
在大数据时代,推荐系统已成为连接用户与信息、产品和服务的关键桥梁。大数据不仅为推荐系统提供了前所未有的数据量,也带来了新的挑战和机遇。本文将以达观智能推荐为例,深入探讨大数据的定义与特点,数据清洗与预处理的技术,以及如何从数据中挖掘用户偏好,从而提升推荐系统的性能和用户体验。

第一部分:大数据的定义与特点
大数据是指无法在一定时间内用传统数据库软件工具进行捕捉、管理和处理的数据集合。
1. 大数据的基本概念
大数据与传统数据的主要区别在于其规模和复杂性。大数据通常被描述为“4V”:体量(Volume)、速度(Velocity)、多样性(Variety)和真实性(Veracity)。这些特点对推荐系统意味着可以处理更大量的用户行为数据,更快地响应市场变化,以及从多种数据源中提取有价值的信息。
2. 大数据的特点分析
大数据的四个V对推荐系统的影响深远。体量意味着推荐系统可以基于更全面的数据进行决策;速度要求推荐系统能够实时更新推荐结果;多样性使得推荐系统可以从多种数据源中学习;真实性则强调了数据准确性的重要性。
3. 大数据在推荐系统中的应用
大数据在推荐系统中的应用包括用户行为分析、趋势预测、个性化推荐等。达观智能推荐通过分析用户的搜索历史、购买记录和社交网络活动,推荐系统能够提供更精准的个性化推荐,从而提高用户满意度和转化率。
第二部分:数据清洗与预处理的技术
数据清洗和预处理是推荐系统中至关重要的步骤,直接影响到推荐结果的准确性和可靠性。
1. 数据清洗的重要性
数据清洗是确保数据质量的过程,它涉及到去除噪声、处理缺失值、纠正不一致性和异常值。在推荐系统中,数据清洗有助于提高推荐的准确性和用户满意度。例如,通过清洗用户评分数据,可以消除恶意评分或错误输入,从而提供更真实的用户反馈。
2. 数据预处理技术
数据预处理技术包括数据清洗、规范化、编码和特征工程。这些技术能够将原始数据转换成适合机器学习模型的格式,提高模型的性能和预测能力。
(1) 数据清洗:涉及识别和处理缺失值、异常值和重复记录。例如,可以使用均值填充、众数填充或预测模型来估计缺失值。
(2) 规范化:将数据缩放到相似的范围,如使用最小-最大缩放或Z分数标准化,以避免某些特征因数值范围大而对模型产生不成比例的影响。
(3) 编码:将分类变量转换为机器学习算法可以处理的形式,如使用独热编码(One-Hot Encoding)或标签编码(Label Encoding)。
(4) 特征工程:创建新的特征或修改现有特征以提高模型的性能,例如,从时间戳中提取出有用的时间信息,如小时、星期几等。
3. 数据预处理的实践技巧
在实践中,数据预处理需要结合业务知识和技术手段。例如,可以使用自动化工具来识别和处理异常值,或者应用机器学习算法来预测和填补缺失值。此外,可以使用管道(Pipeline)来自动化预处理步骤,这样可以在数据更新时轻松地重新应用相同的预处理步骤。
4. 数据预处理的挑战与解决方案
数据预处理过程中可能会遇到各种挑战,如数据不一致性、数据稀疏性和数据规模问题。
(1) 数据不一致性:不同数据源可能使用不同的格式或单位,需要统一数据格式以确保一致性。
(2) 数据稀疏性:在处理高维数据时,如文本或图像数据,可能会遇到大量的稀疏性问题。解决方案包括使用TF-IDF、Word2Vec等技术来处理稀疏特征。
(3) 数据规模问题:大规模数据集可能需要分布式处理。解决方案包括使用Apache Spark等大数据处理框架来并行处理数据。
第三部分:从数据中挖掘用户偏好
用户偏好的挖掘是推荐系统的核心任务,它直接影响到推荐的相关性和个性化程度。
1. 用户偏好的识别
用户偏好可以从用户的显式反馈(如评分和评论)和隐式反馈(如浏览和购买行为)中挖掘。通过分析这些数据,达观推荐系统可以识别出用户的兴趣和需求。
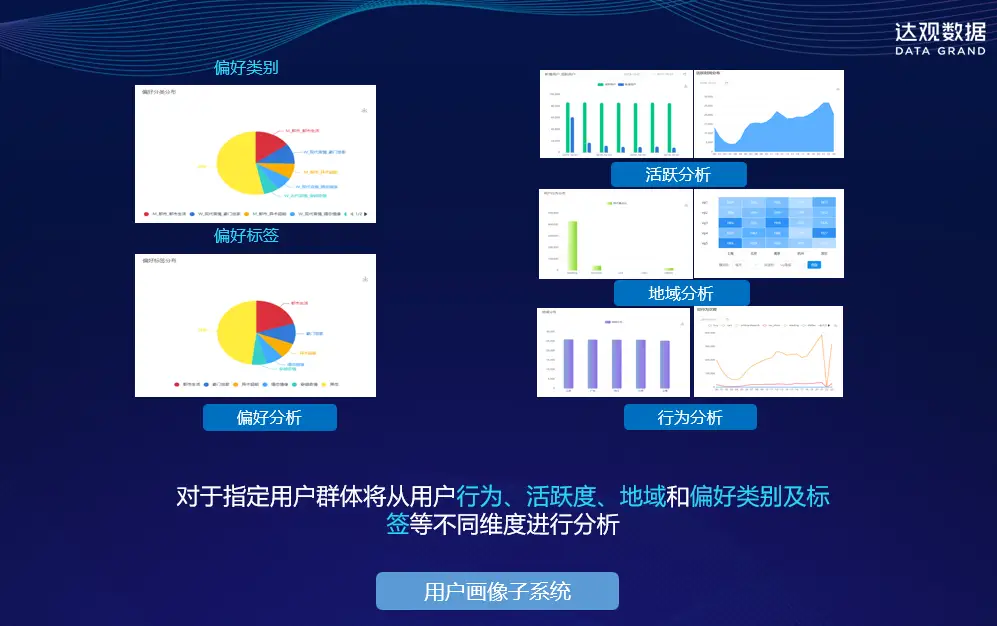
2. 数据挖掘技术的应用
数据挖掘技术,如聚类分析、分类和关联规则挖掘,可以帮助推荐系统从大数据中提取有价值的用户偏好信息。例如,通过关联规则挖掘,达观推荐系统可以发现用户购买行为中的模式,从而提供更有针对性的推荐。
3. 用户偏好的动态变化
用户偏好不是静态的,它会随着时间、环境和情境的变化而变化。推荐系统需要实时更新用户偏好,以保持推荐的时效性和相关性。这可以通过在线学习、增量更新等技术实现。
达观数据的推荐系统在数据清洗与预处理方面取得了显著的成就,通过先进的技术和丰富的行业经验,成功实现了高效的数据处理和优化。该系统能够自动化地识别和处理缺失值、异常值和数据不一致性,确保数据的高质量和可靠性。
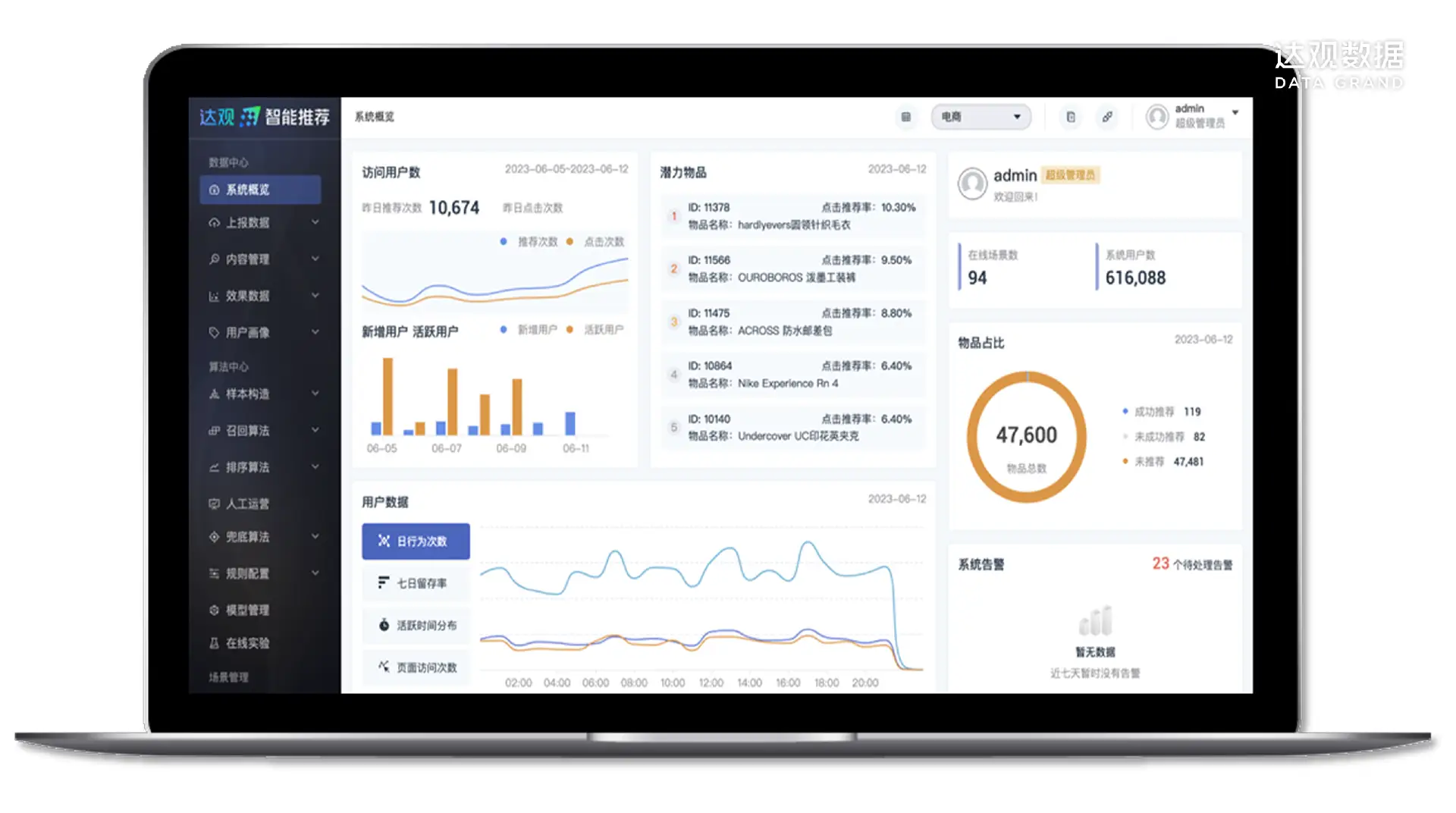
此外,达观数据还利用机器学习和自然语言处理技术,构建了强大的特征工程框架,使得推荐系统能够从复杂的用户行为和内容特征中提取出有价值的信息。这些技术的应用不仅提升了推荐的准确性和相关性,还显著增强了用户的满意度和粘性,为各行业的客户提供了强有力的支持。




