

达观数据与同济大学联合共建的“知识图谱与语义计算联合实验室”,近期发布了围绕新冠肺炎的多跳问答数据集和智能问答系统,该数据集基于COVID-19的七个方面(即百科、防控、物资、诊疗、健康、流行病、英雄)进行数据集梳理并进一步生成1跳(1-hop)、2跳(2-hop)、3跳(3-hop)的问答数据集,智能问答的主题涉及病理、症状、药物等相关的问题。其中论文成果《COKG-QA: Multi-hop Question Answering over COVID-19 Knowledge Graphs》发表于期刊《Data Intelligence》。
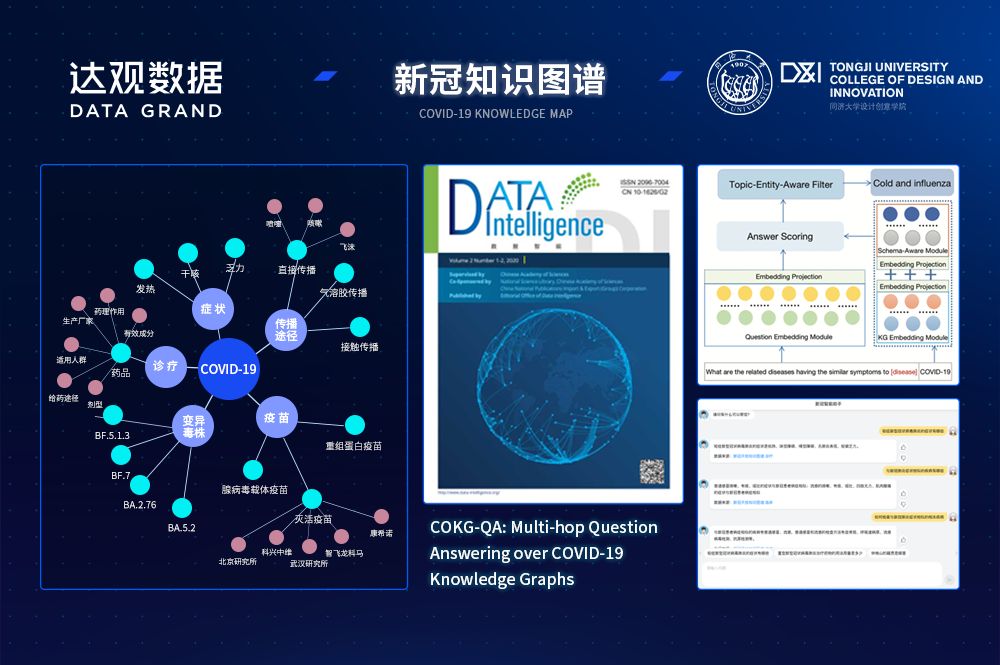
图1 《Data Intelligence》及发表论文的部分技术展示
主要研究贡献如下:
- 很少存在针对COVID-19管理的全面的KGQA数据集,尤其是缺乏针对多跳问题的数据集。受益于OpenKG-COVID19,我们推导出了一个大型多跳中文COVID-19 KGQA数据集COKG-DATA。它包含丰富的知识,为构建优质的问答系统提供了重要基础。
- 引入COKG-QA来证明在多跳KGQA任务中嵌入投影机制和模式信息的重要性。更准确地说,通过投影方法将来自不同空间的实体、模式和问题的嵌入转移到一个共同的空间中,以对齐重要特征。此外,实体嵌入与其类型嵌入相结合,以预测指定类型的答案。通过实验证明了COKG-QA是非常有效的,并且对于进一步推广到新领域知识也是值得借鉴的。
- 为了满足人们对COVID-19咨询服务的需求,基于COKG-QA开发了一个用户友好的交互式应用系统。该系统不仅提供准确和可解释的问题答案,而且易于使用,并具有智能提示和建议功能。
新冠肺炎多跳问答数据集COKG-DATA
我们根据OpenKG推出的OpenKG-COVID19的七个子KG(即百科、防控、物资、诊疗、流行病、英雄)来组织COKG-DATA,人们每天更容易问到这些子KG中的信息。COKG-DATA是一个新的具有挑战性的问答基准,包含有关疾病、症状、药物等相关的单跳问题和多跳问题。基于庞大而多样的COKG-DATA数据集,结合多跳KGQA技术,可以满足人们在大流行期间的复杂查询需求。我们花费大量时间基于OpenKG-COVID19清理数据并收集多跳问题。
01七大子KG
- 百科KG,让我们对SARS-CoV-2和COVID-19有个大致了解,以及相关的病毒和疾病信息。
- 防控KG,为各地个人、团体提供政府发布的预防指南。
- 物资KG,围绕疫情期间的物资供应情况展开,涵盖日常防护用品、医疗器械、药品等。
- 诊疗KG和健康KG是互补的,以利用关于各种疾病、药物、症状、检查方法和治疗医院的COVID-19相关知识。
- 流行病KG,运用流行病学的一般技术,研究疾病的分布及影响因素,探究疾病的成因,阐明流行病的规律,以有效地控制和根除疾病。
- 英雄KG,以新冠病毒专家为核心延展至履历、成果、事件、战役等各类概念。
02数据清洗
为了确保QA数据集的质量,我们清理了OpenKG-COVID19中的一些异常情况的数据,并删除了对QA来说不实用的三元组,包括一些三元组包含空字符串、标点实体或无用数字;一些三元组组成的比较奇怪的问题,例如,⟨新华医院的医生,在新华医院工作⟩;一些三元组中的头实体与尾实体相同的问题,例如具有“别名”关系的三元组。此外,OpenKG-COVID19中还存在包括对称性和反转在内的关系模式。我们为OpenKG-COVID19的这些关系模式扩展了三元组。经过数据清洗和关系扩展后,知识图谱数据集包含112246个实体、209个关系和787056个三元组。
03数据构造
我们利用OpenKG-COVID19的选定子图中的事实三元组作为1-hop数据。此外,我们手动为2-hop问题设计了47个关系,为3-hop问题设计了23个关系,其中组合的关系必须合理自然。具体来说,在2-hop关系中,前关系的范围必须与后关系的域相同。例如,“selected drug”关系的范围是“drug”,必须与2-hop关系“Selected drug Usage and dosage”中的“usage and dosage”域一致。相同的规则适用于3-hop关系收集过程。与多跳数据集MetaQA类似,我们使用Helsinki-NLP Opus-MT项目中的神经翻译模型以引入具有相同含义的更多样化和自然的陈述。利用Opus-mt-zh-en模型将句子从中文翻译成英文,然后使用opus-mt-zh-en将句子翻译回中文。此外,为了从顶层创建一个大规模的统一知识库,完成了实体对齐和关系对齐,以消除不一致问题。
04校验数据
为了确保COKG-DATA数据及中的问题相对时自然且有意义,我们招募了四名志愿者来检查数据集的质量,他们的研究领域均为知识图谱和问答方向。经过清理后的OpenKG-COVID19数据,按照关系对问题进行排序,然后成比例的随机抽取问题样本。这四名志愿者被要求用三个选项对抽样问题进行评分:1表示奇怪;2表示自然;3表示有意义。我们通过这个人工评分过程,删除或修改了奇怪的问答对,对COKG-DATA进行了四次优化。最后一轮的采样数为4000,志愿者的平均得分为2.8,证明了COKG-DATA是高质量的。
05数据集统计
COKG-DATA每个跳数问题的最终统计结果如表1所示。COKG-DATA将会保持与OpenKG-COVID19的同步更新,为用户提供更充分的知识。

表1 COKG-DATA统计数据
新冠肺炎多跳问答技术COKG-QA
IRQA& KGQA
在COVID-19相关信息的获取上,基于COVID-19 知识的问答系统作为一种便捷的交互方式受到越来越多的人的欢迎。COVID-19 QA现有两种范式:信息检索问答(Information Retrieval Question Answering,IRQA)和知识图谱问答(Knowledge Graph Question Answering,KGQA)。
1. COVID-19 IRQA
COVID-19 IRQA 系统基于文本问答对,通过计算数据集中提出的问题和问题/答案之间的相似性来获得答案,如WULAI-QA、CAiRE-COVID、COVIDASK。IRQA系统可以自然地回答人们经常提出的简单问题。WULAI-QA(Web Understanding and Learning with AI,WULAI)是一个动态的基于文档的问答系统,图2是其整体系统架构图。
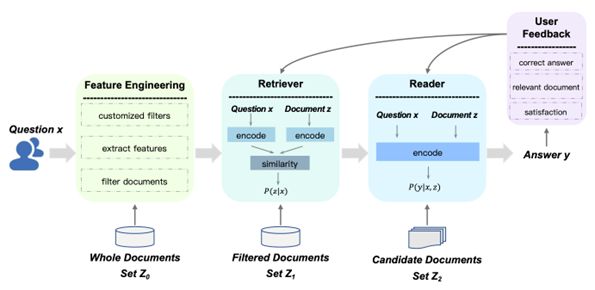
图2 WULAI-QA整体架构图
WULAI-QA主要有四部分构成:
- 特征工程(Feature Engineering)部分可以使用自定义过滤器和多种强大的特征来快速过滤不相关的文档;(2)检索器(Retriever)部分可以分别对问题𝑥和文档𝑧进行编码,并计算问题与过滤后的文档集中每个文档的相似度分数𝑝(𝑧|𝑥)。然后选择TOP(𝑘)个文档作为候选文档;
- 阅读器(Reader)部分将问题𝑥和文档𝑧连接在一起,并以概率𝑝(𝑦|𝑥,𝑧)从文本中抽取答案𝑦;
- 用户反馈(User Feedback)部分包括三部分数据:正确答案、相关文档和满意度分数。其中正确答案和相关文档的注释可以更新阅读器和检索器模型,而满意度分数用于更新检索器模型。为了适应COVID-19相关信息的快速扩展,WULAI-QA 通过合并稳健和定制的特征来过滤掉不相关的文档。此外,将用户反馈输入到到检索器模型和阅读器模型中,以提高在线部署期间的性能。
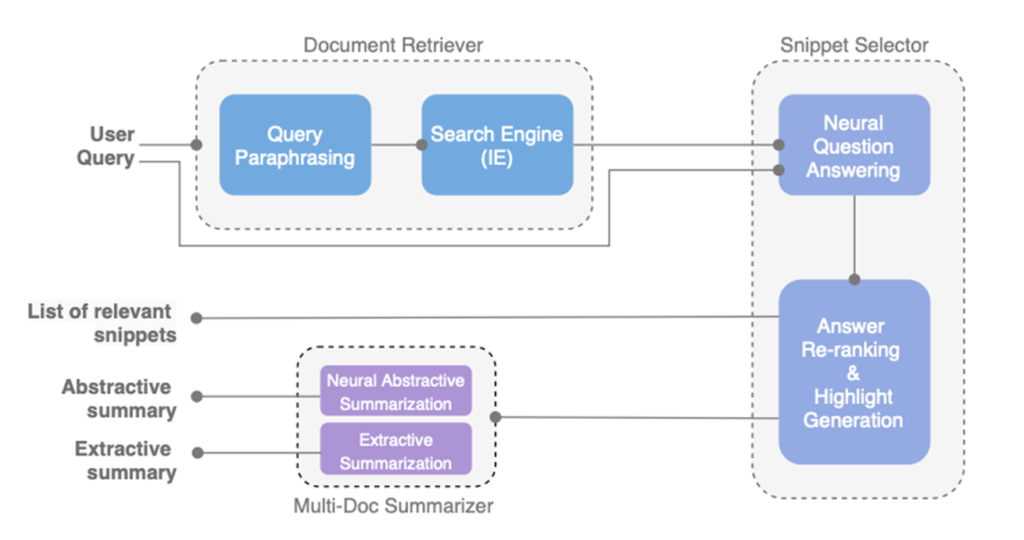
图3 CAiRE-COVID系统架构图
CAiRE-COVID(Center for Artificial Intelligence Research,CAiRE)是香港科技大学开发的一个实时QA和多文档摘要系统,旨在通过回答社区的高优先级问题并总结与问题相关的重要信息,以应对在 COVID-19上发表的大量科学文章的挖掘挑战。
其架构图如图3所示,由三个主要模块组成:
- 文档检索器(Docement Retriever)
- 相关片段选择器(Relevant Snippet Selector)
- 以查询为中心的多文档摘要器(Query-focused Multi-Document Summarizer)
它将信息抽取与最先进的QA和以查询为中心的多文档摘要技术相结合,在给定查询的情况下从现有文献中查找和高亮显示检索到的片段。同时还提出了以查询为中心的抽象和提取多文档摘要方法,以提供与问题相关的更多相关信息。
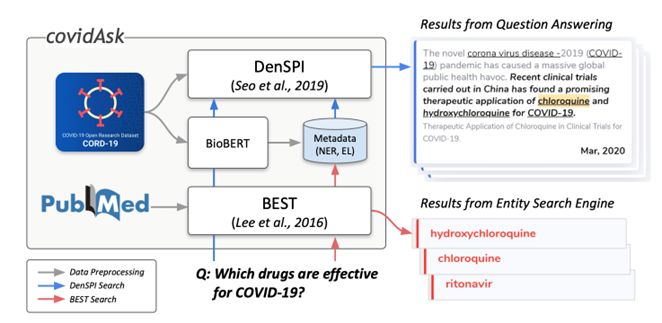
图4 COVIDASK整体过程
COVIDASK一个结合了生物医学文本挖掘和QA技术来实时提供问题答案的QA系统,利用有监督和无监督的方法使用 DENSPI和 BEST提供信息丰富的答案。图4是其整体流程图,首先预先索引了CORD-19中包含的研究论文中的所有短语,并使用它们来构建DENSPI 模型,还使用并高亮显示了PubMed中的生物医学命名实体来构建 BEST。
2. COVID-19 KGQA
在KGQA方面目前已经有诸多研究成果,主要包括三种类型:基于逻辑的方法、基于路径的方法和基于嵌入的方法。
1)基于逻辑的方法
该方法由于具有高精度和可解释性强的优点而被广泛讨论。GQE(Graph Query Embedding)、Query2Box 、BETAE将查询表示为有向无环计算图,以生成逻辑形式的查询嵌入。
GQE是一种基于嵌入的框架,可以有效地预测不完整知识图谱上的联合查询问题。GQE 背后的关键思想是将图节点嵌入到低维空间中,并将逻辑运算符表示为该嵌入空间中学习的几何操作(例如,平移、旋转)。经过训练后,可以使用模型来预测哪些节点可能满足任何有效的联合查询,即使查询涉及的未观察到的边。而且这个预测是非常高校的,时间复杂度与查询中的边数成线性关系,并且与输入网络的大小成常量。
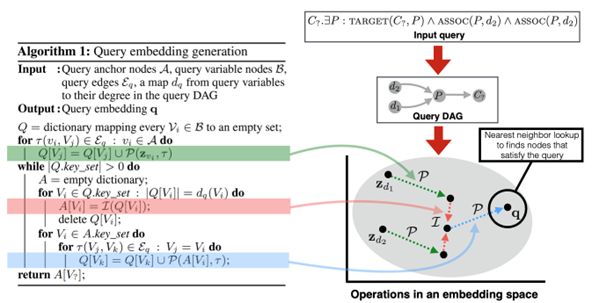
图5 GQE框架概览
如图5所示,GQE过程是,给定一个输入查询q,根据它的DAG结构表示这个查询,然后使用左侧的算法生成基于这个 DAG 的查询的嵌入。左侧的算法从查询锚节点的嵌入开始,迭代应用几何运算P和I生成与查询对应的嵌入q。最后,可以使用生成的查询嵌入来预测节点满足查询的可能性,例如,通过嵌入空间中的最近邻搜索。
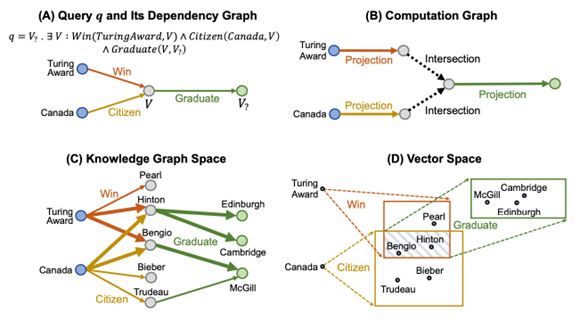
图6 Query2Box推理流程
Query2Box也是一个基于嵌入的框架,用于在大规模和不完整的知识图谱中使用∧、∨和∃运算符对任意查询进行推理。如图6是QueryBox的推理流程,(A)中,对于给定的联合查询语句“Where did Canadian citizens with Turing Award graduate?”,解析后使用依赖图进行表示;(B)中是计算图的示例,其指定了为(A)中的查询语句获取一组答案的推理过程。(C)中是知识图谱空间的示例,其中绿色节点(实体)表示查询语句的答案。粗体箭头表示与(A)中的查询图匹配的子图。D)中,KG的节点可以嵌入到向量空间中。然后根据计算图(B)获得查询嵌入的执行操作:从两个节点TuringAward和Canada开始,应用Win和Citizen投影运算符,然后是交集运算符(表示为黄色和橙色的阴影交集框)和另一个投影操作符,得到查询的最终嵌入,是一个绿色框,查询的答案是框内的实体。
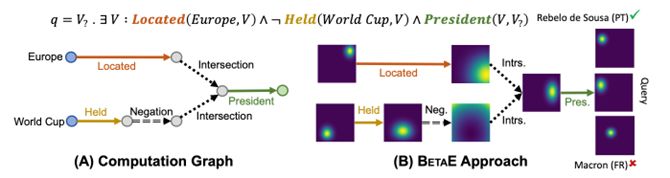
图7 BETAE回答一阶逻辑查询的过程
BETAE是一种概率嵌入框架,用于回答KG上的任意一阶逻辑(first-order logic, FOL)查询,也是第一个可以处理一整套FOL运算的方法,涵盖合取(∧)、析取(∨)和取反 (¬)操作。图8显示了查询语句“给定查询语句“List the presidents of European countries that have never held the World Cup”处理过程。该查询可以表示为三个术语的结合:(1)“位于(欧洲,V)”,查找所有欧洲国家;(2)“¬Held(World Cup, V)”,查找所有从未举办过世界杯的国家;(3)“总统(V,V?)”,它找到给定国家的总统。为了回答这个查询语句,首先定位实体“Europe”,然后通过关系“Located”遍历KG以识别一组欧洲国家。实体“World Cup”也需要类似的操作来获取主办世界杯的国家。然后需要对第二组进行补充,以确定从未举办过世界杯的国家,并将补充与欧洲国家组相交。最后一步是将关系“President”应用于生成的交集,以找到国家总统列表,从而给出查询答案。
2)基于路径的方法
该方法将问题中的主题实体沿着多个KG三元组搜索以找到答案实体或关系。其中很重要的是路径排序算法(Path Ranking Algorithm,PRA),PRA旨在通过直接在KG上自动学习语义推理规则来提高KG的覆盖率。PRA使用基于重新启动的推理机制的随机游走来执行多个有界深度优先搜索过程以查找关系路径。结合基于弹性网络的学习,PRA然后使用监督学习选择更合理的路径。然而,PRA在完全离散的空间中运行,这使得评估和比较KG中的相似实体和关系变得困难。为了缓解PRA的搜索空间大的问题,除了DeepPath、NSM的方法之外,还有其它一些研究工作围绕将KG推理视为顺序路径决策过程来展开。
DeepPath是一种KG推理的强化学习(Reinforcement Learning,RL)方法,使用基于翻译的知识嵌入方法来编码RL代理的连续状态,代理通过对关系进行采样,通过增量步骤的方式扩展其路径。为了更好地指导RL代理学习关系路径,DeepPath使用策略梯度训练和一个新颖的奖励函数,以提升准确性、多样性和效率。
NSM(Neural State Machine)采用师生网络来学习中间监督信号,主要思想是训练一个专注于多跳 KBQA 任务本身的学生网络,同时训练另一个教师网络在中间推理步骤提供(伪)监督信号(即我们任务中的推断实体分布) 改善学生网络。NSM主要由指令部分和推理部分组成。指令组件将指令向量发送到推理组件,而推理组件推断实体分布并学习实体表示。
3)基于嵌入的方法
该方法通过评估问题嵌入和候选答案嵌入之间的相似性以获得正确答案。比较应用广泛的是EmbedKGQA方法,通过预训练模型表示问题,并通过ComplEx表示知识图嵌入,并通过ComplEx的评分函数选择答案。
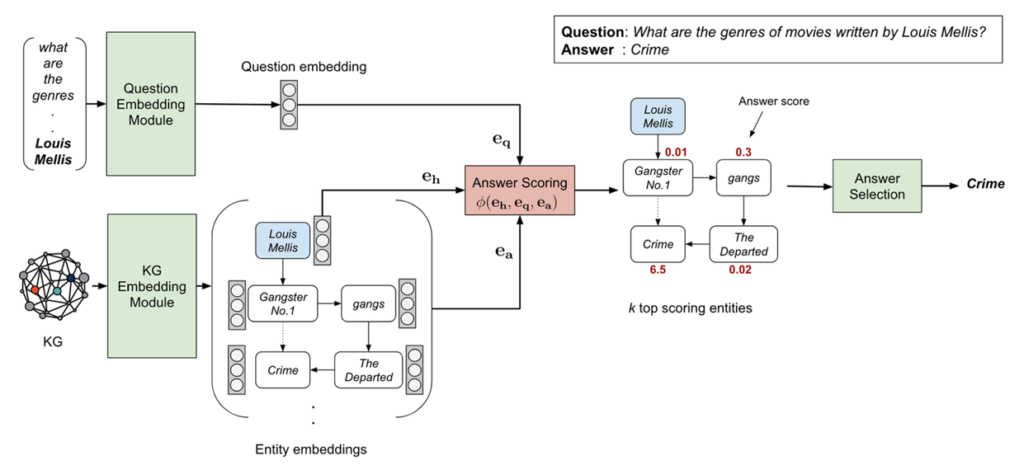
图8 EmbedKGQA概览
如图8所示,EmbedKGQA具有三个模块:
- KG嵌入模块学习输入KG中所有实体的嵌入;
- 问题嵌入模块学习问题的嵌入;
- 答案选择模块通过结合问题和关系相似性分数来选择最终答案。
EmbedKGQA使用嵌入使其更有效地处理KG稀疏性。此外,由于EmbedKGQA将所有实体都视为候选答案,因此它不会受到现有多跳KGQA方法的有限邻域无法访问问题的影响。
另外像关系图卷积网络方法聚合KG中特定多重关系的嵌入来预测答案。当然,还有一些基于嵌入方法结合文本语料库的研究也备受关注。
综上可以看出,KGQA相对于IRQA可以处理更复杂的QA问题。同时,我们也看到,人们在日常信息获取过长中也不再满足于提出一些简单的问题,例如“COVID-19患者的临床症状是什么?”。他们更倾向于表达复杂的多跳问题,比如“有哪些相关疾病与COVID-19症状相似?”这样的2跳问题,以及“如何检查与COVID-19症状相似的相关疾病?”的3跳问题。
引入KGQA,可以更大程度的满足人们的日常信息所求,提升人们获取信息的体验和效率,值得投入更多资源进行深入地探索研究。
COVID-19 & KGQA
基于COVID-19数据集,引入KGQA方法可以回答涵盖结构KG上的多个关系的复杂问题。此外,KGQA技术可以推理QA任务中的新知识。研究人员在不同方向上开展了大量的研究工作,也取得了挺好的进展。

图9 COVID-19 KG的模式
中国科学技术信息研究所的Ding Kai等人研发了COVID-19 QA系统。首先是基于COVID-19数据集设计了KG的模式,如图9所示,并从文本中抽取知识。
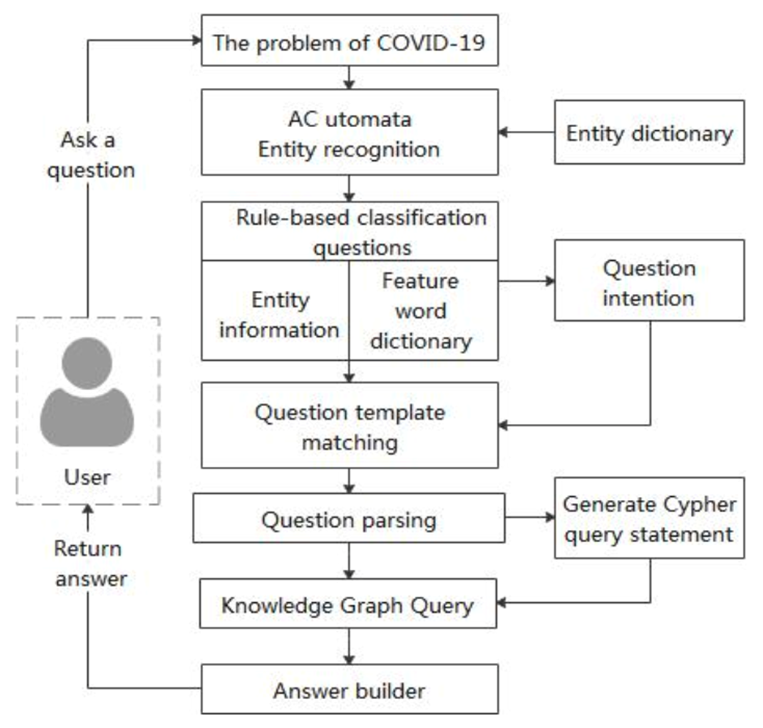
图10 QA系统处理流程
然后设计了一个基于规则的分类器,以识别当用户输入一个问题后的查询意图,接着,基于匹配模板的方式将问题转化为Cypher查询,最终从KG中找到答案并返回,整个过程如图10所示。
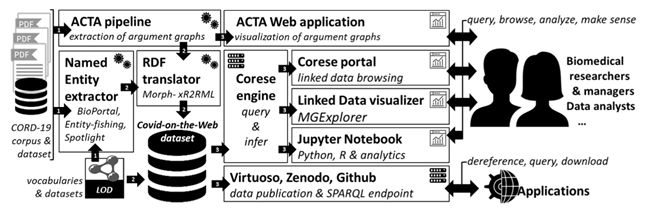
图11 Covid-on-the-Web概览
Covid-on-the-Web项目提供了较丰富的工具和数据,如图11所示,通过调整和组合工具来处理、分析和丰富“COVID-19 开放研究数据集”(CORD-19),让生物医学研究人员能够访问、查询和理解COVID-19相关文献。CORD-19语料库收集了50000多篇与冠状病毒相关的全文科学文章。该数据集包含两个主要知识图谱,除了展示CORD-19语料库中提到的命名实体,并链接到DBpedia、Wikidata和其他BioPortal词汇表,还可以展示从ACTA提取的参数,旨在帮助临床医生分析临床试验并做出决定。另外,在这个数据集上,还提供了几个基于Corese Semantic Web平台、MGExplorer可视化库以及Jupyter Notebook技术的可视化和探索工具。

图12 处理流程图
北京林业大学的Sun Yuze等人研究并构建了一个基于知识图谱的COVID-19问答系统。其问答功能是通过基于朴素贝叶斯算法的模板匹配实现的。处理流程如图12所示,对于输入的问题,系统首先进行实体识别,利用实体类型标注结合实体相似度匹配来识别用户问题中的实体。然后系统预测用户的提问意图,并使用训练好的问题分类器预测类别数。最后利用Cypher查询图数据库,生成并输出答案。
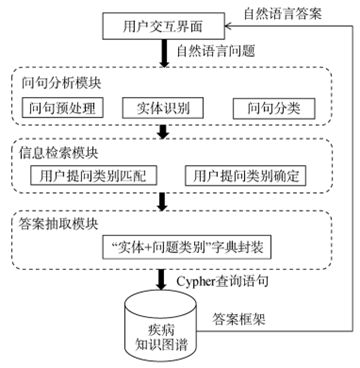
图13 基于疾病知识图谱的问答系统优化框架
吉林大学的李贺等人提出了一种基于疾病知识图谱的自动问答系统优化策略,如图13所示,在疾病知识图谱构建的基础上,结合AC多模式匹配算法和语义相似度计算实现用户自然语言提问中实体识别,综合考虑构建知识图谱的疾病数据集和问题语料的医疗高频词特征确定系统要回答的问题类别,然后采用人工标注和AC多模式匹配算法实现用户问题类别和系统问题类别的匹配,最后通过将匹配的实体和问题类别封装成分类字典方式转换成数据库查询语言,获取相关问题答案。其中COVID-19 知识图谱的可视化结果图14所示。
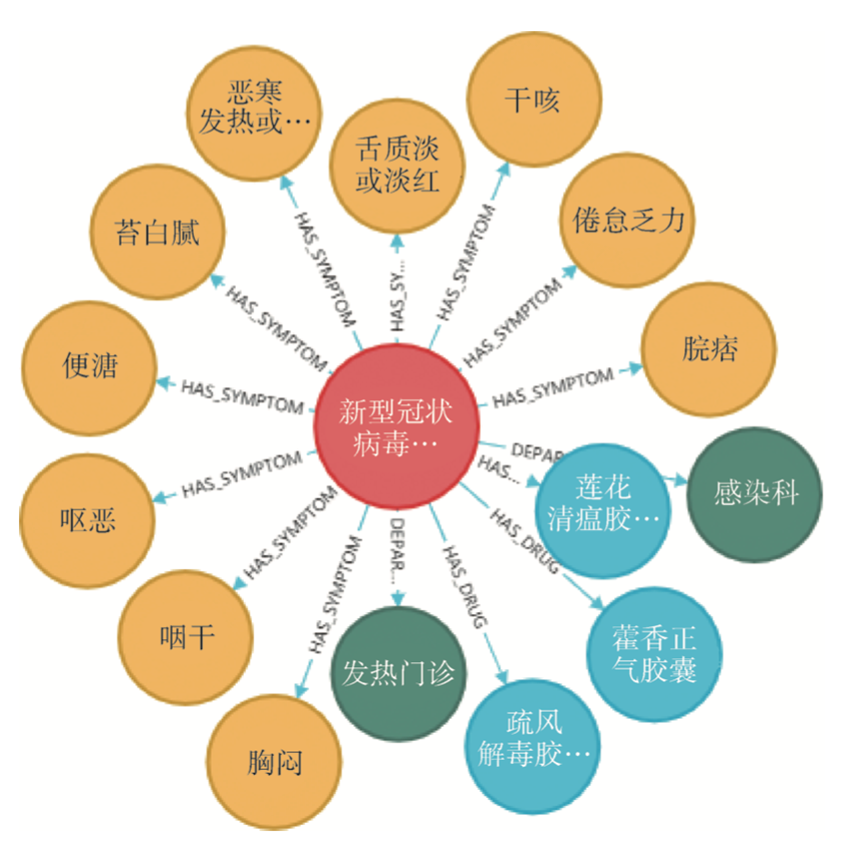
图14 COVID-19知识图谱(部分)
为了使框架不局限于预定义的规则,航天工程大学的Pei Zhongmin等人提出了一种基于知识嵌入方法TranE的相对通用的QA框架,如图15所示。
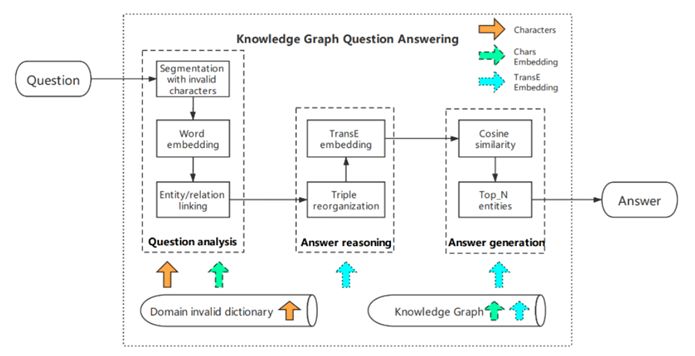
图15 中文领域KGQA框架
该框架由问题分析、答案推理和答案生成三部分组成。首先,问题分析模块通过屏蔽无效字符获得问题实体和关系。然后,答案推理模块结合时序逻辑和排列组合策略计算可能实体的TransE嵌入。最后,答案生成模块计算知识图中候选答案与实体的余弦相似度,将推理路径和答案实体返回给用户。
在公共KG的基础上,基于自然语言处理技术,已有一些KGQA系统,以帮助人们方便地获取有关COVID-19的信息。尽管这些QA系统是为COVID-19开发的,但它们无法为用户的各种问题提供最佳解决方案。
现有方法如GRAFT-Net、PullNet等通常使用单独的模型来表示知识图谱和问题,带来的问题是来自不同空间的异构嵌入需要适配到一个公共空间。此外,在当前的多跳KGQA任务中,如EmbedKGQA,表征KG结构特征的模式相关信息已被忽略。作为重要的先验知识的模式信息,有助于搜索指定类型的正确实体。更重要的是,公共COVID-19 KGs受到知识稀疏性的影响,尤其当这些知识是人们每天都希望获得的,会进一步影响下游QA任务的质量和用户体验。
COKG-QA
为了减轻人们对COVID-19大流行引起的健康问题咨询方面的焦虑,我们提出COKG-QA(multi-hop Question Answering over COVID-19 Knowledge Graphs),如图17所示,通过对EmbedKGQA模型的升级,以提高KGQA的性能。
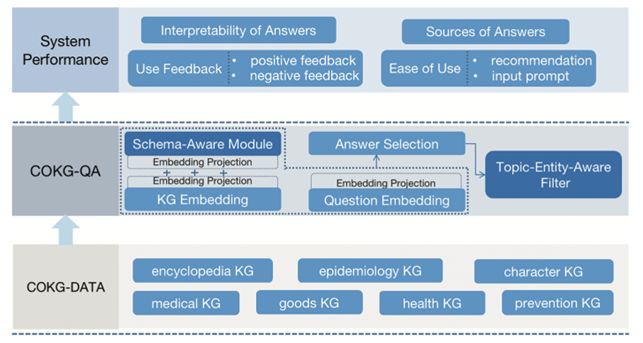
图16 COKG-QA系统架构图
1.COKG-QA总体介绍
KG中的实例三元组可以表示为⟨h, r, t⟩,其中h表示头实体,t表示由关系r链接的尾实体。给定一组实体E和关系R,G是一组三元组K,使得K ⊆ E × R × E。KGQA的任务是对于一个自然语言方式提问的问题q,搜索KG中的答案实体,包括基于KG上的多跳关系进行搜索。受EmbedKGQA的启发,在我们的方法中同样使用了KG嵌入模块(KG Embedding Module )、问题嵌入模块(Question Embedding Module)和答案选择模块(Answer Selection Module)。通过添加嵌入投影(Embedding Projection)和模式感知模块(Schema-Aware Module)在COKG-DATA上扩展EmbedKGQA。此外,在推理时添加了一个主题实体感知过滤器(Topic-Entity-Aware Filter)来预测仅与所讨论的主题实体相关的答案实体。流程如图17所示。
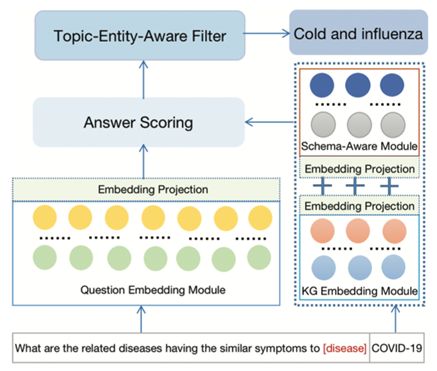
图17 COKG-QA流程图
2.COKG-QA主要模块介绍
1)嵌入投影
将不同模型生成的嵌入视为异构的。与实例级别的三元组一样,⟨s h, r, s t⟩ 是模式级别的三元组,其中s h代表头类型,s t代表由关系r链接的尾类型。s h, s t ∈ E’的模式嵌入也通过ComplEx方法训练以强化搜索答案,但模式模型和实例模型是分开训练的。更重要的是,问题嵌入是由预训练模型RoBERTa产生的,它利用了另一种技术范式。因此,这三个嵌入是异构的。尽管通过单独的模型有助于保持模式、实例和问题的特征,但很难在最终的 KGQA模型中对嵌入表示进行建模。全连接(Fully Connected, FC)线性层可以维护和投射迁移学习中的重要特征,尤其是当源域和目标域完全不同时。因此,在转移到一个公共空间之前对这些嵌入进行投影是合理的。我们分别定义了问题嵌入、实体嵌入、模式嵌入如式(1)(2)(3)所示。

其中eq是问题嵌入,en是由实例三元组训练得到的实体嵌入,e‘s-n是由模式级别三元组产生的实体类型嵌入。
2)模式感知模块
现有的KGQA方法只关注KG中的实例事实,忽略了模式中构造良好的先验知识。模式包含一个知识图谱的有价值的结构信息,它定义了这些概念和概念的属性。KG中的实体通过实体类型链接到它们相应的概念。通过引入模式感知模块将实体嵌入与相应的实体类型嵌入相结合,这将有助于过滤指定类型的答案实体。这足以让模型了解主题实体的类型以及答案实体的类型。具体来说,问题中的主题实体表示和作为答案的尾部实体表示是通过添加相应的实体类型嵌入来构造的。使用RoBERTa嵌入的问题表示不能对模式级别的关系嵌入进行编码,因为在实际应用中没有问题的关系类型标签。但是我们将实体类型与给定的问题连接起来,以暗示该问题与某个实体类型相关,如图15中所示的输入,具体表述如式(4)和(5)所示。
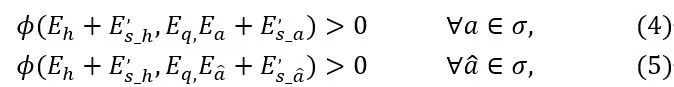
其中∅是ComplEx的评分函数,Eh是主题实体嵌入,E‘s-h是其对应的类型嵌入,Eâ表示正确的答案实体,Eh表示负样的实体,σ∈E是答案实体集。所有这些嵌入都会通过嵌入投影模块进行转换。
3)主题实体感知过滤器
因为我们收集的COKG-DATA非常大,所以需要添加一个过滤器来获取主题实体相关的实体,包括像EmbedKGQA这样的在推理时的1-hop、2-hop和3-hop实体,以预测更相关的答案实体。我们首先使用3-hop数在主题实体及其多跳实体之间进行映射,然后基于最佳训练模型预测多跳实体之间的答案。
3.COKG-QA实验
在表2所示,在COKG-DATA数据集上将EmbedKGQA和TransferNet与COKG-QA进行了准确率数据对比。COKG-QA在1-hop、2-hop、3-hop问题上的数据表现优于EmbedKGQA,而TransferNet在1-hop和2-hop问题上的表现优于COKG-QA。但是TransferNet在3-hop问题中的准确率最低。TransferNET关注问题的不同部分,在每一步搜索对应的关系,这使得它对图中每一跳关系的质量和数量都很敏感。因此,我们假设COKG-DATA的少量3-hop数据导致TransferNET性能不佳。然而,EmbedKGQA和COKG-QA都将多跳KGQA任务视为链路预测,在KG嵌入模块中将多跳关系作为单个关系。例如,“并发症||常用药物||用法用量”、“药物||药物成分”和“注意事项”的每一个关系都被视为一个单一的关系,放在一个三元组中。因此COKG-QA避免了现实世界中非常普遍的数据不平衡问题,并对神经模型提出了挑战。更重要的是,TransferNET计算复杂度高,内存存储问题,因为它计算一个实体被多次激活为答案实体的概率,这也会影响推理速度。

表2 不同模型在COKG-DATA上的对比数据
新冠肺炎COKG-QA问答系统交互
通过大量实验表明COKG-QA技术的卓越性能,同时我们也设计了一个基于COKG-QA的交互式Web QA应用系统。通过友好的交互设计以改善用户体验。
01答案的可解释性
与大多数直接给出答案的KGQA系统不同,我们的系统将解释多跳问题的中间上下文,以使多跳问题的答案具有可解释性。将通过计算ComplEx分数,根据最佳训练模型推断出答案。但是基于EmbedKGQA模型的答案是不可理解的。例如,2-hop问题“小儿颅内肿瘤推荐的药物种类有哪些”的答案是“工伤的化学药、处方药和医保药”,这会给用户带来类似“与上述答案中提到的药物类型相对应的相应推荐药物是什么?”。换句话说,人们不仅想得到最终的答案,还想弄清楚中间结果是什么。所以我们提供了一个可以解释的答案“小儿颅内肿瘤甘油果糖注射液的推荐药物是化学药物;小儿颅内肿瘤推荐用药吡拉西坦葡萄糖注射液是医保工伤用药……”。
可解释响应的过程如下:
- 当QA系统收到多跳问题时,首先识别主题实体
- 随后,根据问题和识别出的头部对分数进行排名,得到非直接尾部答案
- 为了得到一个可解释的最终答案,我们需要寻找中间关系,得到中间实体。过滤掉数据集中标记的具有相同标题和答案的问题和相应的多跳关系。此外,我们选择与数据集中具有相同多跳关系或与用户问题最相似的问题对应的可解释答案作为最终答案
02答案来源
我们用对应的URL给出答案的来源,帮助用户追踪上下文,这也增加了系统的可信度。我们系统的答案来源通过在选定的子图中提供图名来提供结果。如果用户的问题涉及多个链接图,则会显示多个图名称。示例如图18所示。
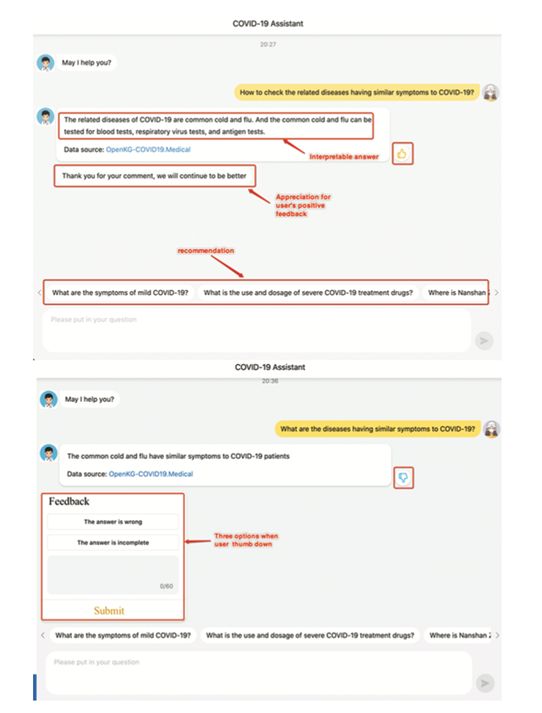
图18 COKG-QA系统中的用户友好功能
03使用反馈
我们设计了点赞和点踩按钮来鼓励用户提供反馈,这些反馈将用于改进COKG-QA模型。当用户给予正面反馈时,系统会随机生成一个感谢句。当用户点踩时,会弹出一个气泡,并为用户显示三个选项:错误答案、不完整答案和自定义意见。自定义选项为用户提供了灵活提出建议的空间,并进一步受益于提高 QA 系统的有效性。
04易用性
许多医学术语对于用户来说并不常见或难以记住,例如疾病名称和治疗方法。自动输入提示功能对于提高系统的可用性具有重要意义和实用性。我们的系统在很多场景下都支持自动补全。例如,用户可以只使用一个单词、拼音、多个单词的首字母,甚至是模糊搜索。输入框中的提示可以扩大用户查询的焦点,帮助完成用户想问的问题,如图19所示。此外,我们的系统还可以推荐与主题实体相关的问题,让用户可以探索更多关于原始问题。

图19 COKG-QA系统的可用性
以上是对围绕新冠肺炎的多跳问答数据集和智能问答技术的联合研究成果的介绍。除此以外,达观数据与同济大学以联合实验室为契机,依托双方产业与学术优势,围绕知识图谱与语义计算,在人才培养、学术研究、技术研发、科技成果转化等方面不断深入探索,联合申报了国家联合基金项目、上海市人工智能科技支撑专项等科研项目,联合发布了第二十一届中国计算语言学大会(CCL 2022)技术评测任务-汽车工业故障模式关系抽取,开展了多场前沿技术在产业化化应用的会议交流,实现多领域、多层级深入合作,共同引领知识图谱与语义计算领域技术创新以及产业化进程。

图20 左:著名知识图谱专家、同济大学百人计划、设计创意学院特聘研究员王昊奋教授 右:达观数据CEO陈运文
参考文献:
[1] Du H, Le Z, Wang H, et al. COKG-QA: Multi-hop question answering over COVID-19 knowledge graphs[J]. Data Intelligence, 2022, 4(3): 471-492.
[2] Zhang Y, Zhang X, Hu Y, et al. Wulai-qa: Web understanding and learning with ai towards document-based question answering against covid-19[C]//Proceedings of the 14th ACM International Conference on Web Search and Data Mining. 2021: 898-901.
[3] Su D, Xu Y, Yu T, et al. CAiRE-COVID: A question answering and query-focused multi-document summarization system for COVID-19 scholarly information management[J]. arXiv preprint arXiv:2005.03975, 2020.
[4] Lee J, Yi S S, Jeong M, et al. Answering questions on COVID-19 in real-time[J]. arXiv preprint arXiv:2006.15830, 2020.
[5] Ding K, Han H, Li L, et al. Research on question answering system for covid-19 based on knowledge graph[C]//2021 40th Chinese Control Conference (CCC). IEEE, 2021: 4659-4664.
[6] Michel F, Gandon F, Ah-Kane V, et al. Covid-on-the-Web: Knowledge graph and services to advance COVID-19 research[C]//International Semantic Web Conference. Springer, Cham, 2020: 294-310.
[7] Sun H, Dhingra B, Zaheer M, et al. Open domain question answering using early fusion of knowledge bases and text[J]. arXiv preprint arXiv:1809.00782, 2018.
[8] Li He, Liu Jiayu, Li Shiyu,et al. Optimizing Automatic Question Answering System Based on Disease Knowledge Graph[J]. Data Analysis and Knowledge Discovery, 2021, 5(5): 115-126.
[9] Saxena A, Tripathi A, Talukdar P. Improving multi-hop question answering over knowledge graphs using knowledge base embeddings[C]//Proceedings of the 58th annual meeting of the association for computational linguistics. 2020: 4498-4507.
[10] Reese J T, Unni D, Callahan T J, et al. KG-COVID-19: a framework to produce customized knowledge graphs for COVID-19 response[J]. Patterns, 2021, 2(1): 100155.
[11] Pei Z, Zhang J, Xiong W, et al. A General Framework for Chinese Domain Knowledge Graph Question Answering Based on TransE[C]//Journal of Physics: Conference Series. IOP Publishing, 2020, 1693(1): 012136.
[12] Hamilton W, Bajaj P, Zitnik M, et al. Embedding logical queries on knowledge graphs[J]. Advances in neural information processing systems, 2018, 31.
[13] Ren H, Hu W, Leskovec J. Query2box: Reasoning over knowledge graphs in vector space using box embeddings[J]. arXiv preprint arXiv:2002.05969, 2020.
[14] Ren H, Leskovec J. Beta embeddings for multi-hop logical reasoning in knowledge graphs[J]. Advances in Neural Information Processing Systems, 2020, 33: 19716-19726.
[15] He G, Lan Y, Jiang J, et al. Improving multi-hop knowledge base question answering by learning intermediate supervision signals[C]//Proceedings of the 14th ACM International Conference on Web Search and Data Mining. 2021: 553-561.
[16] Xiong W, Hoang T, Wang W Y. Deeppath: A reinforcement learning method for knowledge graph reasoning[J]. arXiv preprint arXiv:1707.06690, 2017.
[17] Shi J, Cao S, Hou L, et al. TransferNet: An effective and transparent framework for multi-hop question answering over relation graph[J]. arXiv preprint arXiv:2104.07302, 2021.
[18] Trouillon T, Welbl J, Riedel S, et al. Complex embeddings for simple link prediction[C]//International conference on machine learning. PMLR, 2016: 2071-2080.




