
自从2022年ChatGPT等智能问答系统问世以来,智能问答就以其前所未有的便捷性和智能性迅速走进了公众生活。随着智能问答技术的普及,一些挑战也逐渐浮出水面,其中最为突出的是所谓的“模型幻觉”问题。达观数据作为智能文本处理领域的领头企业,结合使用自主研发的曹植大数据模型,对智能问答系统的各个使用痛点,开发了一系列先进技术。通过这些技术,达观数据不仅解决了模型幻觉问题,还大幅提升了智能问答系统的准确性和可靠性。
事实性问题大模型出现错误
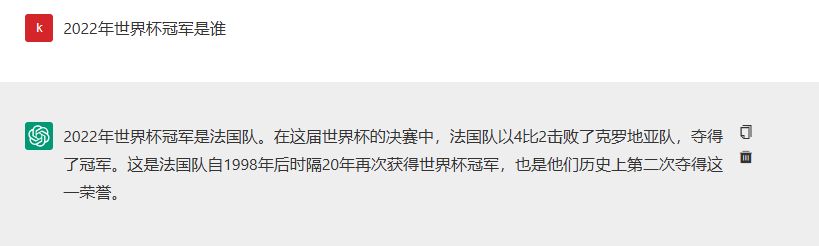
在人工智能的浪潮中,大模型凭借其强大的计算能力和海量数据的处理能力,成为了信息分析和处理的中坚力量。然而,即便是最先进的大模型,在处理事实性问题时也难免会出现错误。例如,在回答关于“2022年世界杯冠军是谁”这一问题时,如果大模型的训练语料时效性较低,就可能给出法国(2018年世界杯冠军)这样的错误答案,而2022年世界杯真实的获胜队伍是阿根廷。在大模型问答的使用过程中,错误的回答不仅会误导使用者的判断,根据错误答案生成的文件还可能带来更严重的后果。
独创原文定位技术
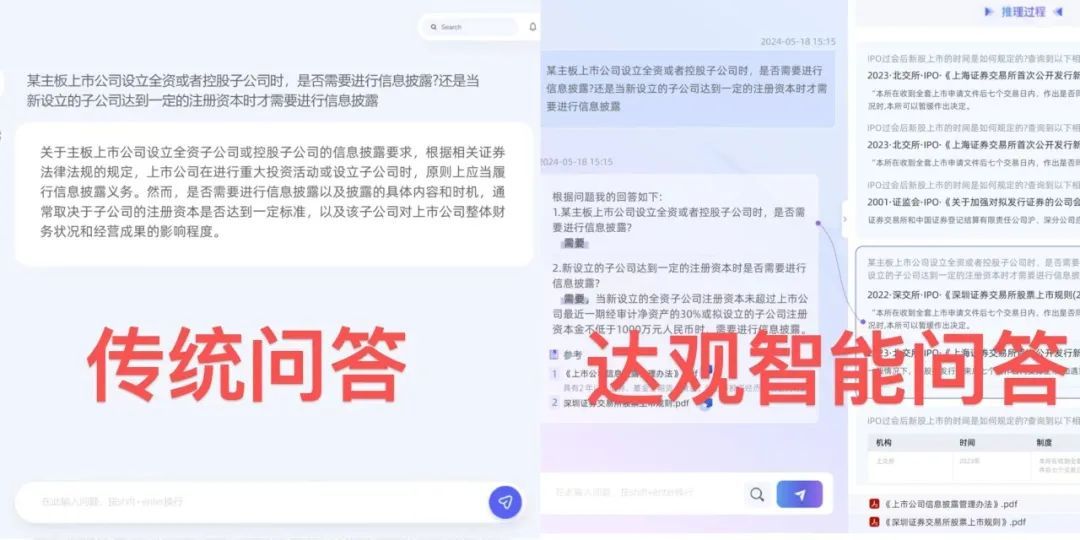
面对不同企业在垂直领域问答的专用,达观数据推出了独创的原文定位技术,对于多模态信息进行准确抽取定位。这一技术通过精确匹配和验证信息源,有效避免了事实性错误。在使用达观智能问答时,原文定位技术不仅能够自动追溯到所需文件,还能精确到文件中的具体段落中的具体句子,确保提供的信息是准确无误的,将事实性回答错误率降低了90%。达观数据的这项技术不仅提高了信息的准确性,还增强了用户对大模型输出结果的信任度,为大模型在事实性问题处理上树立了新的行业标杆。
达观智能问答创新功能
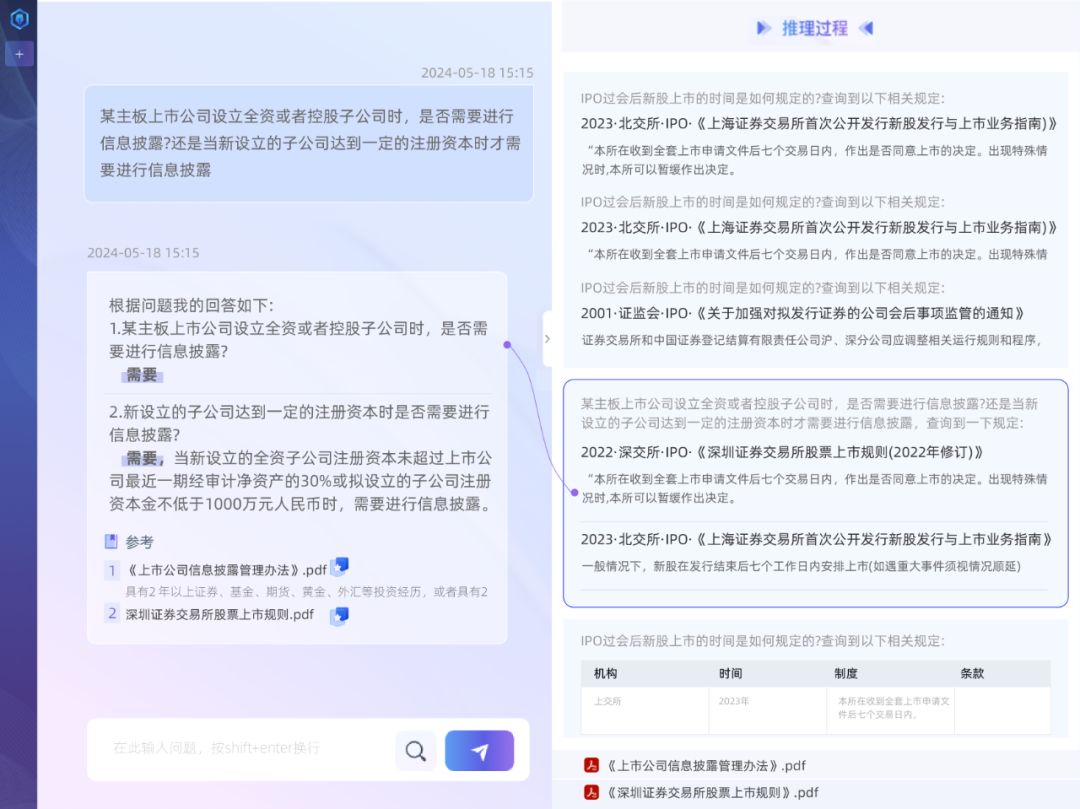
达观数据的智能问答系统通过一系列独创的先进技术,实现了对多样化信息源的高效整合与精确回答。首先,通过自适应路由应答技术能够针对不同来源和类型的问题,智能调用相应的模型进行处理,确保答案的准确性和相关性。其次,达观使用多模型混合MoE方案进行回答。通过综合不同模型的优势,显著提升了问答结果的准确率,达到30%的提升,并允许接入其他开源模型,实现答案的组合、对比和全面选择,构建了一个权威的问答库。此外,为了满足不同客户在不同终端的需求,达观数据在产品交互方式上进行了创新,通过文字、大纲、知识脑图、列表等多样化的呈现方式,提供了更加直观和个性化的用户体验。
近年来,随着人工智能技术的爆火,各个行业也逐渐推出智能化转型的口号,如何结合人工智能技术进行数字智能化转型已经是各个行业需要面对的课题。在智能化全面推动的大环境下,达观数据团队将持续升级打磨产品,基于创新技术和客户需求的双轮驱动,进一步提升产品和技术服务能力,致力于给予最适合客户的解决方案,合理高效地应用人工智能技术可以让行业工作人员快速完成业务,全面完成各行业的科技智能化建设。




