
本文摘自达观数据出版书籍《智能文本处理实战》3.3.3
 表格区域检测是指从文档中定位出表格区域。早期研究中,表格区域检测多应用在电子文档中,比如PDF文档、Word文档等。随着图像采集技术的发展,表格区域检测更多应用在自然场景中,比如手持拍照等扫描件。
表格区域检测是指从文档中定位出表格区域。早期研究中,表格区域检测多应用在电子文档中,比如PDF文档、Word文档等。随着图像采集技术的发展,表格区域检测更多应用在自然场景中,比如手持拍照等扫描件。
基于传统的区域检测算法
与国内相比,国外的表格检测技术起步较早,早期方法可分为基于规则启发式算法和简单的机器学习算法。基于传统的区域检测算法首先使用图像处理方法对文档进行预处理,然后利用表格布局特征或者PDF编码信息得到线条、文本块等视觉信息,最后定位出表格区域。
Watanabe、Hirayama 等人首先对文档图片进行预处理,利用形态学方法获取文本块等信息,然后利用文本块、水平线和垂直线来定位出表格区域。Ramel等人利用线条信息来定位出表格区域,首先寻找表格区域顶部的第1条水平线,然后通过匹配9种框线相交情况中的4种“T”字形模板来检测其他线条。Kieninger、Dengel等人指出线条不能作为表格的必备特征,认为表格列之间具有不相交的特性,可以利用列与列之间的空白信息定位出表格区域。
表格检测技术在国内起步较晚,早期的研究主要是解决PDF文件中的表格定位问题。最有代表性的是Fang等人提出的基于表格线条特征及页面分隔符的方法。该方法首先会对PDF文件进行协议码解析以获取页面的线条信息,然后会使用规则方法对页面布局进行分析,获取页面分隔符,最后会基于线条信息,利用形态学方法定位出表格区域。该方法仅适用于有线表格区域检测。利用线条检测表格区域的流程如图1所示。
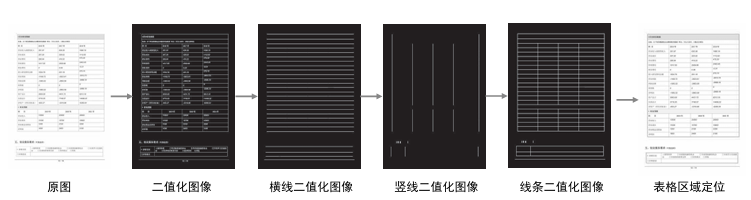
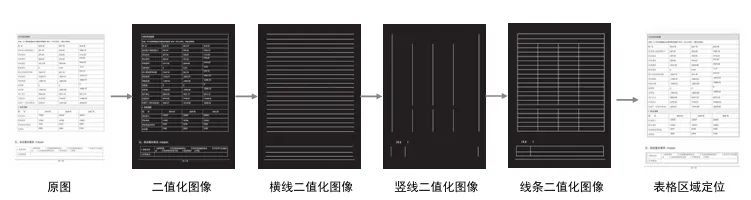 图1 基于线条的区域检测算法流程
图1 基于线条的区域检测算法流程
基于深度学习的区域检测算法
随着人工智能技术的飞速发展,深度学习在图像的语义分割、目标检测等任务上取得了优异表现。越来越多的研究学者将语义分割或目标检测技术应用到表格区域检测任务上。
01
基于目标检测的算法
Schreiber 等人使用Faster R-CNN 算法模型来检测表格区域。Gilani等人在采用相同的目标检测网络的同时,还使用了3种距离变换方法对页面的图像特征进行增强。经过微调后的模型不受表格结构和布局变化的影响,并且适用于更多的数据集进行目标检测。
Huang 等人使用YOLOv3网络来检测表格区域,对算法中的锚点进行了适应性调整, 并在后续处理中过滤了检测框的空白区域,以减少噪声对表格区域定位的影响,进而提高了表格区域检测的准确率。
Sun 等人采用无锚点的目标检测算法来检测表格区域,该算法基于CornerNet的思想定位出表格的4个角点位置,并且利用角点对扭曲表格进行矫正,以提高后续表格结构识别的准确率。
02
基于语义分割的算法
He 等人采用多尺度特征,利用FCN(fully convolutional network)定位出文档中的表格、段落及图像区域,然后通过形态学、CRF等获得表格区域。
03
基于图网络的算法
Zhang 等人提出了VSR(vision, semantics and relation)模型。该模型融合了视觉和语意信息,以图像及文本信息作为输入,利用双流网络提取出视觉和语意特征,然后将特征送入多尺度自适应的聚合模块中,最后利用GNN模块对视觉及语义特征的关系进行建模,最终生成结果。




