
本文整理自7月6日世界人工智能大会“垂直大模型重新定义知识管理”论坛上达观数据董事长兼CEO陈运文《垂直大模型与知识管理前沿发展与应用》的主题分享,分享达观在垂直大模型和知识管理方面的前沿应用和思考,以下为分享内容:
达观数据是一家专注于做智能文本处理的企业,根植在上海张江科学城。从2015年创办,到现在为止经历了很多年,也逐步建立起达观文档资料智能化处理全套产业链。
我们从底层,把各种各样企业文档资料汇总在一起,用数据基座管理起来。中间开发了很多AI能力,对这些文档资料做自动化处理。上面我们在构建各种各样应用系统,从基座到能力,再到应用,逐步形成了从下至上的三个层次工作。我也很荣幸在过去几年,达观成功成为行业首家国家级专精特新“小巨人”企业,目前在国内智能文本处理企业里面,我们市占率和案例数量也是领先的。
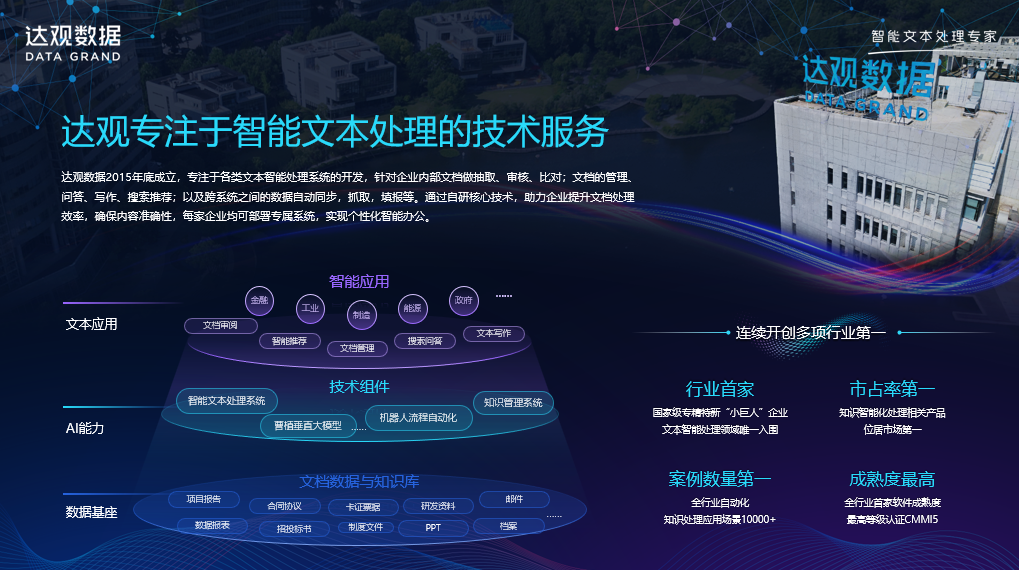
今天看到大模型时代,我们自己对这样的词有一个全新的解读,就是知识。我们解读了知和识。什么是知?今天把大量文档资料、语料汇集分析形成一个知识库,这是我们所有智能的来源所在。什么是识?我们用大模型技术对这些汇集起来的大量数据资料进行辨识和分析,进行理解,最后形成应用源源不断的智能来源。
在我们过去发展过程当中,思考达观定位在哪里?我们总结为垂直大模型,行业知识和场景化的文档处理,三个部分。我们讲垂直大模型是什么?是针对我们落地来用的,我们都知道所有这些模型最终在产业界落地的时候,是需要在一个、一个细分领域发挥作用。
我们针对垂直领域开发垂直产品,并且吸引垂直行业的合作伙伴一起帮我们营造大模型落地工作,这是我们达观的使命。另外知识,尤其是行业知识对我们来说非常重要,我们就要聚集特定数据开发特定功能,并且做特定任务的优化工作。场景化的文档资料处理是我们最后落地的环节,待会儿我会详细给大家介绍一下我们场景化文档处理工作。因为我们相信所有的工作最后都要落地,落地就需要相应的文档处理功能来承载。

也给大家汇报一下,达观“曹植”大模型在过去一年的发展。在去年世界人工智能大会上,我们第一次宣布“曹植”大模型。在过去一年中,自己在我们模型上也做了很多探索。参数规模逐步提升,目前现在主力模型参数规模已达到700亿。另外,我们在垂直领域,发现垂直语料和专业语料混合能起到比较好的实践作用。我们既需要模型有通识的知识,也需要垂直领域的专业知识,这种方式混合出来的模型性价比非常高,而且在专业领域的效能会更好一些。
指令微调领域,在过去一年时间当中,我们构建了一个比较好的指令微调数据级。我们有30%通用指令,大量常见日常常识和工作指令;20%是NLP任务指令,像抽取、分类等等,现在已经积累了100万微调指令;50%是垂直领域指令,这是垂直领域大幅度提升工作效能的关键。这三个结合在一起,能够比较好实现达观“曹植”大模型在垂直领域更好深耕。我们也很荣幸通过国家网信办第三批生成式人工智能服务备案,现在达观的“曹植”属于持证上岗的状态。
我们再介绍一下模型特点,我们模型强调多模型混合,兼容多种基座模型。我们觉得整个大模型生态,应该是一个兼容并包的生态。在实践过程当中,我们也积极探索能够把我们模型和其他行业里面非常优秀的基座模型融合在一起,比如说不久以前与百川智能也签了战略合作协议,我们很希望能够与行业里面非常优秀的基座模型相结合,取长补短,共同开发出垂直应用的产品。

我们垂直模型中开发了一个混合专家的架构,能够把不同领域里面非常优秀的模型融合在一起发挥作用。因为我们面向的是垂直产业端,垂直产业端有很多任务。有些任务是要做专业数据分析,有的任务是要做专业报告写作。这些任务之间是可以用不同模型,甚至有的是模型,有的是知识图谱,或者用业务规则的方式融合在一起,更好发挥作用。今天我们也非常有幸邀请到百川智能的邓江副总裁,待会儿一起参加达观的圆桌,跟大家来做分享。
在我们整个实践过程当中,在过去一年,我们的思考是,智能的知识库是实现AI落地应用的关键环节。在垂直领域里面,有多少垂直专业知识、垂直业务能力能够开发出优秀的垂直大模型应用系统。我们自己非常自豪在过去一年时间中,开发了达观优秀知识管理系统。今天也给大家正式宣布一下,基于我们垂直大模型和行业专业知识,开发了达观知识管理5.0版本,今天正式发布。

在开发我们智能知识管理系统的过程当中,其实也看到,作为今天垂直领域大模型应用的一个基础,需要开发各种各样原生的功能,其实非常重要。让这些功能真正变得好用、易用,我觉得才是垂直大模型落地的关键。
围绕知识管理,我们开发了很多功能。我们觉得这些功能每一个点看上去都很细小,但合在一起对我们每个组织、每个单位来说,就是一个大幅度提升工作效能非常好的方式。
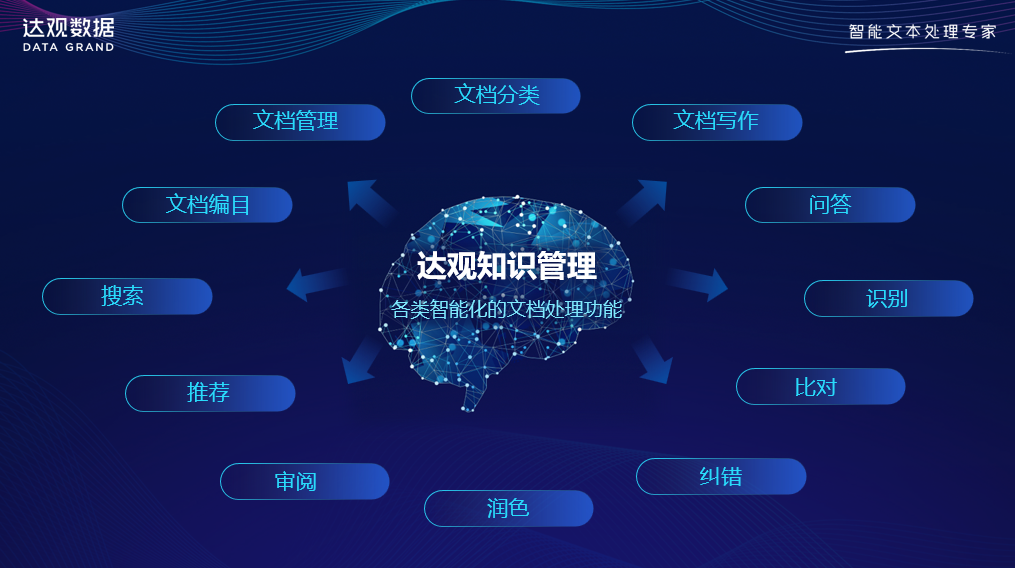
1文档汇集管理
很多单位在今天落地人工智能的时候,首当其冲要解决的问题并不是要搞一个高精尖的技术,而是怎么样把单位各种各样散落在各个地方的文档资料集中管理起来,因为知识沉淀在这些文档资料里面。很多单位的报告、资料、研发文档、技术报告、项目管理报告等等,它们可能散落在单位各种邮箱里面、OA办公系统、管理信息系统当中,现在需要能够把这些散落在我们很多人电脑里,或者很多系统里的文档资料汇总在一起,挖掘这些资料背后的知识,我觉得这个非常重要。
2自适应路由问答应用
大模型做问答是现在非常热门的一个方向,在问答领域里面,我们发现在一个单位内部,其实问答的答案来自于很多地方,只是一个简单的文档问答很难满足需求。我们开发了自适应路由问答应用,能够让计算机统一一个问答入口,但是背后走不同分支找答案。有的答案是在各种各样知识库里面,所以我们需要有知识库的问答。当我们知识库问答用相应技术去处理的时候,让计算机给我们问题找答案,并且可以把答案相关参考文档能够很好帮你找出来。在这种严肃专业领域里面,文档资料是否能找到它的溯源,是否能够真实可靠是非常重要的。
这个地方还有一个细节,我们在开发企业级文档问答的时候发现非常重要。我们文档问答时,它的答案是否有权限,这是往往会被忽略的问题。在一个单位里面,它的文档资料其实有很多种、很多部门、很多方面以及很多层级。不同的人对不同文档有不同的权利去访问。但是大模型在学习这些文档的时候,我们出这些问题答案的时候,一定要重视有些答案来自一些文档。比如有些单位有些重要的合同,合同重要的信息存在文档里面。如果有些人事没有权限访问,当他问来自这些合同问题的时候,这些答案不应该被大模型显示出来,所以就权限管理方向,在企业级问答里面是一个很重要的话题,我们也开发了相应技术,能够非常好实现对问答档案权限管控工作。
3垂直文档知识问答
我们可以针对一个比较长的报告、资料、文书,针对里面所蕴含的知识做这个问答的工作,比如可以选择特定上传文档,针对这个文档内容对它形成文档内容分析工作,并且可以针对所上传的文档,从里面进行特定知识问答和管理工作。今天运用大模型的归纳能力,可以非常好地针对这个文档形成大纲、思维导图,形成对这个文档和其他文档之间关联关系的分析工作。
4Text-to SQL
很多企业的数据其实沉淀在各种各样数据报表、BI系统,或者底层结构化关系数据库当中。我们这边开发了Text-to SQL,能够把自然语言的问题转化成SQL去完成。如果问一个公司的保费收入等情况,相应数据其实在各种后台数据报表当中。今天计算机要变成一个SQL语句,从里面读取相关数据,并且展示成相关内容。
5垂直文本写作
实现很多专业化文档写作,比如标书、债券募集书、审计报告、企业运营周报等等,这些是非常专业的报告。我们这个写作工作就是让AI自动去完成,同时右边有非常结构化的表格数据来做交叉印证。很多专业报告写作既要有优美的文字,同时也需要有非常严谨的数据,把这两种方式相结合,才能写出专业可用的报告。这是我们在垂直领域专业报告写作方面做的产品探索,我们认为也是非常好的一个落地场景应用。
另外,我们也介绍自己的创新功能。这些点看上去不大,但是其实非常有效。
1文档自动归类
很多单位里面不是说没有一个所谓传统知识库,它们传统知识库只是一个网盘,这个网盘里面汇集了大量资料和文档,这些资料和文档往往比较散乱。今天我们可以让大模型自动阅读文档资料,可以对文档形成多级标签体系,打上各种各样业务标签,能够对文档资料进行自动化归类工作。我们每个人电脑里面如果工作时间久了,是会有很多的文档,这些文档可能就“沉睡”在我们硬盘里面,今天我们可以让计算机帮你把这些文档资料井井有条地分类归纳好,分门别类地放到各种目录当中去,打好各种标签。这些对个人来说,以及对单位来说都是非常重要的事情。
2文档知识推荐
根据每个用户的兴趣、需求、历史行为,从大量文档资料当中筛选出相关知识点推荐给你。大家知道达观智能化推荐系统在行业中也是声名鹊起,服务了很多大型企业,为它们构建个性化推荐相关功能。今天我们也把大模型和个性化推荐结合在一起,以前是人去找知识,以后是知识去找人,知识去找到合适的人,并推荐给他。
3文档智能命名
智能命名工作是什么意思?我们在很多企业里面落地的时候发现,很多单位文档资料命名方式相对来说比较随意。大家一定见过很多文档叫1.PDF、通知.DOC、AA.tax等等,这些文档资料命名方式在新建的时候比较随意。我们还见过新建1.DOC,新建2.DOC。这么多文档资料的文件名,今天也可以让AI自动帮你做一个重写工作,更加有条理,能够把文档资料内容,计算机自动做理解后更新到文档名上,避免文档名大量重复和不方便事后管理工作,这些文档命名的方式也是我们在拓展的应用。
4文档知识提取
这在专业领域,尤其在金融领域里面非常有价值。很多资料和报告中有很多结构化的信息,我们让计算机自动解读出来,把里面结构化重要信息提炼出来以后,可以形成针对这个文档的知识卡片,方便我们快速定位和分析内容。
5文档去重检测
我们在很多企业档案库、知识库构建过程当中,我们也可以让计算机自动去找到重复的知识,分析工作,以及生成文档目录大纲相关工作,自动提取PDF大纲,方便浏览和定位。
6文档问答对提取
很多单位说要构建企业自动化问答对,把一个文档资料里面这些知识点自动形成相应问答知识库,方便人员来定位。
7专业文档审核
我们在证券领域做了很多,把投行规则、证监会文件指导要求沉淀到审核规则当中,提升我们文档质量控制工作。这边可以看到大模型可以给出很多结论、原因、审核要求,以及相应规范,帮我们人更好减轻我们写作质量的控制工作。
不管是在银行业,或者在证券业,还是在其他涉及资金管理方面,银行流水自动化核查工作都是我们今天在金融领域做大模型落地时很重要的一个环节。我们通过流水透视、欺诈挖掘、异常交易分析等等,可以更好从海量数据资料当中找到我们人眼很难归纳出来的规律,进行分析挖掘工作。
现在炙手可热的Agent相关技术,我们把达观RPA和大模型相结合,让RPA来实现双手的工作,让大模型实现大脑的工作,结合在一起打造我们智能化数字员工。大家知道Agent一定是未来我们白领生产力创造的很重要技术途径。最后Agent长什么样?怎么样才能够提升它的专业度?这正是我们在探索的,目前我们探索了一些工作。
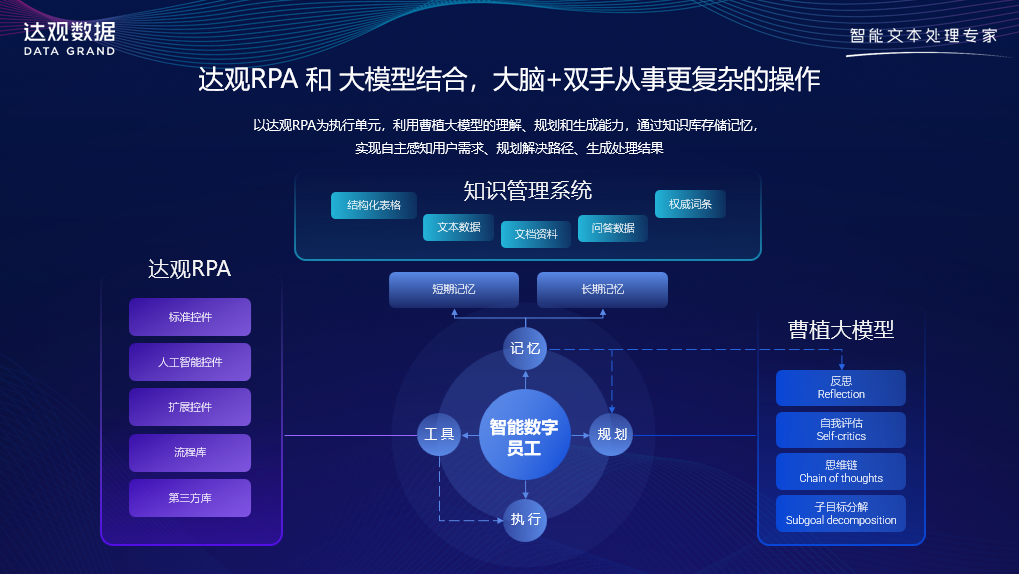
在今天RPA相关领域中,有很多聚集的Agent可以做很多专业领域工作。我们把大模型结合进去以后,可以更好进行任务调度、流程开发和任务执行工作,这些我们都在积极探索相关工作。相信未来垂直大模型和知识库结合以后,再加上今天RPA很多流程化的执行任务,可以把人从大量复杂日常工作当中解脱出来,我们认为这也是未来一个重要方向。
刚才大家也见证了我们与复旦大学、燧原科技、国泰君安证券,形成了一个非常好的金融垂直大模型产学研用发展链路。复旦大学负责模型研究工作,燧原科技提供强大的智能化算力,达观数据开发了非常接地气落地产品工作,最后在国泰君安证券场景应用当中,希望能做出很多应用探索工作。

最后,达观作为一家国内智能文本处理专业厂商,希望我们的技术能够赋能千行百业。我们今天的技术与一千年以前的活字印刷术是一样的,用新的科技手段带来文字资料处理的效率革命。我们相信这些技术能够在我们日常办公领域里面大放异彩,为我们每个人日常、每个单位未来工作提供智能化源源不断动力,期待我们未来提供更多、更优质的产品为大家服务。




