
分享嘉宾:达观数据CTO纪达麒
转载自第一新声《大模型之战下半场:从通用到行业垂直,「向下」扎根》稿件
为了深入研究通用大模型和垂直大模型的发展方向和应用效果,达观数据CTO纪达麒接受了第一新声的特别采访,以企业的实践为出发点,共同探讨通用VS垂直大模型的演进方向。
国内大模型超200+,百花齐放
据相关媒体报道,目前全球最大的大模型开源社区Hugging Face上的预训练模型数量,已经从此前积累的10万个增长到了超过30万个。回归国内市场来看,据公开资料不完全统计显示,截至2023年11月底,国内已经有至少200+大模型推出,并且大模型在各行各业“落子不断”。从统计数据来看,除了通用大模型外,在金融行业的落地速度最快,有近15%的大模型都是金融垂直大模型。
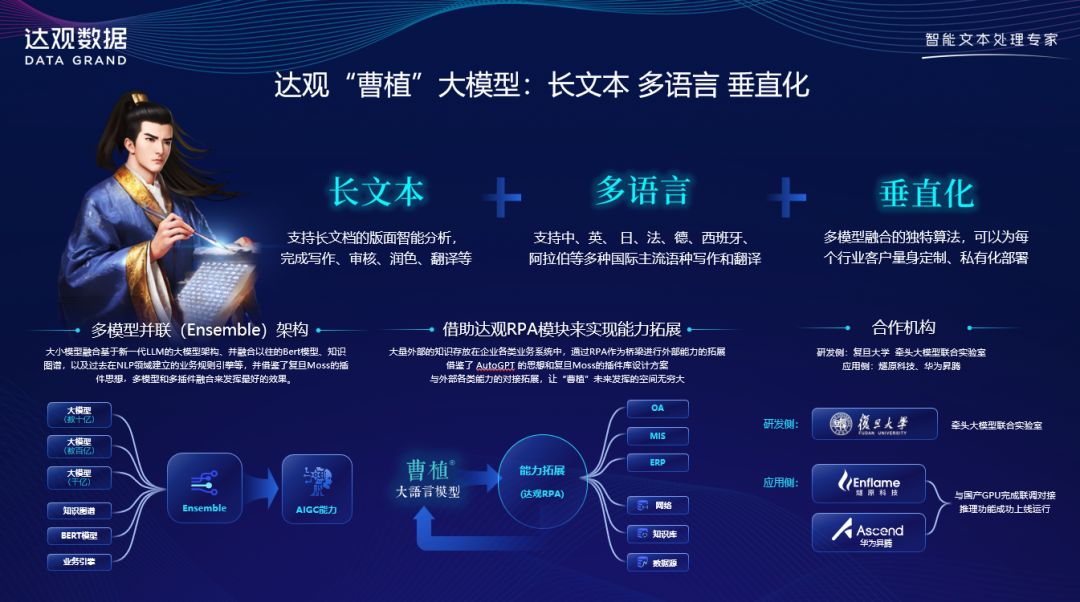
达观数据于23年7月推出的“曹植”大模型是国内首批垂直行业专用、自主可控的国产版GPT大语言模型,具备长文本、垂直化和多语言特性,擅长长文档写作、审核、翻译等。

达观数据CTO纪达麒表示:“一直以来,达观数据都专注于ToB领域,在金融和制造等行业积累了深厚的专业经验。我们采取的落地路线是将大模型引入原有产品中,为客户提供更有价值的服务。例如,达观的智能文本处理平台IDPS以往主要偏向文本抽取,需要标注、训练、调优等复杂步骤才能实现效果。而现在通过大模型能够实现无标注的自动抽取,显著降低了交付成本。让企业真正实现了降本增效。”
通用VS垂直
通用大模型和垂直大模型各有其独特的能力,它们之间是一种互补关系。因为通用大模型具有强大的语言理解能力,能够拓宽应用范围的广度,而垂直大模型则瞄准特定行业或需求,在精度和深度上更能满足实际要求。这两者不是对立面,而是相互支持、协同发展的关系。未来,两类大模型将会共生,成为赋能千行百业的关键。
对于这个观点,纪达麒也表示同意,“通用大模型和垂直大模型针对或解决问题的目标不尽相同,通用大模型需要具备更强的泛化性,而垂直大模型则必须要在垂直行业内的应用中保持高准确度。”
提及通用大模型和垂直大模型的落地空间,他认为有一个核心不同是在客户需求方面,不同层次和规模的客户对大模型的要求有所差异。例如在ToC端或中小型B端企业中,客户对模型的效果要求较低,但更看重成本的控制。因此,他们可能会选择使用通用大模型来解决部分问题,以期用较低的成本实现水准以上的效果。
然而,对于一些大型B端客户来说,提升效果能力很大程度能对他们的业务带来重大影响和价值,因此他们愿意投入更多的成本。这些客户可能会选择训练垂直大模型,或者利用像达观数据这样的专业垂直大模型服务,以获得更优秀的效果。在这种情况下,客户的关注点不仅在于成本,更在于如何实现最佳业务效果。
因此,在大模型的应用中,灵活选择适合特定业务场景的模型策略是非常重要的。
大模型落地难题
尽管大模型的发展目前非常活跃和热闹,但在实际落地方面仍然存在落地难题:如何找到合适的应用场景?
纪达麒表示,要想让大模型技术真正落地,不仅要依靠大模型本身,还要考虑中间实施过程和到达最后一公里的路径,即设计出合适的产品形态,选择最优的性价比,控制好机器资源成本,最终找到最佳的落地效果。因此,需要有既懂大模型又了解行业的专业人士,来共同解决这个问题。

在ToB行业化中,一个主要问题是监管难度的提高。在ToC端,也要面对备案等法规要求。传统互联网时代,能够以相对容易的方式审核文本内容,及时发现和处理一些涉及意识形态等有问题的内容。但是,大模型让监管难度显著增加。因此在落地过程中,如何进行有效监管成为一个亟待解决的问题。否则会面临滥用、不当使用或者其他潜在的法律问题。在解决监管问题的同时,还需要思考如何让更多的人从大模型的应用中受益。一言以蔽之,如何保证合理监管和推动社会效益之间的平衡是一个全行业都需要认真思考和解决的关键问题。
“达观数据的工程师团队在客户提供数据后,会根据具体情况进行处理,做到这一步其实还算顺利。但更难的问题是,如何结合大模型,充分发挥数据的价值,赋能企业实现更明确的业务目标。这就需要制定清晰的业务策略,明确产品的功能和特性,以及确保整个过程能够有效地满足客户的需求。”纪达麒强调道。
因此,当前所有企业面临的挑战是对大模型应用的战略性思考,以及将这些思考转化为具体的产品设计和实施步骤。要解决这一挑战,需要综合运用数据科学、业务洞察和技术专业知识,形成一个全面而可行的解决方案。最终,通过深度战略规划和清晰的产品设计,更好地发挥数据和大模型的潜力,实现更有针对性和有效的业务成果。
最后,达观数据CTO纪达麒表示,“我们要达成以下两点共识,首先,未来可能只有少数几家厂商具备高质量的提供底层通用大模型的能力,而垂直大模型和其产业化应用将迎来非常多的机会和竞争。未来企业内部,可能会同时将多个大模型结合起来,一起来去解决企业内部的各种问题。其次,企业的目标是利用 AI 来解决问题,而不是单纯地和 AI 结合。因此,企业需要思考如何让人和机器更好地协作,且以解决问题为出发点。不是为了用大模型而追捧大模型”。




