
在通用领域,以ChatGPT为代表的生成式大规模语言模型展现出卓越的知识学习和文字创作能力,受到国内外的广泛关注。垂直领域的GPT大模型同样拥有广阔的应用前景。达观基于多年文本智能技术积累和垂直领域场景业务经验,正在积极探索大语言模型LLM的实践,研发国产版GPT“曹植”系统,作为垂直、专用、自主可控的国产版ChatGPT模型,不仅能实现专业领域的AIGC智能化应用,且可内置在客户各类业务系统中提供专用服务。

达观自主研发的“曹植”垂直领域大语言模型将进一步夯实达观产业应用智能化基座,全面增强AI全产品矩阵能力。这也是国内大规模语言模型中首批可落地的产业应用级模型,目前已在金融领域AIGC多场景投入应用。未来可持续赋能金融、政务、制造等多个垂直领域和通用场景人工智能的落地和发展。
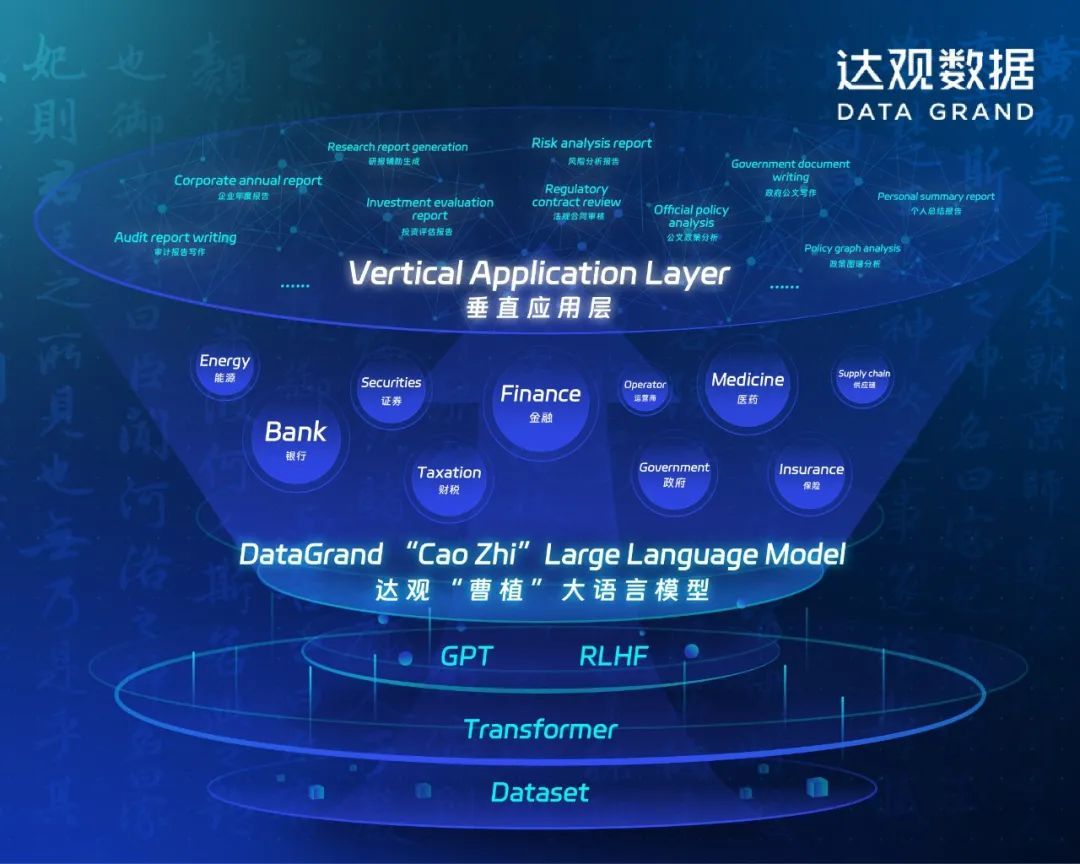
在产品应用层面,以“曹植”大模型作为支撑,为达观全栈AIGC智能产品带来革命性效果提升。
例如,达观企业申报材料自动生成,基于达观AIGC智能写作能力,可适配各类材料申报业务场景,基于已有各结构化类数据,快速撰写各类制式和非制式文档,应用于公文、招投标、投行申报文档、法律文书等专业写作场景。
达观金融报告AIGC智能写作,立足财经、金融市场研究写作场景,结合多项AIGC能力,可高效地完成研究类报告撰写,保证专业报告写作的高质量和时效性。

达观数据深耕深度学习语义智能领域十余年,多年来与北京大学、复旦大学等多个高校算法实验室和科研团队建立了深度交流合作机制。在算法方面,达观不断探索GPT3模型的原理验证和垂直行业知识的强化训练,不断提高模型的准确性和实用性。目前“曹植”大模型目前已获得重要技术突破,以大量通用数据和领域数据自监督训练的LLM为基座模型,通过大量通用任务数据和领域任务数据进行Prompt Learning微调,在垂直领域内的理解和生成的任务上都达到了很好的效果。
未来达观将建立多个垂直领域的专用语言大模型,为各行业的智能化需求提供更加专业和高效的解决方案。
3月11日,由中国人工智能学会主办,国内AI领军企业达观数据携手中国人工智能学会自然语言理解专委会、真格基金共同承办,中国信通院云计算与大数据研究所支持的ChatGPT及大模型专题研讨会在北京圆满落幕。大会围绕ChatGPT和大规模语言模型的发展应用,聚集众多人工智能产研大咖,共同探讨前沿技术及产业未来,呈现了一场精彩的思想交流盛宴。
会上达观数据董事长兼CEO、复旦大学计算机博士陈运文以探索大语言模型的垂直化训练技术和应用为题,向听众展开介绍达观数据“曹植”垂直领域大语言模型的研发进展和工程化探索,这也是“曹植”首度面向公众亮相。




