

随着互联网技术的迅速发展,尤其是移动互联网的兴起,新产生的信息呈现爆炸式的增长。为了更好地解决信息获取中的信息过载(Information Overload)和长尾问题(Long Tail),推荐系统应运而生,目前基本上已经成为了各种产品的标配功能。推荐系统是信息过滤系统的一个分支,它可以自动地挖掘用户和物品之间的联系。具体来说,它试图基于用户本身的多维度属性数据(如年龄、地域、性别等)以及行为数据的反馈(如点击、收藏、点赞、购买等),结合物品自身属性数据(如标题、标签、类别、正文等),以预测用户对待推荐物品的评分或偏好。从用户的角度来看,推荐系统是基于用户个人的兴趣偏好进行千人千面的自动推荐,则有助于缓解信息过载问题。从物品的角度来看,其自身属性及对应的交互行为差异,通过各种推荐方式是可以触达到对其更感兴趣的用户群体中,缓解了曝光不足带来的长尾问题。从企业的角度来看,推荐系统带来了更好的产品交互方式,达到了沉浸式体验的效果,从而进一步提升了用户的黏性,并最终大幅度提升了转化收益。
图1 达观智能推荐系统
在智能推荐ToB企业服务领域,达观数据已经有了10余年的推荐技术沉淀和上千家客户的行业应用实践经验。早在2012年的时候,由达观数据创始人陈运文博士带领团队参加了在伦敦举办的EMI数据黑客竞赛并获得了国际冠军,该竞赛主要是围绕音乐推荐场景,如何基于用户听歌行为等数据进行分析挖掘来对预测用户兴趣偏好并进行歌曲推荐。经过激烈鏖战,由他们开发的智能推荐系统对500万听歌用户的数据进行建模,根据每个用户的个性化兴趣偏好从数十万首歌曲库中为每个用户生成千人千面的歌曲推荐结果,推荐精度力克包括来自剑桥大学、牛津大学、密歇根大学等等的300多支参赛队伍,一举获得冠军。达观智能推荐基于前沿的人工智能和大数据分析挖掘技术,经过多年的产品打磨和持续的行业应用探索,累计服务客户数量达到了上千家。(https://www.datagrand.com/products/recommend/)
基于过滤思想的推荐方法
经过多年的推荐系统理论发展,已经产生了三代主要的推荐系统。第一代推荐系统(1995-2005),主要包括三种方法:基于内容过滤的方法、基于协同过滤的方法和混合方法,技术上主要是规则统计和机器学习。第二代推荐系统(2003-2014),主要是基于时间、位置、用户组评分等特征上下文,对这一代推荐系统的研究目前仍在进行中。第三代推荐系统的研究更侧重在基于表示学习的语义模型以及在推荐过程中会有较多的关于知识组件的使用。
01基于协同过滤的推荐方法
协同过滤方法(Collaborative Filtering,CF)是一种传统的推荐方法,体现的是群体智慧,它基于用户的兴趣偏好和与物品的历史交互行为进行推荐。这种方法可以分为基于记忆的方法和基于模型的方法。而基于记忆的方法可以分为两类:基于用户的(User-based CF)和基于物品的(Item-based CF)。基于内存的方法最流行的算法是KNN算法,该算法使用了一些传统的相似性度量,如 Pearson、Spearman、Cosine、Jaccard 等。另一方面,在基于模型的方法中,最常用的是矩阵分解(MF)及其变体(NMF、SVD)。目前,又出现了一些新的基于模型的协同过滤方法,如贝叶斯、基于聚类的、基于规则的和基于图的推荐方法。
协同过滤主要存在两个问题:当用户与物品之间的交互很少时用户数据的稀疏性,以及冷启动问题(新用户和新物品)。另外就是是传统的推荐技术没有利用推荐场景中的诸多语义信息、关键字关系和层次结构。
02基于内容过滤的推荐方法
基于该方法的推荐系统通过学习和用户过去偏好的物品在内容特征方面比较相似的新物品进行推荐。这类方法可以分为基于案例推理(case-based reasoning)和基于属性(attribute-based)的技术。基于案例推理的技术主要是推荐与用户过去喜欢的物品高度相关的物品。相比之下,基于属性的技术基于将物品属性与用户属性相匹配来进行推荐结果生成。大多数基于内容过滤的推荐系统使用的模型包括:关键字匹配或向量空间模型(VSM)、基于词频-逆文档频率(TF-IDF)加权、主题建模等。
基于内容过滤的推荐方法,推荐出来的物品具有较高的文本相关性,同时可以很好的解释推荐结果,但是推荐出来的结果往往惊喜度较差,同时文本特征较为稀疏时也会影响相关性的计算。
03基于人口统计信息过滤的推荐方法
该方法的主要思想是具有某些共同个人属性(性别、年龄、国家等)的用户也具有共同偏好这一事实。基于此,这些系统可以通过根据人口统计属性对用户进行分类来生成推荐结果。当物品的信息量很有限时,这些方法特别有用。该方法的一个优点是它不需要用户对基于内容和协同过滤方法所必需的物品进行评分或者有交互反馈。
然而,这种类型的推荐方式的主要问题,一是由于涉及安全和隐私问题,为用户收集完整的信息是不切实际的;二是该方法向相关人口统计群体的用户推荐相同的商品,个性化程度受限。
04基于上下文感知过滤的推荐方法
该类推荐系统结合场景上下文信息进行推荐。这种方法假设当前推荐场景的上下文是用一组预定义的可观察属性定义的,其结构不会随着时间的推移而发生显着变化。所谓的上下文信息主要包括时间、位置或者其他人(如朋友、亲戚或同事)。这些上下文信息为推荐结果的生成提供了额外的信息,相对于仅考虑用户或者物品自身信息,会有更多的补充。
05基于知识过滤的推荐方法
该类推荐系统主要是基于领域知识考虑如何推荐以满足用户的兴趣偏好。这些系统应该使用三种类型的知识:关于用户的知识、关于物品的知识以及关于物品与用户需求之间对应关系的知识。总体上来说,该方法主要是依靠知识图谱来为推荐系统更多的辅助信息以提升推荐精准度。后面会展开来详细介绍。
06混合过滤的推荐方法
这些系统通常将协同过滤与内容过滤或协同过滤与任何其他推荐方法相结合进行推荐。结合的目标是利用每种方法的优势以提高整体系统性能和推荐效果。目前,一些关于混合方法的工作包括基于深度学习方法、贝叶斯网络、聚类、潜在特征和图结构等等。
近年来,基于深度神经网络的方法,如 DNN 、Wide & Deep、DeepFM在排序学习(Learn to Rank,LTR)方面取得了令人瞩目的表现。这些方法遵循嵌入(Enmbedding)和多层感知机(Multilayer Perceptron,MLP)范式,其中大规模稀疏特征首先嵌入到低维向量中,然后连接在一起输入多层感知器以学习特征之间的非线性关系。先进的LTR方法发现了从用户的历史行为中提取用户兴趣以进行排名的有效性。具体来说,DIN(Deep Interest Network)使用注意力机制从用户对候选物品的历史行为中学习用户兴趣的表示。DIEN(Deep Interest Evolution Network)使用循环神经网络来捕捉用户兴趣的演变。DMT(Method Deep Multifaceted Transformers)利用多个转换器对用户的不同行为序列进行建模。
总体上来说,推荐算法是推荐系统的核心元素。基于协同过滤的推荐方式是以交互数据中用户或物品的相似性对用户兴趣偏好进行建模,而基于内容过滤的推荐方法则主要是利用物品的内容特征。基于协同过滤的推荐系统已被广泛应用,因为它们可以有效地捕获用户偏好,并且可以在多种场景中可以快速方便的实现,而无需像基于内容过滤的推荐系统中提取各种特征。然而,基于协同过滤的推荐方法存在数据稀疏和冷启动问题。为了解决这些问题,已经提出了很多类型的混合推荐系统来统一交互级相似性和内容级相似性。在这个过程中,也探索了多种类型的辅助信息,例如物品属性、评论数据、用户的社交网络等等。实践证明,混合推荐系统通常可以获得更好的推荐结果,并且近年来越来越受欢迎。
知识图谱概述
知识图谱(Knowledge Graph,KG)是一种描述实体或概念并使用不同类型的语义关系将它们连接起来的结构。2012 年,Google提出术语“知识图谱”来指代语义知识在网络搜索中的使用,目的是提高搜索引擎的能力,增强用户的搜索体验。在“知识图谱”一词流行之前,DBPedia和其他链接数据集是由语义Web技术和Berners-Lee提出的链接数据设计问题生成的。如今,KG已经在业界获得了广泛关注并进行了大规模的系统应用。
在过去的数年中,越来越多的语义数据遵循关联数据原则,通过将来自不同主题领域的各种信息(如人、书籍、音乐、电影和地理位置)连接到一个统一的全球数据空间中来发布。这些异构的数据相互联系,形成了一个巨大的信息资源库,称为知识库。已经构建了几个典型的知识库,包括YAGO、NELL、DBpedia、DeepDive等学术项目,以及微软的Satori、谷歌的Knowledge Graph等商业项目。使用来自知识库的异构连接信息有助于深入了解单个领域的数据难以发现的问题。
以下是部分知识库介绍:
- Freebase是一个非常实用的并且可拓展的元组数据库系统,旨在成为世界知识的公共存储库。它的设计灵感来自广泛使用的信息社区,如语义网和维基百科。Freebase 中的数据是结构化的,通过协作创建的方式生成。它支持高度多样化和异构的数据,并具有高可扩展性。Freebase 目前包含125000000+ 元组、4000+类型和 7000+属性。MQL (Metaweb Query Language)作为一种对数据执行查询和操作的语言,通过基于HTTP协议的图查询(graph-query)API可以实现对Freebase的读写操作。MQL为Freebase中的元组数据提供了易于使用的面向对象的接口,它的产生旨在促进通过协作方式创建基于 Web 的面向数据的应用程序。
- DBpedia是从111种语言的维基百科版本中提取结构化数据来构建的一个大规模多语言知识库。从英文版维基百科中抽取的最大DBpedia知识库包含4亿多条事实数据,用于描述370万种事物。从其它的110个维基百科版本中抽取的DBpedia知识库总共包含14.6亿事实数据,描述1000万种额外事物。DBpedia将27种不同语言版本的维基百科信息框(infoboxes)映射到一个单一的共享本体中,该本体由320个类和1650 个属性组成。这些映射是通过世界范围内的众包工作创建的,从而可以很好的融合来自不同维基百科版本的知识。该项目定期发布所有DBpedia知识库以供下载,并通过本地DBpedia章节的全球网络提供对111种语言版本中的14 种语言版本的SPARQL查询访问。除了定期发布之外,该项目还维护一个实时知识库,该知识库会在维基百科中的页面发生更改时进行更新。DBpedia设置了2700万个RDF链接,指向30多个外部数据源,从而使来自这些源的数据能够与DBpedia数据一起使用。
- YAGO是由德国马普研究所研制的链接数据库。YAGO主要集成了Wikipedia、WordNet和GeoNames三个来源的数据。YAGO建立在实体和关系之上,目前包含超过 100 万个实体和 500 万个事实,1.2亿条三元组知识,包括 Is-A 层次结构以及实体之间的非分类关系,事实已自动从Wikipedia中提取并与 WordNet统一。YAGO将WordNet的词汇定义与Wikipedia的分类体系进行了融合集成,使得YAGO具有更加丰富的实体分类体系。YAGO还考虑了时间和空间知识,为很多知识条目增加了时间和空间维度的属性描述。
知识图谱本质上是一种基于图的数据结构,是一种揭示实体之间关系的语义网络。通俗来讲,就是把不同种类的信息连接在一起得到的一个语义关系网,知识图谱以结构化的方式描述客观世界,沉淀背景知识,将信息知识表示成更接近人类认识世界的形式,已经被广泛应用于搜索引擎、智能推荐、智能问答、语言理解、决策分析等领域。
图2 达观知识图谱功能展示
达观知识图谱,是达观数据公司面向各行业知识图谱应用而推出的新一代产品,其整合了知识图谱的设计、构建、编辑、管理、应用等全生命周期实现,基于客户的多源异构数据整合构建知识中台,可以实现从业务场景出发到生成图谱、再到实现基于图谱的应用,显著提高了各行业中知识图谱的落地效率和效果。
知识图谱和推荐系统
传统的推荐系统更多的是将用户和物品之间的显式或隐式反馈作为输入,这带来了两个问题:
- 在实际场景中,用户和物品之间的交互信息特别稀疏。例如,一个在线购物应用可能包含数十万的商品,而用户实际购买的商品数量可能仅有数百。使用如此少量的行为反馈数据来预测大量未知信息会显着增加算法过拟合的风险。
- 对于新用户和新物品的推荐,由于缺乏历史交互信息,系统推荐的精准度就会受到极大的负面影响。解决稀疏性和冷启动问题的一种常见方法是在推荐算法的输入中引入额外的辅助信息,例如用户属性、项目属性和上下文信息等等。
近年来,将知识图谱作为辅助信息引入推荐系统已经成为了工业界和学术界的研究热点。KG一方面可以提供丰富的领域知识作为补充信息来克服协同过滤和基于内容过滤的推荐方法所面临的问题;另一方面,推荐系统可以使用 KG 中存在的语义关系来提高其准确性并增加推荐物品的多样性。具体来说,KG 推荐利用了代表用户的实体、要推荐的物品及其交互之间的联系。推荐系统使用各种连接来识别目标用户可能感兴趣的物品集合。因此,复杂的关系表示为基于KG的推荐系统提供了额外的有价值的信息,以在节点之间应用推理来发现新的连接。相反,一般来说,基于特征向量的经典推荐方法会忽略这种连接,这可能会导致整体的推荐性能欠佳,尤其是在数据稀疏的情况下。
融入知识图谱的推荐系统
KG是一个异质图,节点表示实体,边缘表示实体之间的关系。物品及其属性可以映射到 KG 中,以表征物品之间的相互关系。此外,用户及其信息也可以集成到KG中,这就使得用户和物品之间的关系以及用户偏好可以更准确地捕获。
一般来说,基于KG的推荐方法,第一步需要构建KG,可以是物品知识图谱(Item Knowledge Graph,IKG),也可以是用户物品知识图谱(User-Item Knowledge Graph,UIKG)。
- 关于IKG。在IKG中,物品和他们关联的实体(如物品属性)作为节点,而边可以表示物品的属性级关系(如品牌、类别等),也可以表示为用户相关的关系(如“都浏览”、“都购买”)。
- 关于UIKG。在UIKG中,用户、物品和他们相关的实体都是节点,边可以表示用户和物品之间的关系(如点击、收藏、购买等)。
以IKG的构建为例,物品首先映射到外部 KG 以找到它们的关联实体,然后从 KG 中提取关联实体的多跳邻居,并形成推荐系统的子图。当然也可以不需要依赖外部KG,可以基于所提供的数据中的辅助信息来构建KG。
可解释的推荐系统是近年来的另一个热门研究方向。一方面,在推荐结果呈现的实现如果可以向用户提供适当的推荐解释,则用户可以相对更好地接受推荐结果。另一方面,也可以更深入地了解推荐算法。与传统的推荐系统相比,基于知识图谱的推荐系统呈现了连接用户和物品的多种实体和关系,并且能够很好地展示推理过程。
基于知识图谱的推荐方法,按照如何应用知识图谱数据,可以分为三类,分别是基于嵌入的方法、基于连接的方法和基于传播的方法。
01基于嵌入的方法
基于嵌入(Enbedding-based)的方法主要思想是使用KG中大量的事实知识来进一步地丰富用户和物品的多维度表示,其中主要包括两大基础模块,一个是图嵌入模块,用于学习KG中实体和关系的表示,也就是需要应用知识图嵌入(Knowledge Graph Embedding,KGE)算法将KG编码为低秩嵌入,KGE算法可以分为两类:平移距离模型,如TransE、TransH、TransR、TransD等,以及语义匹配模型,如 DistMult。
另外一个是推荐模块,基于学习到的特征用于预测用户对物品的偏好。基于这两个模块在整个推荐框架中的关联方式的差异,基于嵌入的方法可以进一步细分为两阶段学习的方法、联合学习的方法和多任务学习的方法。该类方法面临的挑战包括如何使用合适的KGE方法以获得实体的嵌入表示以及如何将学习到的实体嵌入表示集成到推荐模块中。
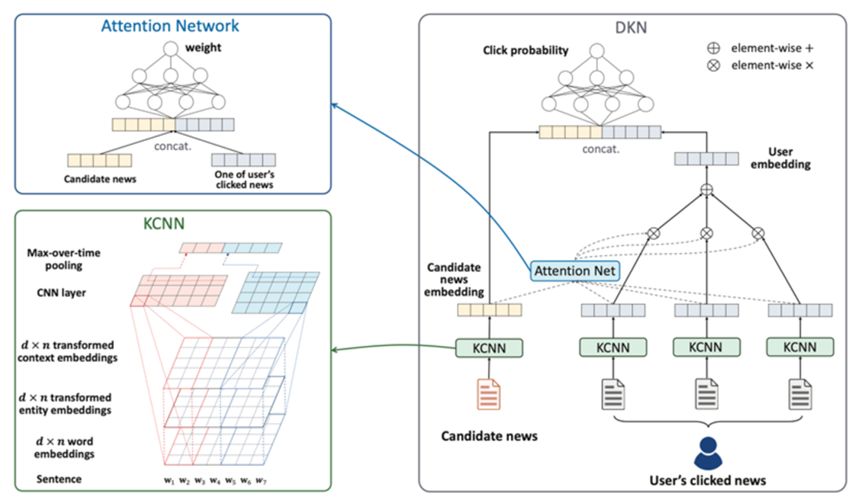
图3 DKN框架
(1)两阶段学习方法
两阶段学习方法是指分别对图嵌入模块和推荐模块进行训练。第一步,使用KGE算法学习实体和关系的嵌入表示,接着,将预训练好的图相关嵌入连同其它的用户特征和物品特征输入到推荐模型进行用户兴趣预测。图3是用于新闻推荐的DKN(Deep Knowledge-aware Network)两阶段学习框架图。在第一阶段,提取新闻标题中的实体并将其映射到 Satori KG以挖掘新闻之间的知识级关系。DKN 通过将用KCNN学习到的句子的文本嵌入表示和通过TransD将新闻内容中的实体的知识级嵌入二者结合来对新闻进行建模。为了捕捉用户对新闻的动态兴趣,通过引入注意力机制,聚合用户的历史点击新闻的嵌入来学习用户的表示。
两阶段学习方法易于实现,其中 KG 嵌入通常被视为后续推荐模块的额外特征。另一个好处是可以在没有交互数据的情况下学习 KG 嵌入,因此,大规模交互数据集不会增加计算复杂度。此外,由于KG通常是稳定的,一旦学习好了嵌入表示,就没有必要频繁更新嵌入表示。但是,通过 KGE 模型优化的实体嵌入更适合于图内应用,例如 KG补全。由于 KGE 模块和推荐模块是松耦合的,因此学习到的嵌入也可能不适合后续的推荐任务。
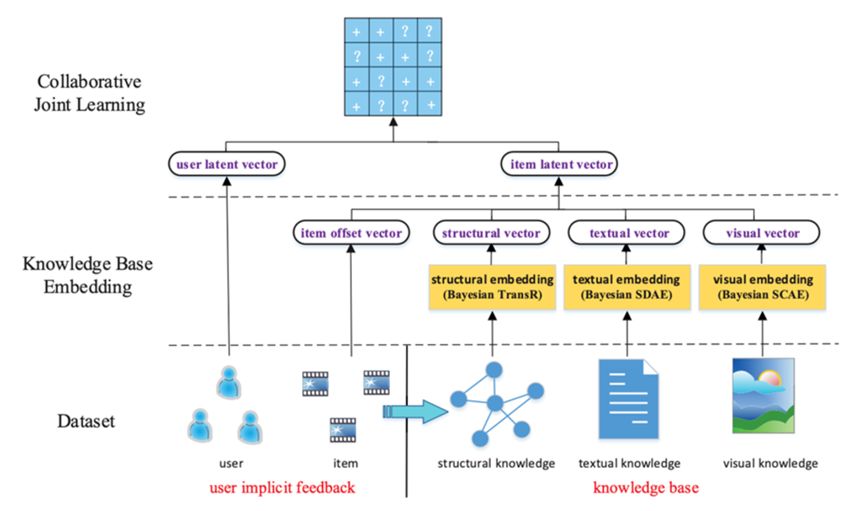
图4 CKE推荐系统流程
(2)联合学习法
另一个趋势是以端到端(end-to-end)的训练方式联合学习(Joint Learning)图嵌入模块和推荐模块。这样,推荐模块可以指导图嵌入模块中的特征学习过程。CKE(Collaborative Knowledge Base Embedding)统一CF框架中的各种类型的辅助信息,包括物品的属性级特征、文本特征和视觉特征。属性级特征用TransR编码以从KG中学习结构知识,而文本特征和视觉特征用自动编码器进行提取。这三个特征学习模块的目标函数加上推荐模块共同学习模型参数。
联合学习方法可以进行端到端的训练,并且可以使用 KG 结构对推荐系统进行正则化。然而,在实际应用过程中,需要对不同目标函数的组合进行微调。
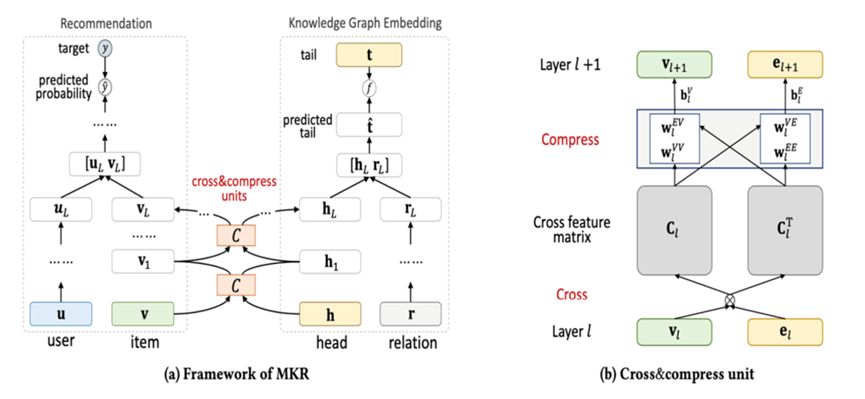
图5 MKR框架及交叉压缩单元示例
(3)多任务学习法
最近的一个研究方向是采用多任务学习(Multi-Task Learning)的策略,在KG相关任务的指导下训练推荐任务。动机是用户-物品交互二分图中的物品及其在 KG 中的关联实体可能共享相似的结构。因此,物品和实体之间低级特征的转移有助于促进推荐系统的改进。MKR(Multi-task feature learning approach for Knowledge graph enhanced Recommendation)由一个推荐模块和一个KGE模块组成。这两个模块不是将 KG 嵌入输入到推荐模块中,而是独立的,并通过交叉压缩单元进行连接以共享知识。推荐模块被训练以估计用户对候选物品的偏好,而KGE模块被训练来估计给定头部实体和三元组中的尾部实体表示。具体来说,推荐模块基于MLP以获得最终用户表示。最终的物品表示由L层交叉压缩单元及其在KG中的相关实体来进行细化。使用非线性函数估计用户对候选物品的偏好程度。
通过应用多任务学习策略,有助于防止推荐系统过拟合,提高模型的泛化能力。然而,与联合学习方法类似,它需要努力在一个框架下集成不同的任务。
综上,尽管两阶段学习方法易于实现,但学习到的实体嵌入可能不适合推荐任务,联合学习方法通过端到端训练学习优化的实体嵌入,多任务学习方法通过从KG相关任务中转移知识进一步提高模型的泛化能力。但是,它需要大量的实验来找到不同目标函数的最佳组合。
02基于连接的方法
基于连接(Connection-based)的方法利用图中的连接模式来指导推荐。相关的大多数工作都使用UIKG来挖掘图中实体之间的关系。探索KG中的连接信息有两种主要方法。第一个方向是利用图中的元结构,包括元路径和元图,来计算实体之间的相似度。基于元结构的相似性可以作为用户和物品表示的约束,也可以用于预测用户对交互历史中相似用户或相似物品的兴趣偏好。第二种解决方案是将用户-物品对或物品-物品对之间的连接模式编码为向量,可以集成到推荐框架中。这种方法也叫基于路径嵌入的方法。这种方法的挑战包括:1)如何为不同的任务设计合适的元路径;2)如何对实体之间的连接模式进行建模。
(1)基于元结构的方法
基于元结构(Meta-structure based)的方法的一种实现是利用不同元路径中实体的连接相似性作为图谱正则化项来约束用户和物品的表示。其动机是基于元路径的实体相似度越高,则在潜在空间中越接近。
目标函数如式(1)所示:

其中LRec表示推荐系统的目标函数,常见的选择是矩阵分解。相似性约束LSim指导用户嵌入和物品嵌入的学习。为了度量图中实体之间的连接相似性,通常使用PathSim, 如式(2)所示:
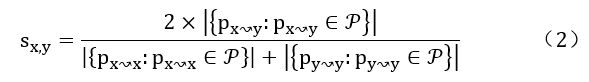
其中Pm~n是实体m和n之间的一条路径。通常使用三种类型的实体相似性,具体如下:(a)用户-用户相似度,目标函数如式(3)所示:

其中||Ui-Uj||F表示矩阵 Frobenius 范数, ɵ=[ɵ1,ɵ2,…..ɵL]表示每个元路径的权重,U=[u1,u2,…,um]表示所有用户的潜在向量,S[1-(i,j)]表示用户i和j在元路径中的相似度得分。如果用户共享基于元路径的高相似性,则用户-用户相似性会迫使用户的嵌入在潜在空间中接近。
(b)物品-物品相似度,目标函数如式(4)所示:
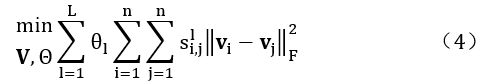
其中 V=[v1,v2,…,vn]表示所有物品的潜在向量.与用户-用户相似度类似,如果物品的基于元路径的相似度很高,则物品的低秩表示应该是接近的。
(c)用户-物品相似度,目标函数如式(5)所示:
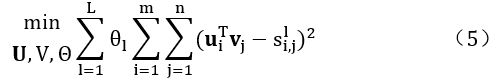
如果基于元路径的相似度很高,则用户-物品相似度项将迫使用户和物品的潜在向量彼此接近。
除了以上三种相似度的方法以外,基于元结构的方法也可以利用实体相似度来预测用户对未评分物品的兴趣,这可以作是KG中的偏好融合。
综上,上述方法首先从交互矩阵及其基于元结构的相互相似性中学习用户和物品的潜在向量,然后基于增强的表示进行预测。也可以直接使用相似用户评分的加权集合来预测对未评分项目的偏好。基于元结构的方法是可以解释的,因为这些手动设计的元结构通过匹配候选物品与交互物品或目标用户之间的元结构来为推荐系统提供更多参考信息。
基于元结构的方法易于实现,大多数工作都是基于模型复杂度相对较低的MF技术。然而,元路径或元图的选择需要领域知识,并且这些元结构对于不同的数据集可能会有很大差异。此外,在某些特定场景下可能不适合应用基于元结构的方法。例如,在新闻推荐任务中,属于一个新闻的实体可能属于不同的域,这使得元路径设计变得困难。
(2)基于路径嵌入的方法
基于元结构的方法的一个问题是连接模式没有明确建模,这使得很难学习用户-物品对和连接模式之间的相互影响。但是,基于路径嵌入的方法可以显式地学习连接模式的嵌入。通过学习连接UIKG中的用户-物品对或IKG 中的物品-物品对的路径的显式嵌入,以便直接建模用户-物品或物品-物品关系。以UIKG中的关系建模为例,假设KG中有K条连接ui和Vj的路径,路径p的嵌入表示为hp,则可以通过式(6)获得ui和Vj之间交互的最终表示:
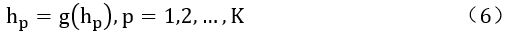
其中g(∙)是从每个路径嵌入中汇总信息的函数,常见的选择是最大池化操作或加权求和操作。然后,ui和Vj的偏好可以通过式(7)建模:

其中f(∙)是映射用户-物品对之间的交互表示以及用户-物品对嵌入到偏好分数的函数。
推荐结果可以通过检查每个元路径的权重来解释。较高的元路径权重意味着目标用户和候选物品之间的这种关系在做出决策时更重要。
基于路径嵌入的方法将用户-物品对或物品-物品对的连接模式编码为潜在向量,从而可以考虑目标用户、候选物品和连接模式的相互影响.此外,大多数模型能够通过计算合适的路径并选择显著路径来自动挖掘连接模式,而无需预定义的元结构的帮助。因此,它很可能捕捉到富有表现力的连接模式。但是,如果图中的关系很复杂,则图中可能的路径数量可能会增长到很大。随意实际上,不可能利用大规模 KG 中每个实体对的所有路径,这可能会阻碍模型的性能。
综上,基于连接的方法在很大程度上依赖于连接模式。但是元路径的表示能力是有限的,这阻碍了传统的基于元结构的方法的性能。基于路径嵌入的方法进一步克服了基于元结构的方法的另一个缺点,即需要领域知识和人工配置路径。这些方法枚举可能的路径并显式建模用户-物品对或物品-物品对之间的关系。然而,基于路径嵌入的方法在一定程度上牺牲了可扩展性,因为这些模型相对复杂,在枚举路径和学习表示时需要更多的计算。
03基于传播的方法
基于嵌入的方法利用知识图谱中的语义关系来丰富用户和物品的表示,但难以捕捉实体之间的高阶关系。基于连接的方法使用图中的连接信息来指导推荐,但是,通过将复杂的用户物品连接模式分解为单独的线性路径,不可避免地会丢失信息。为了充分利用 KG 中的信息,基于传播的方法集成实体和关系的表示以及高阶连接模式,以实现更个性化的推荐。基于传播的方法的主要想法是嵌入传播,其中常见的实现方式是基于 GNN 技术。这些方法通过聚合KG 中多跳邻居的嵌入表示来细化实体表示。然后,可以使用用户和潜在项目的丰富表示来预测用户的偏好。
根据在消息传播过程中细化的实体类型产的差异可以进一步的进行细分为三类。这种方法的挑战包括:
- 如何为不同的邻居分配适当的权重
- 如何在不同的关系边上传播消息
- 如何提高模型的可扩展性
(1)用户嵌入表示的细化
根据用户的交互历史细化用户嵌入表示。先是构建IKG使用多个关系将交互物品和候选物品连接起来。则用户可以表示为他们交互物品及其多跳邻居的组合。具体来说,交互历史中的物品被选为传播过程的种子。然后,沿图中的链接提取多跳三元组集合S[k-ui](k=1,2,…,H),其中S[1-ui]是三元组集(eh,r,et),头部实体是用户ui的交互过的物品列表。学习用户表示ui的过程可以表述为如下两步:
(a)通过聚合三元组集合S[k-ui](k=1,2,…,H)的每一层中的实体来计算用户的嵌入表示o[k-u]。
(b)合并o[k-u](k=1,2,…,H),得到最终的用户嵌入表示ou。
由于传播过程是从用户交互过的物品开始,到远邻结束,这个过程可以看作是在IKG中逐层向外传播用户的偏好。因此,这些方法可以解释为沿着 KG 中的路径从历史兴趣中传播用户的偏好。
在这些方法中,边权重在IKG 中是明确的。因此,可以选择连接候选物品和交互项目的显著路径,并作为推荐结果的解释。尽管这些工作同时利用了实体嵌入和高阶连接信息,但只有用户嵌入表示在传播过程中得到更新。
(2)物品表示的细化
上面介绍了通过在图中向外聚合实体来优化用户嵌入表示。另一种方式是通过聚合项目Vj的多跳邻居N[k-u](k=1,2,…,H)在IKG中向内的嵌入表示来学习候选物品Vj的高阶表示。在向内传播过程中,采用图注意力机制,其中不同邻居的权重是由用户和关系来确定的。主要是考虑到用户对不同的关系是有不同的偏好的,从而可以确定KG的信息流。
每一轮传播过程表示为如下两步:
(a)通过式(8)聚合实体ei的近邻:
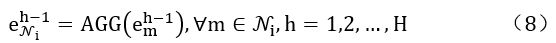
(b)使用h—1阶邻居嵌入和自嵌入更新实体的h阶表示,如式(9)所示:
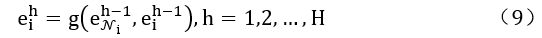
其中e[0-i]代表实体的初始表示,e[h-i]代表实体的h阶表示,它是实体初始表示和来自h跳邻居的表示的混合。聚合函数将N个邻居映射到向量∈Rd,更新函数g(∙)是一个非线性函数:Rd ⨉ Rd → Rd。通过迭代地重复这个过程H次,候选物品的表示则包含了来自H跳邻居的信息。
综上,通过IKG中的向内传播来细化物品的嵌入表示。然而,类似于在 KG 中向外聚合的用户细化,只有一种类型的实体被细化。
(3)用户和物品表示的细化
在UIKG中的传播过程中,用户、物品及其关联实体都连接在一个图中,用户-物品对之间的交互作为一种关系。用户嵌入和物品嵌入可以在传播过程中使用其对应的邻居进行细化,如式 (8) 和 (9) 所示。
与IKG中的传播类似,UIKG中边的权重也是由用户确定的。因此,这些模型可以通过检查连接目标用户和候选物品的显著路径来为推荐结果提供解释。由于用户被合并为一种类型的节点,因此解释更加直观,因为每个交互物品的贡献都是可用的。通过将用户纳入KG,可以更大程度地探索高阶连接模式。缺点是图中的关系越多,会带来不相关的实体,可能会误导用户在聚合过程中的偏好。
综上,基于传播的方法通常计算成本高。随着图变大,模型变得难以收敛。为了提高效率,可以使用更快的图卷积运算,并且通常在每一层中应用邻域采样。但是,随机抽样不可避免地会导致信息丢失,无法充分挖掘图中的知识。
04基于KG的推荐方法总结
通过上述基于嵌入方法、基于连接方法和基于传播方法的介绍,可知基于嵌入的方法是最灵活的方法。一方面,使用KGE模块对KG进行编码相对容易,并且学习到的嵌入可以自然地融入到用户表示或项目表示中。而在基于连接的方法中,在图中定义元路径或元图可能很繁琐。对于基于传播的方法,需要仔细设计聚合和更新部分。另一方面,基于嵌入的方法适用于大多数应用场景,因为外部知识通常在不同的任务中可用。相反,在基于元结构的方法中,元路径对于不同的应用场景通常是多种多样的,并且不能泛化到新的数据集。此外,对于特定场景,如新闻推荐,很难定义元路径并应用基于元结构的方法。同时,基于路径嵌入的方法和基于传播的方法都不适用于具有大规模数据集的推荐场景,因为在枚举路径和邻居时计算复杂度可能会变得很大。此外,路径的质量和数量对于基于连接的方法至关重要,因此,稀疏数据集可能无法提供足够的路径来挖掘此类方法的关系和模型兴趣。然而,基于嵌入的方法和基于连接的方法都未能充分探索KG中的信息。近年来,随着GNN技术的发展,基于传播的方法已成为一种新的研究趋势。此外,基于连接的方法和基于传播的方法都可以用KG中的路径来解释,而基于嵌入的方法解释起来不太直观。
基于KG推荐的可解释性
KG中包含有大量的辅助信息可以用于推荐结果的解释,主要有以下几种方法:
01关系嵌入的注意机制
这种方法主要应用于基于嵌入的方法。注意力机制应用于KG中实体之间关系的嵌入。从不同关系的注意力权重,可以得到每类物品属性对目标用户的意义。因此,这种技术可以为推荐提供偏好级别的解释。
02定义元路径或者元图
所选物品与目标用户或交互物品之间的关系可以分解为若干元路径或元图的组合。通过将元路径或元图转换为可理解的规则,系统可以提供解释。
03路径嵌入的注意机制
对于路径嵌入方法,连接目标用户和候选物品的特定路径的权重可通过注意力机制获得。每条路径的权重可以代表每条路径对用户的相对重要性。因此,可以根据图中的显著路径来提供解释。
04UIKG中的强化学习
通过使用强化学习技术在UIKG中训练代理,可以挖掘连接用户物品对的实际路径。它可以直接显示KG中的推理过程,而不是为已经选择的推荐结果寻找事后解释。因此,推理过程对于目标用户来说是精确且值得信赖的。
05提取边缘权重
基于传播的方法需要在聚合过程中为每种类型的邻居分配用户特定的权重。边权重控制图中实体之间的信息流,可以反映KG中每种关系的重要性。此外,KG中实体之间的边权重也可以从注意力权重或学习关系矩阵中获得。因此,可以通过找到连接候选物品和目标用户的显著路径或多跳邻居中的交互物品来生成解释。
未来展望
通过前面的介绍可以知道,基于KG的推荐系统在推荐精准度和推荐结果可解释性方面具有诸多优势。在学术界和工业界也已经提出了很好的模型以充分利用KG中的辅助信息进行个性化精准推荐。但是在一些方向上依然还有很多工作值得深入研究,主要体现在:
01 动态推荐
尽管具有GNN或GCN架构的基于KG的推荐系统取得了良好的性能,但训练过程非常耗时。因此这样的模型可以被视为静态偏好推荐。然而,在某些场景下,例如在线购物、新闻推荐等,用户的兴趣会很快受到社交事件等的影响。在这种情况下,使用静态偏好建模的推荐可能不足以理解实时兴趣。为了捕捉动态偏好,利用动态图网络可能是一种解决方案。
02 跨域推荐
在跨领域推荐的也有一些研究进展,主要是交互数据在各个领域是不平衡的。例如,在亚马逊平台上,图书子集大于其他域。通过迁移学习技术,可以共享来自具有相对丰富数据的源域的交互数据,以便在目标域中进行更好的推荐。
03 知识增强语言表示
为了提高各种 NLP 任务的性能,有一种趋势是将外部知识集成到语言表示模型中,使知识表示和文本表示可以相互提炼。将知识增强文本表示策略应用于基于文本的推荐任务中,可以更好地进行表示学习,以提供更准确的推荐。
参考文献
[1] Bollacker K, Evans C, Paritosh P, et al. Freebase: a collaboratively created graph database for structuring human knowledge[C]//Proceedings of the 2008 ACM SIGMOD international conference on Management of data. 2008: 1247-1250.
[2] Lehmann J, Isele R, Jakob M, et al. Dbpedia–a large-scale, multilingual knowledge base extracted from wikipedia[J]. Semantic web, 2015, 6(2): 167-195.[3] Suchanek F M, Kasneci G, Weikum G. Yago: a core of semantic knowledge[C]//Proceedings of the 16th international conference on World Wide Web. 2007: 697-706.
[4] Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data[J]. Advances in neural information processing systems, 2013, 26.
[5] Wang Z, Zhang J, Feng J, et al. Knowledge graph embedding by translating on hyperplanes[C]//Proceedings of the AAAI conference on artificial intelligence. 2014, 28(1).
[6] Lin Y, Liu Z, Sun M, et al. Learning entity and relation embeddings for knowledge graph completion[C]//Twenty-ninth AAAI conference on artificial intelligence. 2015.
[7] Ji G, He S, Xu L, et al. Knowledge graph embedding via dynamic mapping matrix[C]//Proceedings of the 53rd annual meeting of the association for computational linguistics and the 7th international joint conference on natural language processing (volume 1: Long papers). 2015: 687-696.
[8] Yang B, Yih W, He X, et al. Embedding entities and relations for learning and inference in knowledge bases[J]. arXiv preprint arXiv:1412.6575, 2014.
[9] Zou X. A survey on application of knowledge graph[C]//Journal of Physics: Conference Series. IOP Publishing, 2020, 1487(1): 012016.
[10] Q. Guo et al., “A Survey on Knowledge Graph-Based Recommender Systems,” in IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 8, pp. 3549-3568, 1 Aug. 2022, doi: 10.1109/TKDE.2020.3028705.
[11] Chicaiza J, Valdiviezo-Diaz P. A comprehensive survey of knowledge graph-based recommender systems: Technologies, development, and contributions[J]. Information, 2021, 12(6): 232.
[12] Choudhary S, Luthra T, Mittal A, et al. A survey of knowledge graph embedding and their applications[J]. arXiv preprint arXiv:2107.07842, 2021.
[13] Gao Y, Li Y F, Lin Y, et al. Deep learning on knowledge graph for recommender system: A survey[J]. arXiv preprint arXiv:2004.00387, 2020.
[14] Wang H, Zhang F, Xie X, et al. DKN: Deep knowledge-aware network for news recommendation[C]//Proceedings of the 2018 world wide web conference. 2018: 1835-1844.
[15] Zhang F, Yuan N J, Lian D, et al. Collaborative knowledge base embedding for recommender systems[C]//Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 2016: 353-362.
[16] Wang H, Zhang F, Zhao M, et al. Multi-task feature learning for knowledge graph enhanced recommendation[C]//The world wide web conference. 2019: 2000-2010.
作者简介
于敬,达观数据联合创始人,搜索推荐图谱产品团队的总负责人。同济大学计算机硕士,上海市青年科技启明星、上海市五一劳动奖章、上海市职工优秀创新成果奖、ACM CIKM算法竞赛国际冠军等奖项荣誉获得者。国际计算机学会(ACM)会员、中国计算机学会(CCF)高级会员、上海计算机学会(SCS)会员。曾先后在盛大创新院、盛大文学和腾讯文学从事技术研发工作,在智能推荐、搜索引擎、机器学习、大数据技术等领域有丰富的研究和工程经验,拥有十余项授权专利。




