
随着企业的发展,传统数据库检索、开源垂直搜索引擎暴露出诸多搜索问题,比如数据规模庞大、异质多元、组织结构松散、搜索引擎性能差、结果匹配度低、搜索内容缺乏语义理解,搜索结果缺少泛华关联等等,用户使用过程中不仅需要练就一双火眼金睛还得有足够的耐心,才能从搜索到的结果中寻找到匹配的答案,甚至在某运营商的知识库系统中,用户想需要对query进行“斟词酌句”,才能从“传统搜索引擎”中匹配出相应的答案,这些问题对人们有效获取信息和知识提出了挑战。

为了提高搜索质量与效率问题,达观智能搜索系统将搜索引擎与知识图谱技术进行了有效的融合,其特点是能够精准捕捉用户搜索意图,理解用户自然语言提问,将答案直接返回给用户,受到越来越多用户的青睐。知识图谱的快速发展,为搜索引擎实现提供了高质量的知识来源,也直接推动了智能问答在搜索行业领域的快速发展。
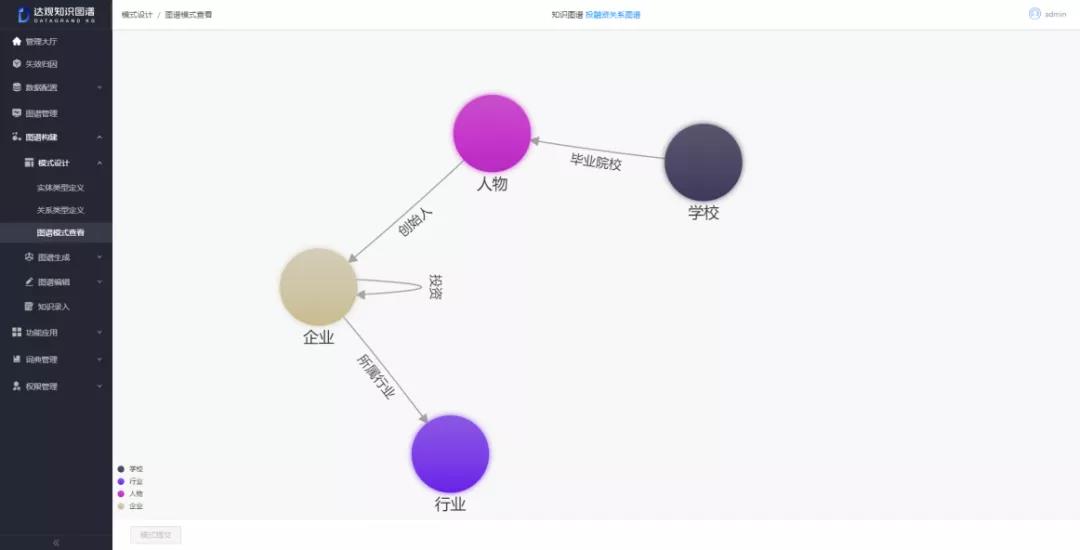
知识图谱旨在描述客观世界的概念、实体、属性、事件及其之间的关系,本质上是一种语义网络。其结点代表实体(entity)或者概念(concept),边代表实体/概念之间的各种语义关系。
通俗地讲,知识图谱就是把所有不同种类的信息,连接在一起而得到的一个关系网络,知识图谱提供了从“关系”的角度去分析问题的能力。
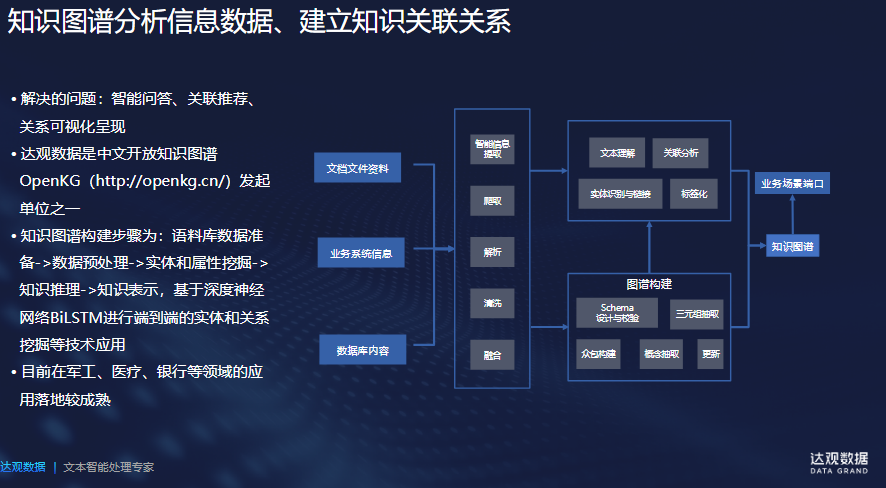
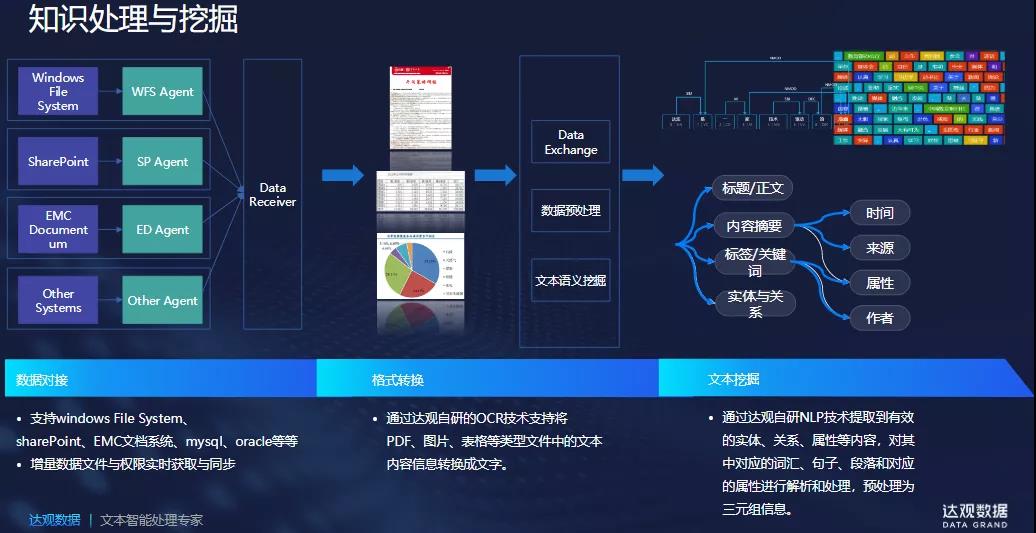
知识图谱的构建体系中数据是基础,而知识提取是实现知识图谱的最关键核心技术,由于达观在NLP领域长久以来的积累,能够对尤其是非结构化的长文本实现字、词、篇章级的分析与理解,通过自研的OCR技术结合实体识别技术能够对企业非结构化、半结构化等各类数据进行挖掘,自动提取出知识图谱所需要的三元组数据——边、实体、属性,为垂直行业知识图谱的知识构建提供有力的帮助。
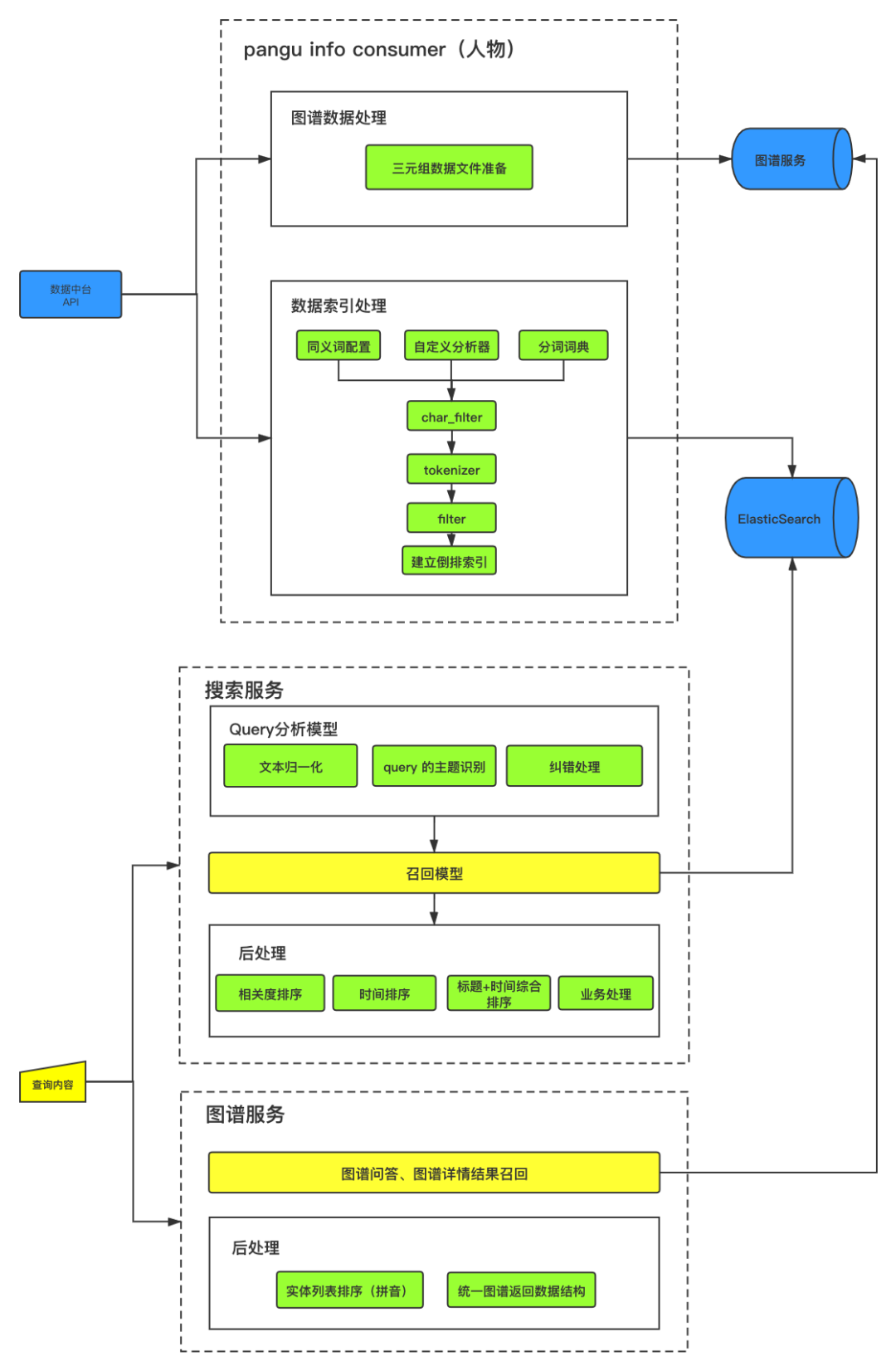
1) 通过数据接口获取到结构化数据。
2) 结构化数据经过数据加工、处理后转为图谱-三元组格式数据,通过图谱构建模块,把三元组数据转化为知识图谱。
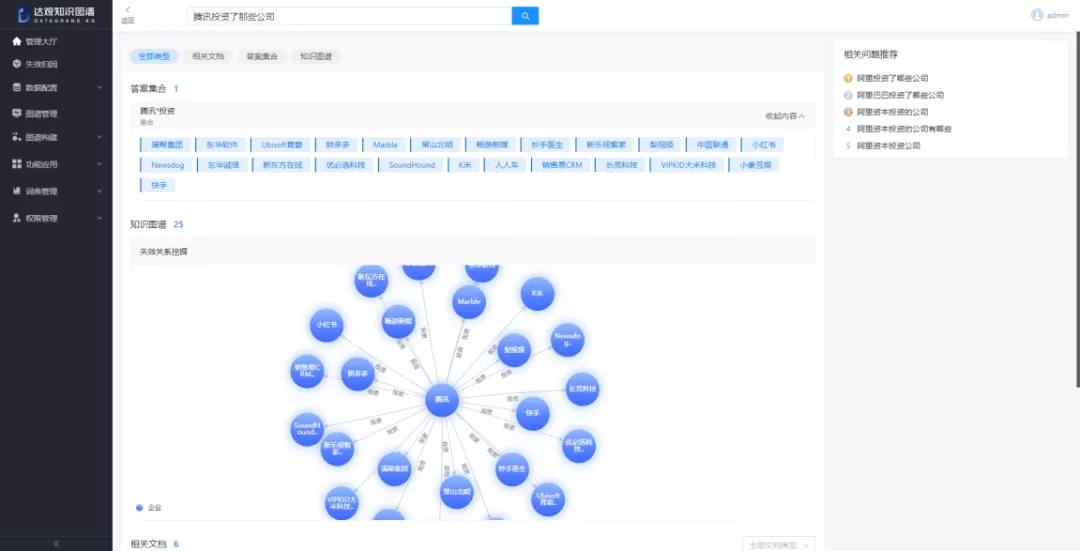
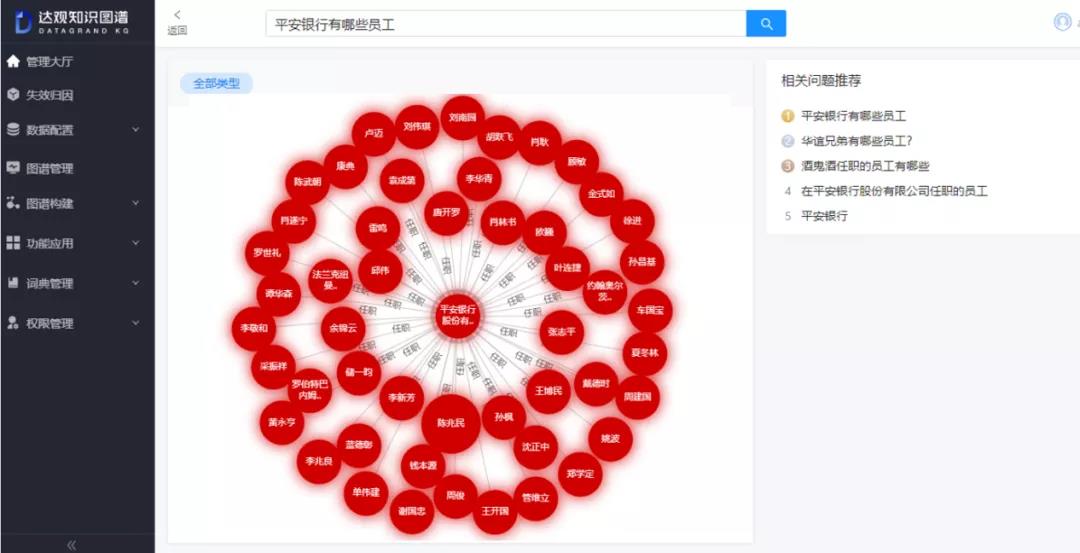
3) 当用户输入检索query时,经过query分析模块能够有效地识别用户检索的意图,如果分析出问句是想了解“人物与企业的关系”,那么会直接调用图谱知识问答服务,从而召回图谱结果,可以是实体、关系或者实体/关系的属性信息,当然也可以返回图谱节点,让用户更直观的看到知识。
那么以上的场景能够很直观的分析用户意图并结合知识图谱直接给用户返回答案,显然比传统的用关键字匹配的数据库查询、通用的检索系统更能满足用户的需求。
相信在未来,这种智能问答的工作模式和不断深入的知识管理方式将延展至更多应用场景,积极助力智慧企业建设。




