

知识图谱问答系统任务和意义
问答系统(Qusstion Answering System,QA System)在大家的日常生活中随处可见,2014年微软率先推出了小冰智能聊天机器人,直至现在越来越多如siri移动生活助手和智能音箱等的面市,问答作为一种信息获取方式愈发受到大众和厂商的关注和投入。问答系统能够接受用户以自然语言形式描述的提问,并从大量的异构数据中查到或者推理出用户想要的答案。相比传统的信息检索系统,问答系统场景的核心在于用户的信息需求相对比较明确,而系统直接输出用户想要的答案,这个答案的形式可能是文档、结构化的表格或者推理加工的自然语言文本。
问答示例:
- 问题:阿根廷的首都在哪里 => 答案:阿根廷共和国的首都为布宜诺斯艾利斯。
- 问题:儿童安全锁怎么设置 => 答案:儿童安全锁位于各后车门的后边缘,各车门的儿童安全锁必须单独设置。
设置:
- 左侧:逆时针转动锁定,顺时针转动解锁。
- 右侧:顺时针转动锁定,逆时针转动解锁。
知识问答相比文本检索,减少了用户对检索文档内容的二次提取和推理的过程,会显著提升用户知识获取的体验。根据问答底层技术的差异,目前工程落地实现问答的技术路线基本分为基于知识图谱的问答(KBQA)、基于阅读理解的问答(MRC)和常见问题问答(FAQ)三种模式。三种问答的对比如下:

表1 常见的知识问答技术路线对比
FAQ和MRC不是本文介绍的重点,这里简要介绍。在FAQ中,重点是文本语义匹配的精度,如 用户的问题是“怎么加玻璃水”,而问答对库中的标准问句为“添加玻璃清洁液”,类似的泛化问题决定了常见的字符串相似度匹配无法解决,STS模型比如sentence-bert等双编码模型或者苏剑林老师的sim-bert等模型或者通过领域词典都可以解决类似泛化问题。MRC方面,基于百度dureader等中文阅读理解数据,在通用领域可以快速搭建一个MRC问答服务,但是垂直领域仍然需要标注数据来让模型的性能达到一个可以接受的水平。在垂直领域,针对MRC训练数据稀少的问题,可以从非结构化文本三元组标注的数据得到补充。如对于文本“北京,简称“京”,是中华人民共和国的首都,是全国的政治中心、文化中心,是世界著名古都和现代化国际城市。”,图谱构建过程中标注的三元组为(中国,首都,北京),构造的MRC问题即“中国的首都在哪里”,答案SPAN为“北京”的index位置。KBQA(Knowledge Base Question Answering)作为一种底层基于知识图谱的问答技术,相比传统的文本检索问答和FAQ(Frequently Asked Questions),基于垂直领域相对固定边界的知识图谱,可以结合业务提供一种高级的信息服务形式,通过确认、反馈等操作完成信息获取,现阶段下,无论是通用图谱还是领域图谱,业界对简单问答的效果都达到了一个比较好的水平,而在特定场景的领域图谱中,经过梳理,复杂问答特别是推理形式的问答也是可以达到一个比较可以好的效果。
基于知识图谱结构化关联知识的问答系统的业务价值包括:
- 知识的沉淀和高效复用,知识梳理更加明确直接,实现知识的瘦身和标准化;
- 返回的答案更能精准理解用户的意图,答案更加直接高效,避免二次推理加工;
- 对知识管理的维护更加方便,实体-属性-关系自然,方便增删改查;
- 特定业务场景下基于专家经验的复杂推理成为可能
智能问答系统技术架构
智能问答系统的整体基础框架图所示,一共分为据预处理模块、问句分析、 知识检索和答案生成四个部分。下面介绍达观知识图谱平台问答系统的一些具体的实践经验。
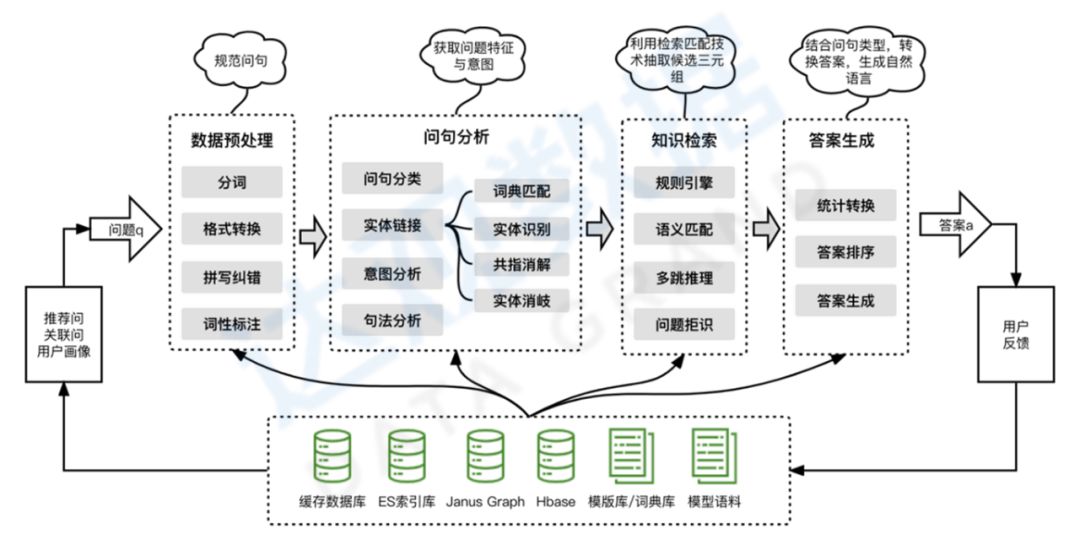
图1 智能问答系统的整体基础框架
01问句预处理
除了常见的分词和词性标注外,还可以根据知识图谱中已有的模式、实体名称、关键属性值对问句进行纠错。如图所示,根据产品的别名就可以对问句中的产品别名进行纠错。
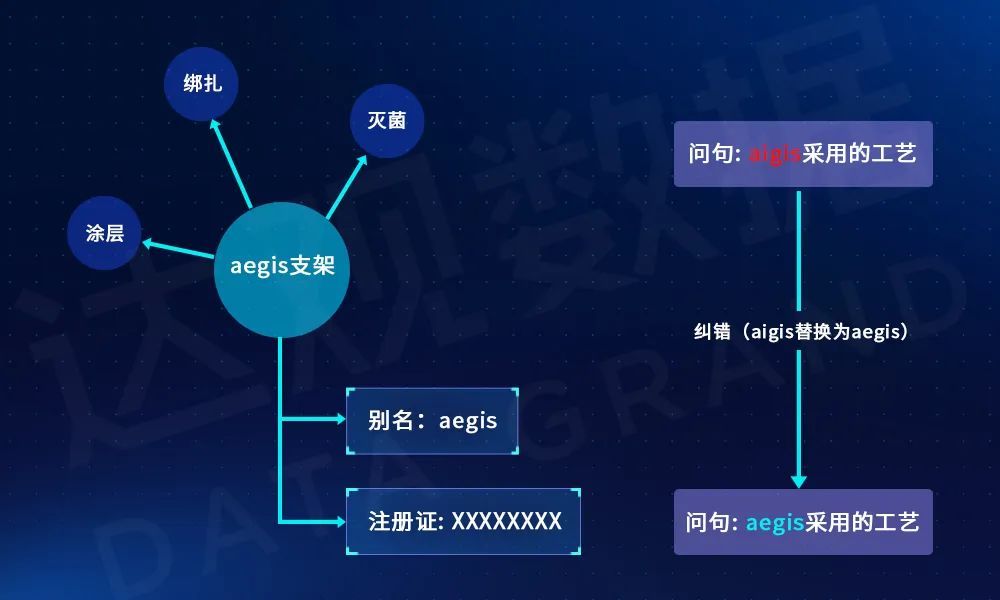
图2 基于知识图谱实体链接的Query纠错
实际场景下的领域知识图谱,更多的构建的是知识点的关联,即实体作为一个知识点,可能是一个短语或者一个语言片段,而在系统冷启动下,面对领域数据,通过句法分析提取出query中的短语,该候选短语也可以作为实体提及方便后续进行实体链接。通过中文树库(Chinese Tree Bank,Zhang Y., Zhou H., & Li Z. Fast and accurate neural crf constituency parsing,2020)限制短语的词性过滤重要的短语,如保留名词短语,通过短语提取可以避免单词、或者Ngram作为实体提及检索带来的巨大开销。我们采用HanLP自然语言处理包中的短语提取接口对query提取名词短语。
02实体链接和词槽提取
实体链接(entity linking)就是将问句文本的某些字符串映射到知识库中对应的实体上。实体链接是问答系统的核心问题之一,实际应用中问答中的大部分badcase可能都是实体链接出现了问题,如果实体识别一旦出错,答案就很容易出现完全不相关。为了解决垂直行业数据冷启动的问题,我们结合精确链和模糊链接相结合的方式来提高实体链接的精度。
实体精确链接利用知识库中已有的知识点,将模式(schema)名称、实体名称、可遍历的枚举属性值集合构建字典树(即Trie树),通过Trie前缀树提取查询中的精确实体名称。
我们在实际使用的Trie树的过程中,也做了若干优化:
- 以query分词结果token作为基本粒度构建Trie树,即命中的实体提及必须是由1个或者多个token组成的,比如对于query“中国平安”,Trie树种存在人物名称“国平”,分词结果为[中国,平安],可以避免提取出 “国平”的情况。
- 我们对Trie进行了性能优化,通用的Trie都是以一个字典的嵌套层级结构,这种情况下往往存在数据稀疏的现象,即造成了内存消耗比较大,另一方面也降低遍历查询的效率,针对这些问题业界也有很多Trie树的变种,如DATrie(双数组字典树)、Radix Tree(基数树),我们使用Radix和普通Trie做了性能对比,在200万实体名称的数据规模情况下,Radix相比Trie可以减少一半的内存占用。
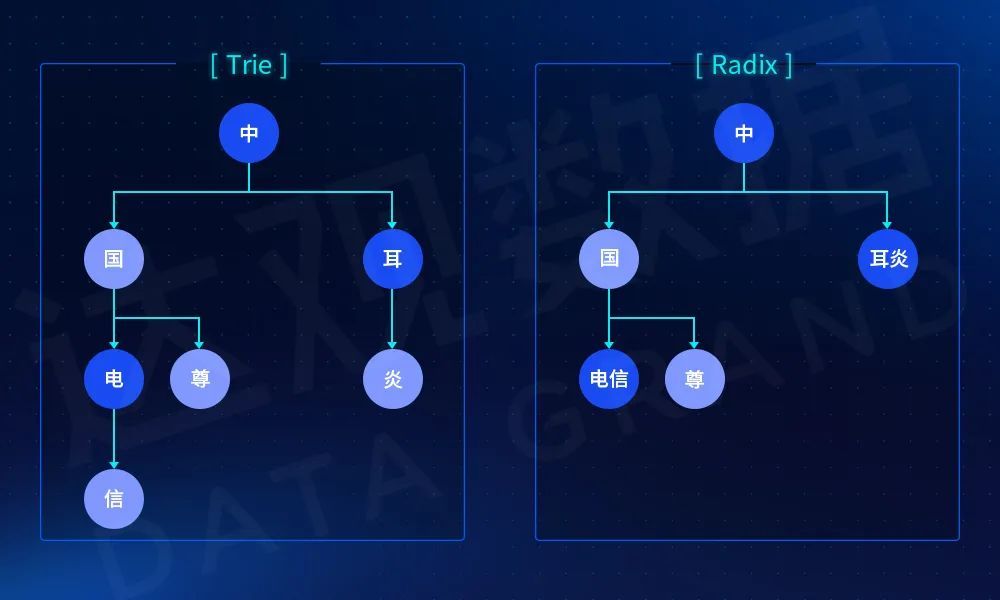
图3 Trie树和Radix压缩字符串对比
Trie树只能实现精确的根据实体名称的实体提及召回,而实际问答中用户的问题可能不包含完整的实体名称,这种情况下,需要根据NER模型抽取出Query中的实体,NER模型的候选结果和句法分析的候选名词短语构成模糊链接的词汇来源,并据此到ElasticSearch中进行检索,通过Es的文件检索,可以找到大部分具备和Query实体字符串相似的候选实体,通过可以对检索结果进行覆盖率、差异度、紧密度等各个维度对候选的结果进行相似性结果判断和过滤。除了使用NER去检索,业界也存在直接对图谱中的实体(描述)进行编码,使用向量检索去找到最相近的链接实体,感兴趣的读者可以参考相关文献和实践,在此就不再赘述。
 表2 模糊链接相似性判断规则
表2 模糊链接相似性判断规则
除了实体链接,还需要对提取Query中其他的槽信息,具体的槽位信息和意图相关,比如对于“查询实体类型的总数”这个统计意图,槽位信息需要具体的实体类型(网点)、统计谓词(总数)。槽位从类型上可以分为模式槽信息(实体类型、关系类型、属性名)、属性条件槽(属性名、条件、条件值)、统计条件槽(统计谓语:总数、最大、最小、平均等)。属性条件槽、统计条件槽一般都属于复杂问题情形。对于类型名称、统计谓词,因为相对比较可枚举,也可以以类似字典树的方式从Query中提取。因为知识图谱中实体知识点粒度和相关组合等问题,会导致候选链接的结果会互相重叠。一般而言,链接到的实体提及越长,其语义也就越明确,可靠性也更高。因此我们采用最大区间覆盖优先的筛选方法,优先保留链接更大的结果。如下图所示,有限保留“Aegis分叉型覆膜支架及输送系统”的链接结果,而忽略“支架”、“覆膜”链接结果。
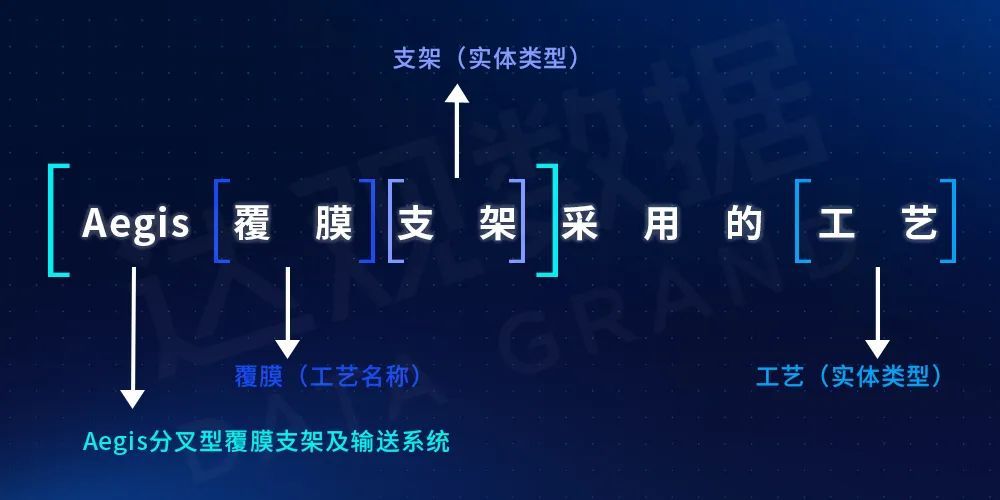
图4 多粒度下的实体提及识别
链接到多个实体提及或者槽需要进一步去除其中的歧义信息,例如Query:“平安银行的董事”,该问题为查询实体一度到达实体的问题,问题中的“董事”链接到董事(关系名称,企业->人物)和董事(人物名称)两个实体,对实体消岐的问题可以借助分类模型对Query 上下文进行分类判断,也可以借助知识图谱通过子图匹配的方法消除歧义。平安银行作为一个企业,通过董事关系可以查询一度实体;而董事作为一个人物,其一度的企业中无平安银行。通过槽位到子图的相关性打分,槽位组合[平安银行(企业),董事(关系名称)]比[平安银行(企业),董事(人物)]更加合理,优先选择更相关的组合作为槽提取的结果。
03问答意图识别
KBQA的意图相比传统检索意图会更加的复杂,实际应用中,文本检索的意图一般定义为搜什么,可能会采用“玩具”、“外卖”、“电影”这种类别体系来区分, 比如“变形金刚的票价”其实搜的就是变形金刚的电影,而KBQA的意图因为答案的精准、直接特点,注定了KBQA的意图的粒度会更细、维度会更多,例如查询实体的属性、条件过滤的实体、统计类查询、对比查询等。
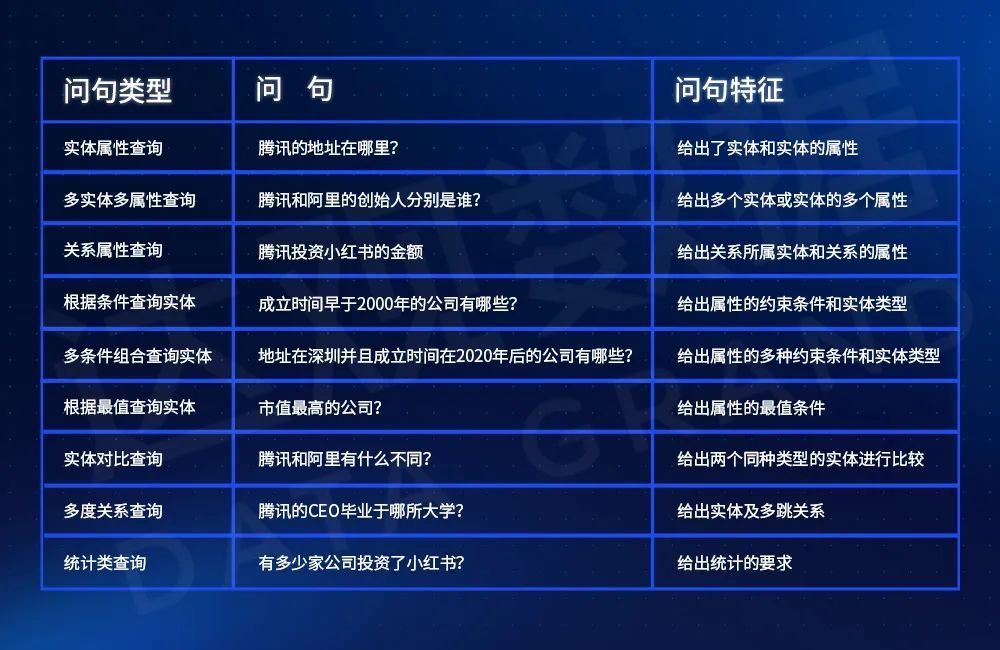
表3 常见的KBQA问答意图
问答意图可以通过模板匹配和基于神经网络的判别模型来识别。模板匹配通过系统内置的固定模板和自定义模板可以保证系统冷启动的基础问答效果。基于神经网络的意图判别模型需要在特定的图谱下大量的训练样本,例如使用fasttext等常见文本分类模型对Query进行意图分类。在垂直领域下,特别是用户的特定场景中,训练样本的生成和构造一直是一个较大的挑战,一种常见的方法就是配置问题模板,自动生成训练样本问题。比如对于意图“疾病的症状”,可以使用“${疾病名称|别名}的[症状|表现|症候]”模板,使用图谱的疾病实体,批量生成样本。分类模型相比模板匹配可以一定程度解决SPO一度问答问题的泛化问题。
结合问句分析的结果,从技术路线上主要可以分为基于检索排序的问答策略和基于语法解析的问答,基于排序检索的问答结合Query和问句分析的结果,找到图谱中若干个子图,然后对这些子图进行排序,返回Top结果作为答案;基于语法解析的策略则将Query转成成一个完成图查询语句,将执行该图查询语句的结果作为答案。
基于检索排序的问答策略
类似推荐系统的召回-排序两段策略,KBQA我们也可以利用问句分析的结果召回子图,然后计算Query和每个子图的相关性,返回Top子图。可以看出基于检索排序的问答策略回避了语法解析的难题,一般只需要问答-答案的标注数据采用端到端的训练即可,泛化能力较强。其中比较核心的问题在于档答案的表示形式。达观知识图谱问答系统结合知识图谱的模式,生成特定的答案文本形式。
基本的主要流程如下:
- 使用问句分析的实体,如“陆德明”,查询该实体的一度属性、一度实体、一度关系属性等三元组信息,谓词的判断特别重要,因此我们考虑生成只包含实体和谓词的候选三元组,即将O置空,(“陆德明出生日期”、“陆德明就职”);
- 将候选三元组信息作为整个文本串进行语义编码,如“陆德明出生日期”、“陆德明就职浦东支行”,因为整个三元组JOIN成了一个字符串,所以对图谱的模式设计也至关重要,对于[陆德明,就职,浦东支行]这个SPO,如果将关系设计的开始结束实体颠倒过来,则生成的候选串就缺乏语义了(浦东支行就职陆德明语法明显不合理);
- 将Query同样进行编码,计算向量距离作为相关性打分的判断依据。对于Query的编码同样也需要考虑链接的实体和实体提及的差异,如“Aegis的工序”,需要将Aegis替换成知识库中的实体名称,如“Aegis分叉型覆膜支架和输送系统的工序”,其和候选串“Aegis分叉型覆膜支架和输送系统工艺”的相似度更高,不容易被拒识。
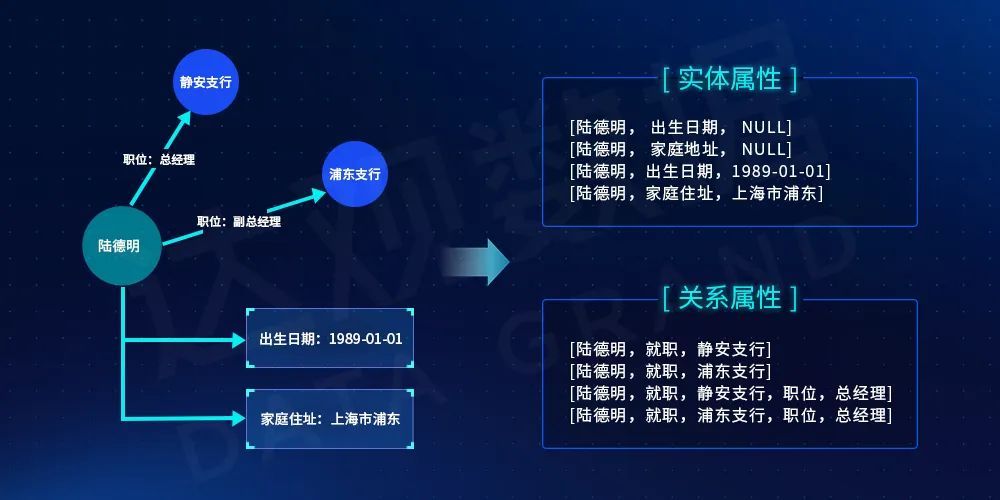
图5 候选答案SPO生成
在实际的SPO一度问答应用中,谓词即是最核心意图。对于“陆德明的生日是哪天”,陆德明的属性谓词“出生日期”作为正样本,其他实体属性”家庭住址”、关系属性“就职”等都可以作为负样本,标签为0。如此在足够的样本情况下,可以训练一个分类模型,作为上述第3)步中的匹配模型。
以上策略降低了工程上实现的复杂度,但是因为需要编码和存储候选答案的语义编码,同时可能还需要费力收集负样本去构建一个文本语义匹配模型,因此还有一种有意思的策略是基于Seq2Seq + True(前缀树,压缩知识库的答案集合,约束Seq2Seq编码)的实现方式,可以避免语义编码和文本意义匹配模型的训练步骤。
基本步骤包括:
- 使用Trie树压缩存储三元组;
- 构造训练集,训练Seq2Seq模型,下图是基于roformer-sim
(参考:https://github.com/ZhuiyiTechnology/roformer-sim)的Seq2Seq架构
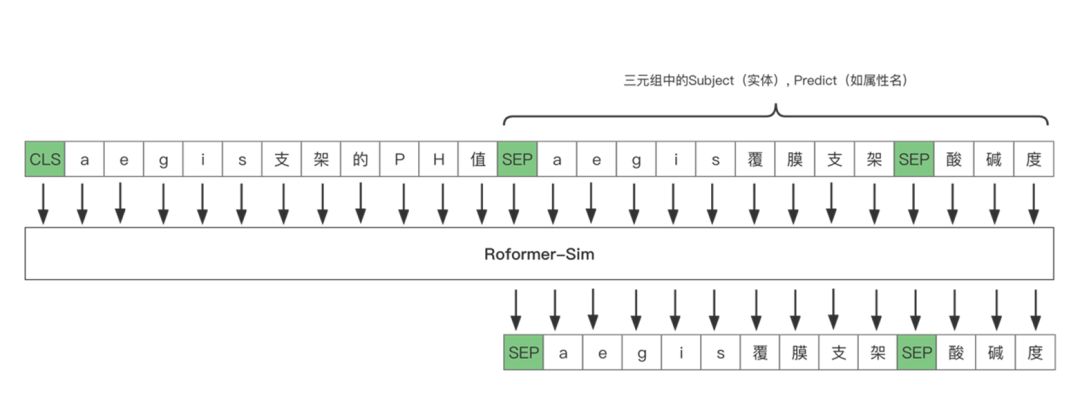
图6 基于reformer-sim的seq2seq框架
最后在解码的过程中,通过Trie限定decode的输出范围,从而保证输出的三元组答案一定在库中。关于Seq2Seq + Trie的具体实现方式可以参看KgClue的一个baseline实现(https://github.com/bojone/KgCLUE-bert4keras)。
基于语法解析的问答策略
复杂问句因为往往需要从一个多实体多关系的子图推理而来,因此一般采用将问句通过语法分析的方式转换成特定的查询语句或者查询解析树(原理类似SQL的执行计划)。相比简单的一度属性关系查询,复杂的问答包括多跳问题、约束问题、统计问题等。
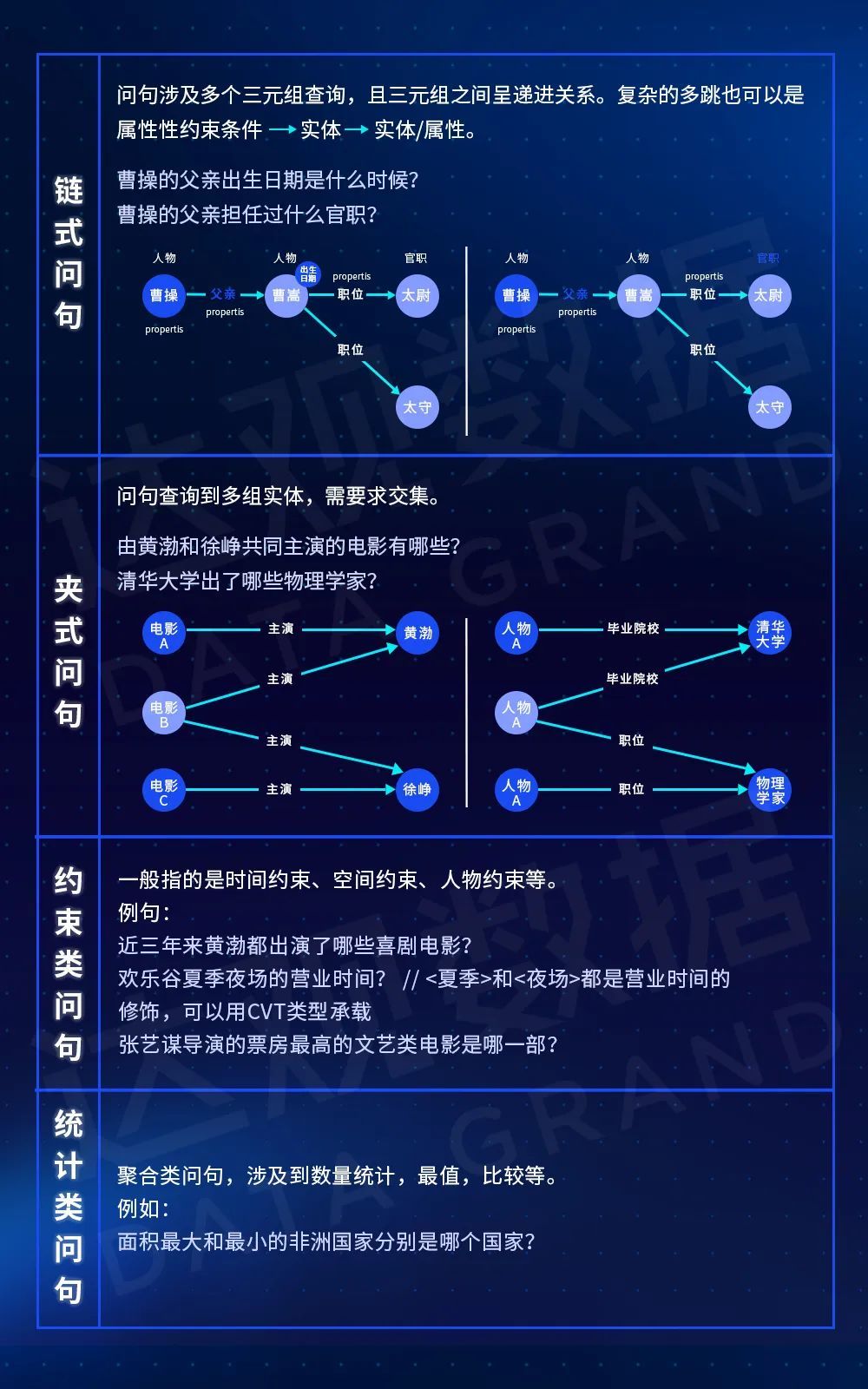
表4 复杂KBQA类型示例
因为是需要将Query转成查询语句,一般深度学习的做法是使用如BART等生成模型,生成对应的查询语句。这里介绍一下史佳欣团队KQA Pro(https://github.com/shijx12)的处理思路。通过将自然语言问题表示为基本函数组合而成的KoPL函数,函数运行的结果即为答案。KoPL中的函数包含FindALL、FilterSTR、Count等函数,函数存在相互输入输出的依赖,一个KoPL程序就是一个有向无环图。整个推理过程分为生成骨架和生成参数两个部分。骨架指定了执行的类型和顺序,参数指定了每个函数具体操作的输入。基于BART的KQA Pro的baseline目前可以达到90%左右,人类是97%。
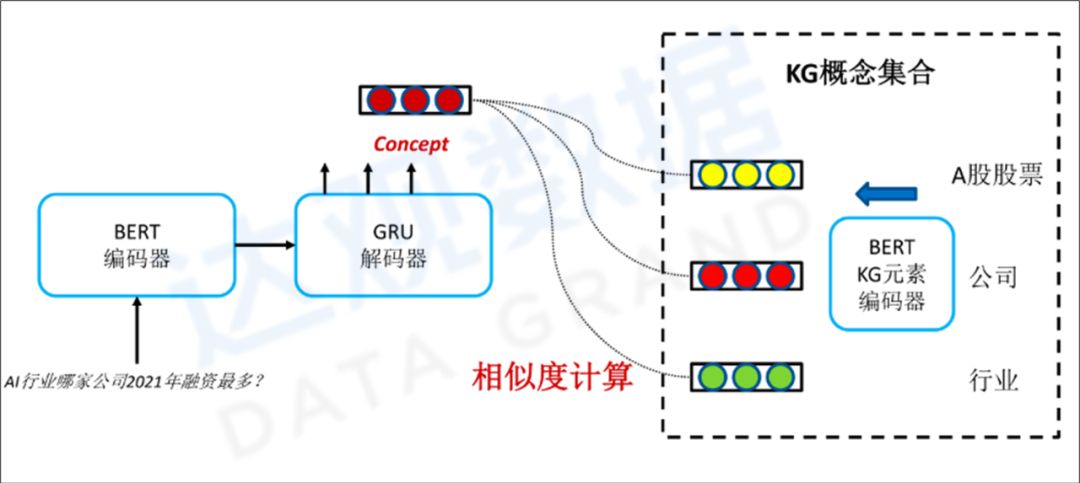
图7 骨架解析器和参数解析器
基于Seq2Seq的生成查询语句实际落地过程中,往往由于人力、算力、可维护等各个角度,图谱的完整性刚开始阶段不是特别的好,缺乏足够多质量较高的训练样本,因此基于深度学习的方法很难直接就可以发挥作用。对于复杂推理问答仍然需要一套灵活可配置的接口定义,可以方便对规则和模板等进行管理。参考KoPL的设计,将基础查询封装成基础算子,可以快速配置出如下图所示的一个复杂意图。

垂直领域的问答应用
01基于概念知识图谱的使用手册问答
概念图谱与实体图谱不同,它的实体是由一个个概念组成的,相应的概念和概念之间存在一定的语义关系。对于制度、手册类的场景,层次分明但很难提炼具体实例的场景比较适合构建概念图谱。概念图谱是将隐形的知识体系化、鲜明化,更好地捕捉到用户搜索的隐含意图,从而达到更精准反馈用户想要知识的目的。如下是将汽车使用手册拆分成分类层、原始概念、组合概念、意图层,实现知识最小粒度拆分的同时,满足复杂组合的意图解析。最后通过达观自然语言处理技术将手册进行知识结构化,并构建知识图谱。
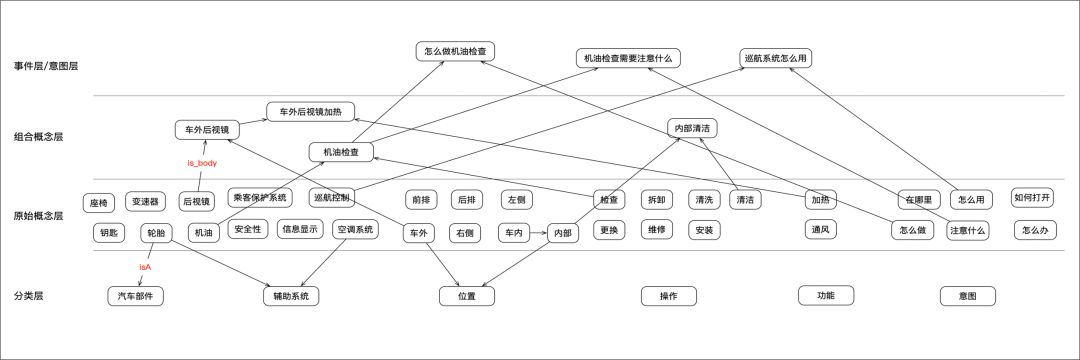
图8 基于组合概念的汽车手册知识图谱
在知识问答处理过程中,根据用户输入问句,解析原子级最小颗粒度的概念,逐层推理出最可能的组合概念,也就是用户的真实意图,从而实现更加精准的意图分析和答案推荐。
02基于失效知识图谱的根因关联
达观工业知识图谱从“人机料法环”等角度,将设备、人员、故障案例、工艺工序等数据构建知识图谱。输入失效模式、位置、现象等信息,通过智能问答语义分析引擎,可以将查询生成与之最匹配的子图,通过子图可以匹配到根本原因实体,如果子图链接不精准,支持对子图进行修改,子图越丰富,链接到的原因也就越精准。同时可以返回图谱关联的案例相关人员、相关排查解决措施等快速提高解决故障的效率。
知识图谱问答系统面临的困难
知识图谱问答系统总体上可以分为Pipeline和端到端两种方案,端到端的深度学习模型首先需要一个足够完整的图谱和基于这个图谱产生足够多的样本数据,而在实际项目中比较困难。相比较而言,实际落地过程中,Pipeline的方式会更可行,可以方便对每个过程或者步骤进行控制和定向优化,如添加业务词典去提高实体链接的精度等等。
中文知识图谱复杂问答目前很难自动化就获得一个较好的base效果,目前业界或多或少都会采用模板库的方式来解决特定问题。在垂直领域特定的图谱模式下,通过KBQA和推理可以体现出足够深度的专家经验,同时辅助一定结构化的数据降低图谱构建和维护的成本,这会是体现知识图谱问答价值的方式之一。
参考文章:
- https://huggingface.co/uer/roberta-base-chinese-extractive-qa
- https://zhuanlan.zhihu.com/kb-qa
- https://mp.weixin.qq.com/s/nN0aSXQN_IyjIJ1mRT5s3w
- https://mp.weixin.qq.com/s/8vz32-tLU6U1oYPErhbW0Q
- https://www.infoq.cn/article/ochiwf5rkuabdxm5s28x
- https://www.kexue.fm/archives/7427
- http://thukeg.gitee.io/kqa-pro/
- https://mp.weixin.qq.com/s/F-_qyHTsPtlrK77JgWidoA
作者简介
文辉,达观数据联合创始人,主要负责达观数据知识图谱方向产品和技术研发。同济大学计算机应用技术专业硕士,曾任职盛大文学数据中心和阅读集团数据中心核心研发工程师,负责智能推荐系统、数据挖掘和分析、分布式大数据平台、分布式爬虫系统的研发工作,在知识图谱、搜索推荐、自然语言处理、分布式平台架构设计等方面具备充足的研发和实践经验。




