
IDC评估报告显示,全球超过80%的数据以非结构化形式存在,仅有0.5%的数据被分析运用,许多有价值的非结构化数据并没有得到有效利用。

不同数据来源通过不同的知识获取方式构建知识图谱
在医疗器械企业中存在着多源异构数据,各个数据模块间由于存储方式的不同,数据类型的差异等因素,使得原本存在关联的数据无法进行关联,进而形成了“数据孤岛”。应用达观知识图谱,能够将不同来源、不同结构的数据类型进行抽象建模,基于可动态变化的“概念,实体,属性,关系”数据类型,实现各类数据的统一自动化建模,同时实现知识搜索,问答,失效归因分析等功能,成功唤醒“沉睡知识”,为企业赋能。
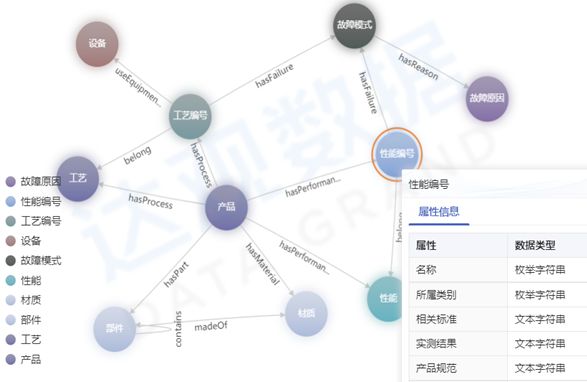
图谱的具体设计
达观数据基于丰富的业务场景经验发现,许多医疗器械行业由于产品研发的数据安全性以及知识产权等因素,在出现多源异构数据的“数据孤岛”问题的同时,还要考虑文档管理权限问题。仅限一小部分人员能够查阅全文并不是最优解,文档中势必会有能够开放分享学习的内容,例如在产品文档中提及的使用设备、检测工具等不敏感但可共享的知识。因此这导致了许多相通领域的技术与知识无法在企业内部进行充分的复用与流动,在一定程度上降低了工程师们对知识的检索效率,从而会减慢企业内部的医疗器械产品研发跟迭代进程。在图谱构建的过程中,首要的棘手问题就是多源异构数据的整合,其重点在半结构化数据与非结构化数据的结构化处理工作。达观知识图谱支持多种数据类型的接入如文档、图片、视频等,面对这些类型的数据,达观将采用自研的OCR技术进行扫描件中的文字识别,其准确率得到了众多用户的认可,以及结合达观数据自研的文本抽取与NLP技术能够高效的将半结构化与非结构化数据进行结构化从而完成显式、易理解、可推理、面向人的知识图谱,进一步实现自然人机交互与工作自动化。
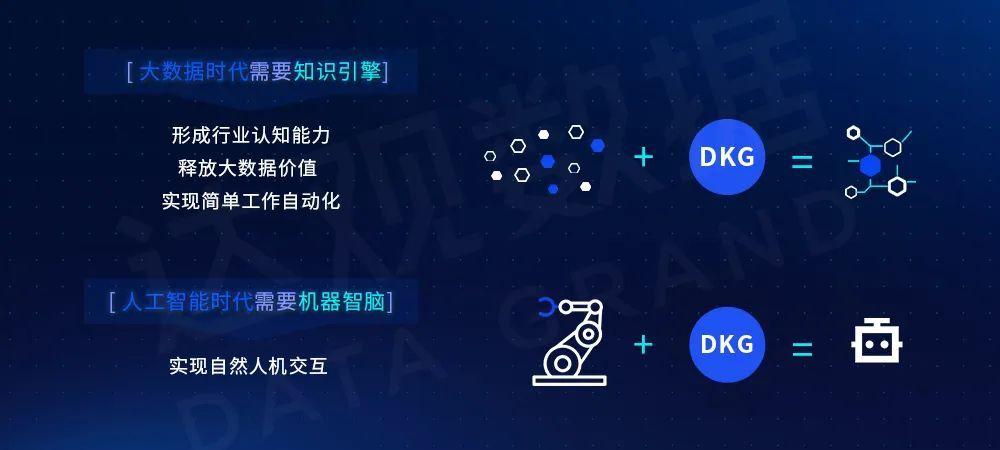
知识引擎与机器智脑
达观知识图谱根据企业的实际业务场景构建产品的细分知识库,将多源异构数据中有价值的数据知识以及历史经验进行提取,进一步构建医疗器械产品相关的知识图谱,再通过图谱产品的图谱搜索与智能问答等功能,使得工程师可以从海量且异构的数据中快速且准确的找到所需的数据,不仅充分利用了数据的关联性与相关经验的沉淀,还进一步的提升了企业内部的知识共享能力等软实力。
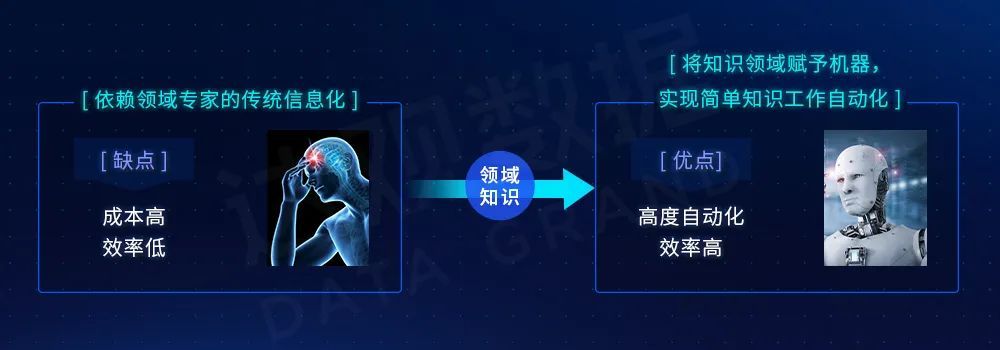
知识的积累与沉淀是智能化的必经之路
达观知识图谱构建时,在涉及敏感数据时与企业的权限管理保持高度的一致性,在拓展共享的同时兼顾权限收敛,可根据用户对敏感数据的实际权限来决定是否展示。例如,无权限的用户搜索某产品的文档数据时,为其展示部分脱敏数据。达观数据基于自然语言处理与知识图谱技术与企业携手构建的知识图谱平台,通过知识图谱的搜索、问答、可视化探索与文档溯源功能,为企业新入员工快速熟悉产品与老员工的知识沉淀,还可利用图谱进行数据分析,提升医疗器械的研发效率。与此同时,有效促进企业数据的标准化工作,为企业发展带来长远的影响。




