径。基于上面的已知条件和假设,提出一种新的算法。已知一个时态网络图G(V,E) ,给定候选起始结点集合C和终止结点R集合,那么就可以完成斯坦纳森林的构建。通过斯坦纳森林可知,叶子结点到根结点的路径就是该图的一条关键路径。
关键路径定义:时态网络G(V,E),V是顶点集合,边集合E={(u,v,t)│u,v∈V,t∈R} 。在给定初始结点、终止结点集合的情况下,关键路径就是使得总的时间代价cost(P│R)=∑e∈Pw(e) 最小时初始结点到终止结点的路径。其中P表示时态路径集合,w(e)表示权值函数。
基于随机游走的关键路径发现:拟采用随机游走在网络中进行随机采样,研究如何设计特定的模型对样本进行统计处理与分析,并研究如何从处理后的样本中发现网络的关键路径。
基于关键结点的关键路径发现:关键结点出现在关键路径中的可能性要高于出现在非关键路径中的可能性。因此,拟借鉴上一部分对关键节点发现的探索,研究如何对某些包含关键结点的路径进行分析,并研究如何使用特定模型判断是否为关键路径。
本文小结
本文阐述的人物关联关系挖掘的技术结构主要涉及通联关系挖掘、人物群体关系挖掘、关系网络关键节点发现以及关联网络关键路径发现,可应用于相关领域大规模知识图谱自动化构建与典型应用分析,相关技术成果已经在达观渊海知识图谱平台及相关项目中陆续转化落地。
作者简介
桂洪冠,达观数据技术副总裁、联合创始人、高级工程师,中国科学技术大学计算机硕士学位,中国计算机学会CCF会员,自然语言处理技术专家,首席数据官联盟成员,苏州相城市企业家智库成员。在参与创办达观数据前,曾在腾讯文学、阿里巴巴、新浪微博等知名企业担任数据挖掘高级技术管理工作。桂洪冠在数据技术领域拥有6项国家发明专利,在大数据架构与核心算法以及文本智能处理等领域有深厚的积累和丰富的实战经验。领导构建了达观基于知识和事件分析的认知智能平台,完成了中电科集团研究所、中船重工集团研究所、深交所、华为等多个大型机构的课题项目研究和工程化落地实践。




