干货分享!手把手教你构建用于文本聚类任务的大规模、高质量语料
写在前面:本文旨在开源一个构建用于学习任务的的大规模中文语料(文件大小2G+,训练语料数量1000W+),基于此语料和对比学习模型,学习到的语义表示可以较好的捕捉到语句之间细颗粒度的主题相似度(Thematic Similarity),可应用于下游的文本聚类、问答匹配、语义检索和相同内涵语句识别等场景。
一、什么是语义关联性(Semantic Relatedness)
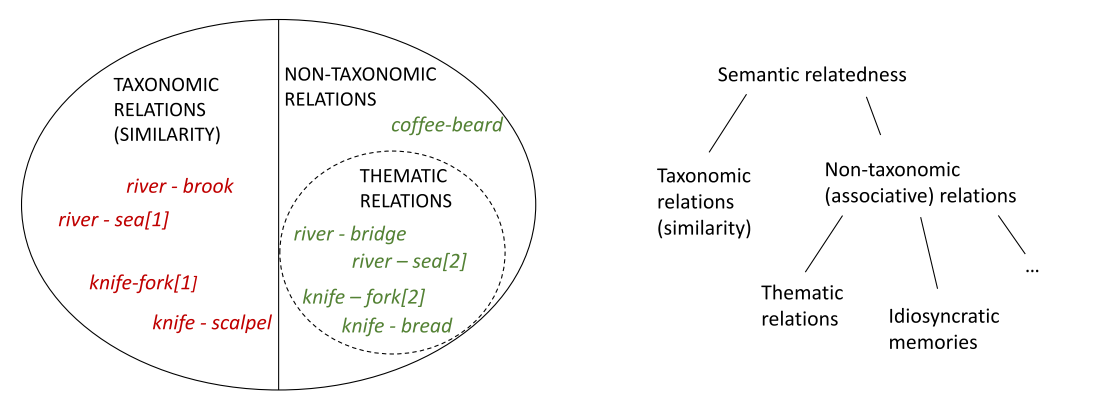
语义关联性(Semantic Relatedness)一般有两种情境 — 首先,概念可以是相关的,因为它们有许多共同的特征(考虑老鼠、鼹鼠、袋鼠等),这也意味着它们属于同一类别(Membership of Same Category)。根据不同的理论观点,这种类型的关联性被称为分类学相关性或相似性(Taxonomic Relations or Similarity)。第二,不同的概念(如鼠标和点击)被认为可能是相关的,因为它们经常在某种语境下共同出现( Co-occurrence )— 例如,在时间、空间或语言学等背景下的经常共现。由此产生的相关性通常被称为联想(Association)。本文的重点是一种特定类型的联想关系,即主题相关性(Thematic Relatedness)。
主题相关性是将在同一环境或语境中扮演不同的、通常是互补角色的概念联系起来。认知心理学有越来越多的研究表明,主题相关性对认知过程(Cognitive Processes)至关重要,可与分类学相关(Taxonomic Relations )并驾齐驱。
对一个概念的分类学分析(Taxonomic Analysis)关注的是概念的固有特征,而主题视角(Thematic Perspective)则是处理统一事件中概念之间的外部关系。概念之间的分类学关系是基于对概念特征的比较;属于一个共同的分类学类别的概念具有共同的属性或功能,因此倾向于具有物理相似性。相比之下,主题相关是在一个共同的事件或主题中发挥互补作用的概念之间形成的,这往往意味着这些具有不同(尽管是互补的)特征和功能。
-
语义关联性(Semantic Relatedness)
最广泛的类别,包括两个概念之间的任何类型的语义关系。
-
分类学相关(Taxonomic Relations)
关联性的一个子集,被定义为属于同一分类学类别,这涉及到具有共同的特征和功能。在许多文献中,这种类型的关联性经常被称为相似性。
-
非分类学相关(Non-Taxonomic Relations)
某些概念在某些语境下的因频繁的共现(co-occurrence )关系而存在/产生的关联性。
非分类学相关的一个子集,被定义为在事件或场景中的共现关系,这种关联下的词汇之间存在着互补关系。如“家具”这一主题下,“椅子”和“布置”,前者是物体,名词,后者是动作,是动词;前者是后者的动作被施加者,二者在语法层面和语义层面是互补搭配的关系,联合在一起则呈现较为完整的语义信息。
讲了这么语义关联性的话题,那它到底跟我们的NLP任务有何联系呢?
-
文本分类 – 根据定义,文本分类是基于机器学习/深度学习技术,按照一定的分类体系或标准进行自动分类打标签。它跟我们上面提到的分类学相关(Taxonomic Relations)直接相关。
-
文本聚类 – 文本聚类主要是基于无监督的机器学习算法,在不事先规定聚类数的情况下, 依据著名的聚类假设:同类的文档相似度较大,而不同类的文档相似度较小。它跟我们上面提到的主题相关(Thematic Relations)联系密切。
本文笔者主要关注的是文本聚类问题,笔者接下来将提到的、用于训练文本聚类高质量表示模型的wiki triplet三元组语料也是为该任务服务。
二、基于主题相似的文本聚类
( Text Clustering Based Thematic Relations)
文本聚类是一个被广泛研究的NLP问题,它有许多应用,包括协作过滤(collaborative fifiltering)、文档组织(document organization )和索引(indexing)。根据聚类目标的不同,文本聚类可以应用于不同层次、粒度的文本,即从词汇、语句、篇章再到完整的文档都可以作为文本聚类的输入。
在本文中,笔者关注的是基于主题相似性( thematic similarity)的语句聚类问题,目的是将讨论同一主题的句子组合在一起,而不是将具有同一内涵的语句聚合在一起的聚类任务。 举例说明一下:
-
越南发现新冠变异病毒混合体,易于空气传播
- 越南卫生部29号宣布,发现了一种可以通过空气迅速传播的新冠变异毒株,这一变种病毒具有最早在印度发现的毒株和最早在英国发现的两个变种病毒的双重特征。
-
越南此次发现的毒株更具传染性,并且很容易通过空气传播。
上面的语句讲的都是一件事,语义颗粒度较细,即新冠变异毒株在越南的传播。
-
第1集主要内容:1915年5月9日,袁世凯下令,同意与日本签订丧权辱国的二十一条。根据这个条约,中国承认日本继承德国在山东的一切权益,日本在中国南满和蒙古东部享有特殊权利,日本获得在中国多条铁路建筑权等等。北洋政府的卖国行径遭到全国民众的强烈反对,全国各大城市都举行了声势浩大的示威游行。流亡海外的孙中山、黄兴等人呼吁革命者回国倒袁。
-
第2集主要内容:陈独秀归国,汪孟邹、陈子寿等人为其接风洗尘。在饭桌上,众人探讨当下局势,陈独秀指出如今所面临的强敌不仅是强在武力上,更强在思想和理念上。为此陈独秀决定创办一份杂志,作为唤醒国人政治觉悟和伦理觉悟的号角,从而探索出一条振兴中华的道路。
-
-
第42集主要内容: 李大钊在北京长辛店分发《新青年》的刊物,并为众人讲述五一国际劳动节的由来,他告诉大家美国的劳工游行示威要求每日工作八小时,呼吁工人们也要团结起来为了自己的权利而奋斗。此外,中国共产党第一个早期组织在上海成立,陈独秀等人志愿加入中国共产党。
-
第43集主要内容:周恩来将陈独秀寄来的刊物拿给延年乔年,延年和乔年已经发现了无政府主义是行不通的,他们已经通过反复研读马克思主义的刊物确认了马克思主义才是中国的救国之路,决心与无政府主义彻底决裂。
上面的句落讲的都不是一件事,但都属于同一主题— 即《觉醒年代》的剧情简介,但语义颗粒度较粗。
基于主题的文本聚类有许多使用场景。比如,在多文档摘要(multi-document summarization)任务中,人们经常从多个文档中提取句子,这些句子必须被组织成有意义的章节和段落。同样,在新兴的计算论证(computational argumentation)领域,论点(arguments)可能在广泛的文章集中被发现,这就需要进一步的主题组织(thematic organization)来产生一个有说服力的论证叙述( argumentative narrative)。
三、基于中文Wiki构建可用于
训练主题相似语义表示规模的大规模语料
一言以蔽之,笔者创建的语料是一种弱监督(Weakly-Supervised)形式的三元组 (Triplet),即(Anchor,Positive,Negtive),包含锚定语句、正例语句(与锚定语句内容存在主题相似的语句)和负例语句(与锚定语句内容不存在主题相似的语句),需与对比学习任务结合起来使用。
据笔者观察,维基百科的行文组织良好、有逻辑,关于人、事、物的介绍通常会划分为若干个(固定)版块(sections )和段落(paragraphs),每个版块/段落下辖的内容具有高度一致性,而段落于段落之间往往是统一大主题下的小分支,主体内容会有差异。
举例来说,“2019冠状病毒病”的文章布局如下,分为若干个大的版块:
“名称”段落下的内容组织:
2020年1月初,由于肺炎病例原因不明,并正进行病原鉴定及病因溯源等初步调查,因而武汉市卫生健康委员会称之为“不明原因肺炎”[56]。
1月8日,香港特区政府卫生署将其命名为“严重新型传染性病原体呼吸系统病”(Severe Respiratory Disease associated with a Novel Infectious Agent) [57][58]。卫生署在新闻公报中则称为“新型冠状病毒感染”[59],后改称“2019冠状病毒病”[60]。澳门特别行政区政府将其命名为“新型冠状病毒感染”[61]。
2月11日,世界卫生组织正式宣布将此疾病定名为“2019冠状病毒病”(Coronavirus disease 2019,COVID-19),表示在定名时须在名称中使用“既不涉及地理位置、动物、个人或人群,又容易发音,并且与该疾病相关的名称”,以避免造成其他可能不准确的或污名化的名称的问题[14][66][67]。
2019冠状病毒病的症状及严重程度因人而异,本疾病存在无症状感染者[72],有症状患者主要以轻症居多(约81%)[73]。大多数患者的表现以类流感症状为主。发热是2019冠状病毒病最常见的症状[31],可能是高烧或低烧[31],大多数患者都会在某一阶段出现发热[31]。大多数患者也有咳嗽症状,可能是干咳或排痰性咳嗽[31]。
严重并发症包含急性呼吸窘迫综合征(ARDS)[79]、败血性休克、全身炎症反应综合征(SIRS)[79][80]、难以纠正的代谢性酸中毒、急性心肌损伤、凝血功能障碍,甚至死亡等[81]。
疾病潜伏期通常约在暴露后4-5天左右,一般认为不会超过14天[82]。97.5%的患者会在感染后11.5天内出现症状[83]。目前认为无症状患者也具有传播疾病的能力[84]。
2020年8月,南加州大学的科学家报告称,2019冠状病毒病的初始症状的“可能”顺序是先发烧,然后是咳嗽和肌肉疼痛,恶心和呕吐通常出现在腹泻之前[85]。这与流感最常见的途径形成鲜明对比,即先咳嗽后发烧[85]。
由上可见,版块/段落之间的内容的主题相关性较弱,而版块/段落内的语句内容之间存在高度的主题一致性,且粒度较细。
据此,笔者将按如下方式、步骤来构建主题Triplet,对于某一个词条页面所呈现的内容:
1、在同一段落的任一两个句子为正例,其中一个为anchor,另一个为positive;2、和anchor、positive相异的段落下的任意一句为negtive;
3、考虑到后续训练模型的效率和学习效果,我们需要谨慎挑选负例,即选择困难负例(hard negtive);考虑到词条谋篇布局的规范严谨性,anchor和positive所在段落的前后相继的段落中的任意语句可作为hard negtive。
4、为避免模型学习到固定模式,即干扰信号,hard negtive需要随机在上一段和下一段中生成。
5、过滤掉一些大事记之类的词条,此类词条乃综合性词条,按时间组织,内容主题方面千差万别,无一致性,无学习意义;
6、去掉过短(少于10字)和过长的语句(多于256字)。
由此,大批量triplet就生成了 -(anchor,positive,negtive),1000W+个triplet。
- ( ‘新文化运动为五四运动做了思想上和组织上的预备’,’关于新文化运动与1919年的五四运动的关系有不同看法[17],一种意见认为二者基本是一个运动的两个阶段,可以统称为广义的“五四运动”,或者“五四新文化运动”’,
‘1915年9月,陈独秀在上海创办《青年杂志》,1916年改名《新青年》,刊物上还印有法文刊名La Jeunesse’),
- ( ‘自然语言处理(英语:Natural Language Processing,缩写作 NLP)是人工智能和语言学领域的分支学科。’,’自然语言处理包括多方面和步骤,基本有认知、理解、生成等部分。’,
‘在口语中,词与词之间通常是连贯的,而界定字词边界通常使用的办法是取用能让给定的上下文最为通顺且在文法上无误的一种最佳组合。在书写上,汉语也没有词与词之间的边界。’),
- ( ‘次年其弟陈乔年亦遇害。两兄弟均被安葬在龙华烈士陵园’,’1927年6月26日,陈延年被自己的老师吴稚晖背叛,在上海北四川路恒丰里104号中共上海区委所在地被国民政府逮捕,陈延年拒绝招降。’,
‘ 陈延年,又名遐延,笔名林木,男,安徽安庆人,中国共产党早期领导人之一,陈独秀长子’)
笔者自己基于中文wiki百科生成了一个训练语义模型的语料,用于多个NLP任务,都取得了不错的效果:
Top 5 most similar sentences in corpus:
某男子正在吃意面 (Score: 0.8763)
一个人在吃食物 (Score: 0.6450)
一个男人正在吃一块面包 (Score: 0.5701)
一个男人骑着白马在一个封闭的地面上行走 (Score: 0.1964)
-
相同表述语句对齐(从大量无序文本中找到语义最接近的语句对)
学富五车 博学多才 Score: 0.7170
油嘴滑舌 油头滑脑 Score: 0.7159
戮力同心 举国同心 Score: 0.7118
戮力同心 同心同德 Score: 0.7109
招贤纳士 博学多才 Score: 0.7092
自以为是 师心自用 Score: 0.7045
-
基于语义相似度阈值的聚类(设定相似度阈值和最小聚类成员数实现自动聚类)
A total of 40 clusters were automated detected~
账单15.84,忘记还款,扣我15的违约金,太狠了点吧?唉,不敢用你们的卡了
就差15块多没还,肯定是忘了,违约金太狠了吧,不合理
我是忘还了,英该提醒一下,你们直接扣我15元,我不想用你们的信用卡了
Clustering done after 0.36 sec
Kacmajor M, Kelleher J D. Capturing and measuring thematic relatedness[J]. Language Resources and Evaluation, 2020, 54(3): 645-682.
Dor L E, Mass Y, Halfon A, et al. Learning Thematic Similarity Metric Using Triplet Networks[J].