

北京时间晚上十一点,突然电脑右下角的QQ弹出了一条消息,”在?”
都9012年了还会有人单独发个”在”然后人就失踪了?有事情找就直接说事情嘛,你不说事情,我怎么知道我应该”在”还是应该”不在”呢?
鼠标移动到右下角准备点击”取消闪烁”时发现,是小美。
感觉空气中突然弥漫着一种说不明的东西,还是忍不住回复了一句,”在,什么事情?”
“你明天下午一点方便使用电脑吗?”
唉,有什么事情为什么不可以一口气说完呢,为什么总要说半句呢,如果我在这个人面前我肯定一个大嘴巴子上去了。但,这是小美。”方便”。
“我明天选修课要抢课,你方便的话帮我一下呗,我和朋友约了出去玩了。”
果不其然,在我学会了如何修电脑、如何恢复数据、如何下载视频等技能后,又有新的技能树即将需要被点亮。不过区区抢选修课能难到我?我不仅要抢到,还要抢得漂亮,抢得安逸,抢得让自己都佩服!
“No problem!抢课地址,账号,密码,课程名。”
这干脆利落的语气,完美。
抢课只是一件小事,无非是打开浏览器,等时间到了疯狂点击。但想必大多数人都在大学时候有过惨痛的经历,无外乎学校网络太差,热门课程抢的人数太多自己不一定能抢到。同样,我也并不能保证自己在第二天下午一点的时候盯着屏幕不停地点,或者舒服一点用鼠标连点器不停地点,就能很大可能地抢到需要的课程。
学校的网络没法拯救,只能拯救自身的网络;抢同一门课程的人数多,我们就需要开更多的窗口去抢!
很好,看来我们需要搞定一段自动抢课的代码,然后在自己机器上部署、在舍友机器上部署、在云环境部署、在网络好的其他机器部署,想必这总能最大可能性抢到想要的课程了吧。
我仿佛看到了一个幕后黑手看着自己的屏幕嘿嘿嘿地笑着:
王小明 世界电子竞技 抢课中...
吴小杰 芭蕾舞艺术 抢课成功
陈小龙 基础烹饪知识 抢课成功
刘小乡 莎士比亚戏剧选 抢课中...
...
抢课,我从来没怕过谁。
此前在学习python爬虫的时候接触过selenium的知识,完全可以适配这样浏览器操作场景。
可以先用selenium写一个操作浏览器抢课的脚本,再用flask来接收外部的请求命令执行对应的抢课脚本,用docker打包成镜像,再到能暂时操作的所有电脑,云服务器部署一套。
等快到抢课时间了,安安心心躺在椅子上,执行一下批量发送请求的脚本,就可以静待抢课成功的好消息了。
我只想发出三个字的声音:还!有!谁!
官网介绍
can be controlled by many programming languages and testing frameworks.
Selenium 官网:http://seleniumhq.org/
Selenium Github 主页:https://github.com/SeleniumHQ/selenium
百度百科
Selenium是一个用于Web应用程序测试的工具。
Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。
测试系统功能——创建回归测试检验软件功能和用户需求。
支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
功能
框架底层使用JavaScript模拟真实用户对浏览器进行操作。
测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。
使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。
使用简单,可使用Java,Python等多种语言编写用例脚本。
简单来说,起初selenium是一套用于web自动化测试的工具,其本身具备了对多种浏览器/操作系统的兼容支持,且能通过多种语言进行操作控制。但其强大的功能不仅仅适用于web自动化测试领域,同样也被广泛地使用在爬虫以及rpa(Robotic Process Automation)相关的业务场景上。 而我们现在需要实现的可以说就是一个简单的rpa功能。
笔者开发环境:Mac OS、PyCharm、python3.6、chrome
笔者提供的测试网址:www.uncleyiba.com
该网址可自行注册,或者使用测试账号nvshen/nvshen
因为是沿用的很久之前刚接触tornado时候的代码,所以对tornado的使用有一些误解。[1]
因此可能导致如果多人使用线上测试环境,会有一些问题出现。
所以建议可以本地启一套测试环境。
测试网站及selenium脚本源码:selenium_example(https://github.com/uncleYiba/selenium_example)
使用方式见readme.md
对于selenium而言,需要实现我们的需求,着重要关注两点:
1.页面元素定位
是否能准确获取到我们需要进行操作的元素
2.页面元素操作
点击、填入、清楚内容、获取数据、双击、按住、松开、拖动等
既然是操作浏览器进行需求实现,那我们必然要对前端有一些了解。也就是说html和js相关知识需要有一些涉猎,另外需要会操作chrome的开发者工具,即Mac的option+command+i,或者是windows的F12。
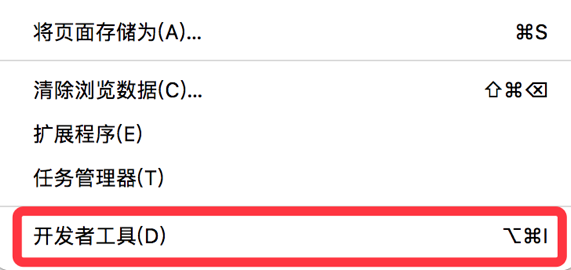
首先点击红色按钮,再选取需要定位的具体元素信息,即可获取到该元素在html页面中的所有信息。
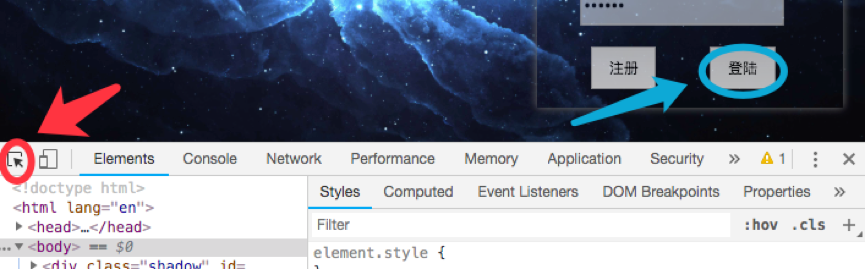
以登陆按钮为例,我们发现其并没有设置id属性,但是其onclick触发的方法直接表现了出来,我们便可以通过两种方式触发对应的登陆事件。可以根据class_name,tag_name等来获取元素并执行点击事件,或者可以直接执行login()的js从而触发登陆事件。
selenium提供了一系列的方法通过元素的属性定位页面中的具体元素,其属性包括并不仅限于id、name、class_name、tag_name、xpath、css_elector等,通过WebDriver对象我们可以调用对应的find_element_by方法。例如以下html代码:
<input type="button">登陆</input>
我们获取其元素的方法就是find_element_by_id,其他具体的可用方法列表如下:
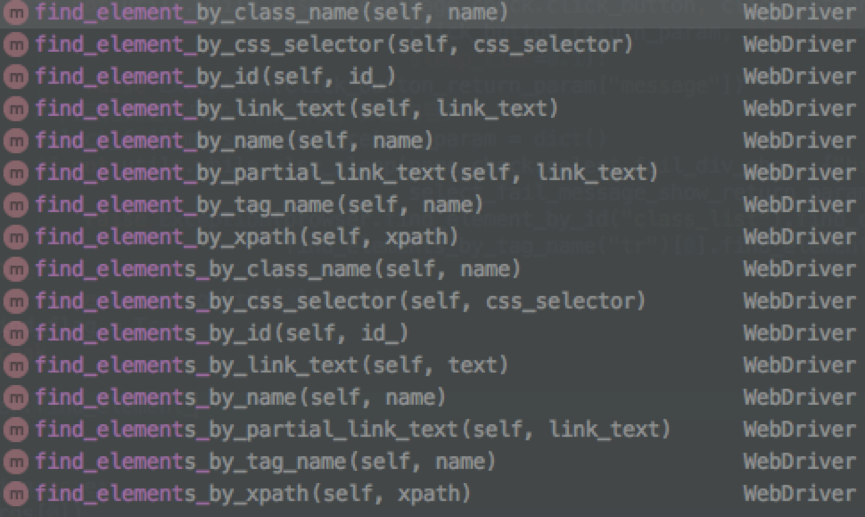
如果方法名中只是”element”则获取到的是单个元素对象,而如果是”elements”的话则获取到的是该种类对象的一个list集合。
对于单个元素对象而言,其所有可执行方法或属性如下:
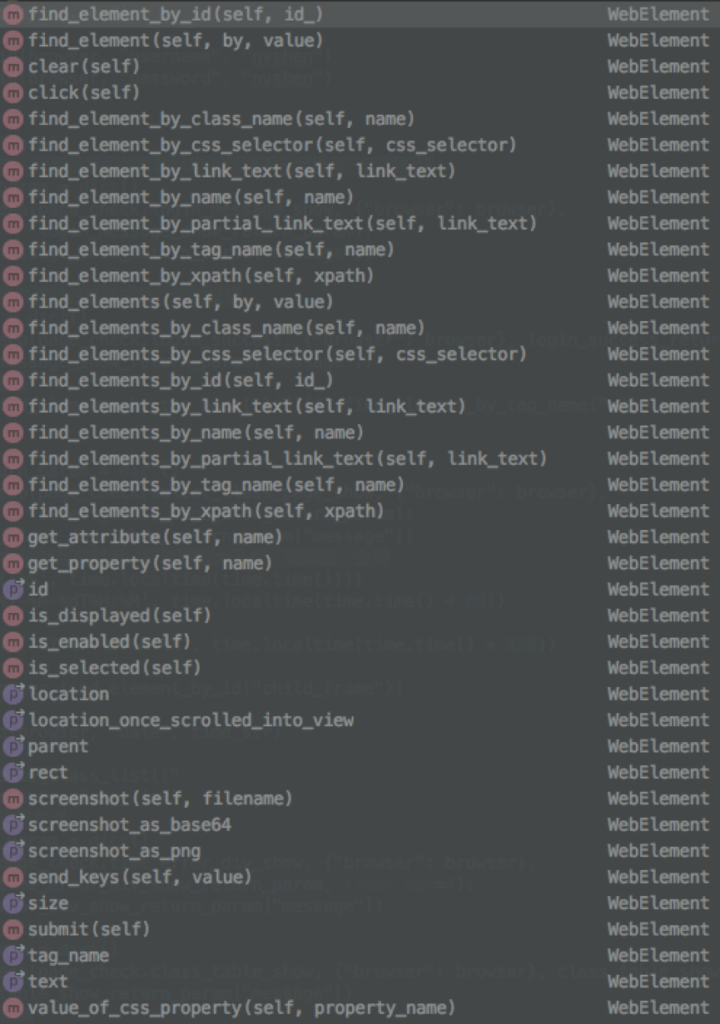
从列表中我们可以清晰地看见单个元素对象也具有find_element_by的一系列方法,意味着我们可以定位一个父元素,再通过父元素定位其子元素,一层一层定位准确。
常见的html元素包括:输入框input,按钮button,复选框checkbox,单选框radio,下拉选择框select,时间选择框date,富文本框textarea,文件选择file以及一些用于显示文本的标签包括不仅限于div、span、p等。
输入框input:
<input type="text" name="last_name">
需要实现对其输入的功能,可使用如下代码:
browser.find_element_by_name("last_name").send_keys("测试文本")
按钮button:
<button onclick="alertDiv('提交成功!')">提交</button>
需要实现对其进行点击的功能,可使用如下代码:
browser.find_element_by_id("submit")[1].click()
复选框checkbox:
<input type="checkbox" name="q1" value="0">一
<input type="checkbox" name="q2" value="1">二
<input type="checkbox" name="q3" value="2">三
<input type="checkbox" name="q4" value="3">四
需要实现对其value=0和value=1复选框的选中功能,可使用如下代码:
browser.find_element_by_name("q1").click()
browser.find_element_by_name("q2").click()
单选框radio:
<input type="radio" name="team" value="0">是 <input type="radio" name="team" value="1">否
需要实现对其value=0,显示为”是”的单选框的选择功能,可使用如下代码:
browser.find_elements_by_name("team")[0].click()
下拉选择框select:
<select name="gender">
<option value="0">男</option>
<option value="1">女</option>
<option value="2">其他</option>
</select>
需要实现对其下拉选项”男”的选择功能,可使用如下代码:
时间选择框date:
<input type="date" name="birthday">
需要实现对其时间的输入,可使用如下代码:
PS:鉴于各种日期控件比较多,个人使用看来直接使用js对其赋值是一种比较方便的方式
富文本框textarea:
<textarea name="textarea"></textarea>
需要实现对其输入的功能,可使用如下代码:
browser.find_element_by_name("textarea").send_keys("测试文本")
文件选择file:
<input type="file" name="file">
需要实现文件的选择功能,可使用如下代码:
browser.find_element_by_name("file").send_keys(file_path)
至于其他一些用于显示文本的标签,例如:
<span >嬴政</span>
需要实现对其文本内容的获取,可使用如下代码:
text = browser.find_element_by_id("name").text
至于元素的点住,松开,拖动等操作将结合在实际案例的代码中。
测试网站可见上面开发及测试环境介绍章节介绍
1.打开对应的测试网站www.uncleyiba.com
option = webdriver.ChromeOptions()
option.add_argument('disable-infobars')
browser = webdriver.Chrome(chrome_options=option)
browser.set_window_size(1500, 1000)
browser.get("http://www.uncleyiba.com")
其中第二行代码加或者不加的区别仅仅是打开的浏览器会不会显示如图所示的信息:
通过这段代码我们操作成功打开一个1500*1000大小的chrome浏览器并打开了http://www.uncleyiba.com这个网站
2.输入用户名和密码,并点击登陆按钮
# 填入用户名和密码
utils.write_into_input_by_id(browser, "username", "nvshen")
utils.write_into_input_by_id(browser, "password", "nvshen")
# 执行登陆js
js_login = "login()"
browser.execute_script(js_login)
这里我们输入了对应的用户名和密码,并且通过执行登陆按钮的js代码实现登录,而并不是通过点击登陆按钮的方式
其中write_into_input_by_id方法具体代码如下:
def write_into_input_by_id(browser, ele_id, content):
ele = browser.find_element_by_id(ele_id)
ele.send_keys(content)
找到对应的id的input元素并向其中输入指定的文字
3.等待三秒钟网页跳转,并确保成功跳转
if not utils.while_else_sleep(page_check.login_message_show, {“browser”: browser},
login_message_show_return_param):
raise Exception(login_message_show_return_param[“message”])
time.sleep(3)
# 三秒之后会刷新页面,要确保页面是否已经刷新成功,否则报错
login_success_return_param = dict()
if not utils.while_else_sleep(page_check.login_success, {“browser”: browser}, login_success_return_param):
raise Exception(login_message_show_return_param[“message”])
在执行页面跳转的时候总会因为网络或其他原因,导致其中的延时时间具有不确定性, 可能你一个请求发过去是毫秒级响应,也有可能过十几二十秒都没有反应, 这时候我们需要一个延时等待的机制来尽可能规避这种情况, 这里是通过写了一个简单的函数while_else_sleep来监控页面的状态, 从而实现对页面的加载等待。
def while_else_sleep(func, param, return_param, false_func=nothing_happened_func, times_begin=0, times_max=20, sleep_time=1): ''' :param func:重复执行的方法 :param param:func方法携带的参数 :param return_param:func方法返回的参数 :param false_func:如果func返回结果为false,需要执行的函数 :param times_begin:开始的次数 :param times_max:最大重复执行次数 :param sleep_time:每次等待时间 :return:boolean ''' times = times_begin while True: #print("{0}:{1}[max:{2}]".format(func, times, times_max)) times += 1 if func(param, return_param): break else: time.sleep(sleep_time) false_func(param, return_param) if times >= times_max: return False if return_param.get("status", "") == "over": return False return True
我们通过判定函数func来判定页面是否已经到达了我们预料的状态。如果没有,则进行对应的延时等待,并进行重试补救操作false_func。当重试超过一定的次数times_max,则判定此次操作是超时的,没有继续重试的必要了。当然在确定页面状态的过程中可能会出现一些不再需要重试的情况,比如”密码输入错误”, 这种情况你再怎么重试密码也依旧是错误的,所以我们会在return_param中加入status判定, 如果碰到类似于这种情况则直接执行跳出操作,并判定执行失败。
理解了while_else_sleep函数再来看这个部分的整体函数,就很容易理解其含义:
确保弹窗是登陆成功状态,如果是则等待三秒,确认已经登陆成功并跳转到了预期的页面。
4.点击”定时抢课页面”
# 找到对应的 定时抢课页面 的a标签
select_class_a = browser.find_elements_by_tag_name("li")[0].find_element_by_tag_name("a")
select_class_a.click()
# 判定子页面是否刷新成功
select_class_page_show_return_param = dict()
if not utils.while_else_sleep(page_check.select_class_page_show, {"browser": browser},
select_class_page_show_return_param):
raise Exception(select_class_page_show_return_param["message"])
这里触发了一个点击a标签的事件,实现iframe的跳转,并且通过一个while_else_sleep函数对iframe的页面跳转状态进行了判定
5.切换到对应的iframe进行抢课
# 切换iframe
browser.switch_to.frame(browser.find_element_by_id("child_frame"))
这里仅仅是一个切换frame的操作,除了同标签页面内的frame切换,selenium还可以在同一个浏览器窗口的不同标签之间进行切换
6.根据当前时间设定课程开抢时间,并将这个时间传给对应的时间控件
# 设置好开抢时间 如果秒数小于40 那就当前时间,如果秒数大于40,则推迟一分钟
second = int(time.strftime('%S', time.localtime(time.time())))
time_str = time.strftime('%Y-%m-%dT%H:%M', time.localtime(time.time() + 60))
if second >= 40:
time_str = time.strftime('%Y-%m-%dT%H:%M', time.localtime(time.time() + 120))
# 填入日期
utils.write_into_date_by_id(browser, "date", time_str)
这里我们首先获取了当前时间,并且在当前时间的基础上对课程开抢时间进行了相应的延长, 这里有一个注意点是我们设定的时间传参格式是%Y-%m-%dT%H:%M,原因如图:
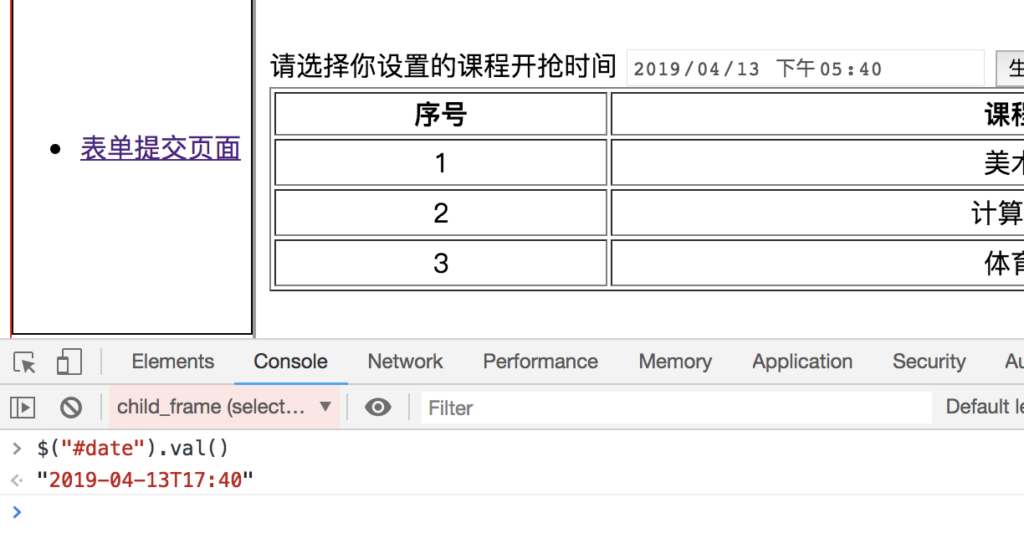
我们在获取date控件的样例时间格式的时候获取到的就是这样的格式, 因此我们再反过来进行赋值的时候要以同样的格式构造对应的时间值。不以特定的格式进行赋值则会引发js的错误。

7.点击”生成抢课列表”
# 点击 生成抢课列表
js_create_class_list = "create_class_list()"
browser.execute_script(js_create_class_list)
# 判定一下是否出现弹窗表示时间选择有误
time_error_div_show_return_param = dict()
if utils.while_else_sleep(page_check.time_error_div_show, {"browser": browser},
time_error_div_show_return_param, times_max=4):
raise Exception(time_error_div_show_return_param["message"])
# 判定table是否已经展示出来
class_table_show_return_param = dict()
if not utils.while_else_sleep(page_check.class_table_show, {"browser": browser}, class_table_show_return_param):
raise Exception(class_table_show_return_param["message"])
这里的点击操作我依旧是采用的执行js的方式,我们可以查看对应的button的代码:

当然可以通过xpath或tag_name的方式获取元素再进行点击,这个因个人的习惯不同选择的方式也不一样。
在进行js执行/按钮点击之后,我增加了一步判定,以免上一步时间设置出错导致抢课列表不能成功生成。
而在确定时间没有出错之后生成抢课列表也是需要一定时间的(当然我这里是js直接生成的写死的列表, 实际必然是实时向服务器发送请求获取到对应的列表,所以会有一定的请求时间),所以我们进行了延时等待的判定。
8.不停地点击某个课程的”抢课”按钮,直到抢课成功
# 选择我们需要的课程 例如 计算机课
trs = browser.find_element_by_id("class_list").find_element_by_tag_name("tbody").find_elements_by_tag_name("tr")
find_flag = False
for each_tr in trs:
tds = each_tr.find_elements_by_tag_name("td")
if tds[1].text == "计算机课":
# time.sleep(1)
left_time_str = tds[3].text
pat_num = "d+"
result_pat = re.findall(pat_num, left_time_str)
if len(result_pat) > 0:
left_time = int(result_pat[0])
click_button_param = {"browser": browser, "button": tds[2].find_element_by_tag_name("button")}
click_button_return_param = dict()
if not utils.while_else_sleep(page_check.click_button, click_button_param,
click_button_return_param, times_max=(left_time+3)*10,
sleep_time=0.1):
raise Exception(click_button_return_param["message"])
# 判定抢课是否成功(有无弹窗,弹窗内容)
select_fail_message_show_return_param = dict()
if not utils.while_else_sleep(page_check.select_fail_div_show, {"browser": browser},
select_fail_message_show_return_param, times_max=4):
raise Exception(browser.find_element_by_id("class_list").find_element_by_tag_name("tbody").
find_elements_by_tag_name("tr")[0].find_elements_by_tag_name("td")[3].text)
else:
raise Exception(tds[3].text)
find_flag = True
break
这里我们获取了所有课程的信息,并通过对td内容的判定找到了我们需要的计算机课,进一步找到其抢课按钮。
通过获取了剩余时间,计算出假设我们每秒点击十次的话需要点击多少次 (超时过多之后的点击可以有但是没必要,反正也抢不到了)
全部次数试完之后再判定一下是否抢课成功,即识别是否有弹窗以及弹窗的内容是什么
除了抢课案例外笔者还提供了另一个可供测试的表单提交样例, 其中包括了更多的元素操作:input填写,select选择,date填写,radio选择,checkout选择,file选取, textarea填写,元素拖拽,按钮点击这些事件。
表单提交页面的进入和选课类似,这里不做重复介绍。大多数元素的操作在之前的章节中也有介绍,方法大同小异参考一下源码即可理解。
这里重点提出来的则是元素拖拽的演示。
在表单提交这个案例中笔者增加了一个类似于验证的机制,需要将黑色小方块移动至几乎与红色小方块重合的地步,才可以进行最终的提交。

其中小方块这一段的html代码是这样的:
<td colspan="2" >
<div style="left: 44.6836px; top: 24.9741px;"></div>
<div style="left: 342px; top: 593px;"></div>
</td>
css:
#div1{
width: 30px;
height: 30px;
background-color: black;
position: absolute;
}
#div2{
width: 30px;
height: 30px;
background-color: red;
position: relative;
}
两个小方块都是30*30大小,其中红色方块是可不操作的,其位置在这个td内部随机。黑色方块有初始位置,可以进行拖拽移动。
其实现代码如下:
# 拖动验证
# 1.分别得到两个div的left和top
div1 = browser.find_element_by_id("div1")
div2 = browser.find_element_by_id("div2")
left_div1 = div1.location.get("x")
top_div1 = div1.location.get("y")
left_div2 = div2.location.get("x")
top_div2 = div2.location.get("y")
# 2.设置好ActionChains对象用于进行键鼠操作
actions = ActionChains(browser)
actions.click_and_hold(div1) # a.按住div1
actions.move_by_offset(left_div2 - left_div1, top_div2 - top_div1) # b.横纵坐标移动(相对坐标)
actions.release() # c.释放鼠标
actions.perform() # d.执行动作流
ActionChains类可以实现对一组”动作”的执行,它有如下的”动作”可以被执行:
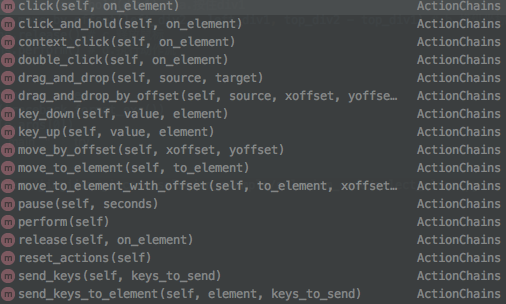
包括不仅限于单机,双击,按下,松开,移动等。
这里我们通过计算了两个方块的相对位置,点击并按住小黑方块(div1), 并将其移动相应的相对距离,再释放鼠标这样的操作,来实现”让小黑方块覆盖小红方块”的验证操作。
其中browser为浏览器对象
在服务器执行selenium脚本的时候我们无法直观地看到当时浏览器执行的情况, 因此需要对代码执行异常的地方进行捕获,通过截图的方式来人为分析可能出现的错误。
browser.get_screenshot_as_file(screenshot_path)
screenshot_path:截图图片存储路劲
这一步实际上是基于上一个”页面截图”进一步对图片进行处理,这主要用于验证码的获取, 大多数网站的验证码并不是一个真实存在的图片文件,而是一个实时生成的临时图片文件。因此我们需要通过截图的方式来获取这样的验证码并且利用OCR进行进一步的识别。
#得到验证码在屏幕中的坐标位置
left, top, right, bottom = get_elementid_location(browser, "checkCodeImage")
# 浏览器页面截图并存储
screenshot_path = os.path.join(conf.data_path, picuniqid + "_screenshot" + ".png")
browser.get_screenshot_as_file(screenshot_path)
# 存储验证码图
captcha_path = os.path.join(conf.data_path, picuniqid + "_captcha" + ".png")
im = Image.open(screenshot_path)
im = im.crop((left, top, right, bottom))
im.save(captcha_path)
其中get_elementid_location方法是根据元素的location和size方法获取其在屏幕中的坐标
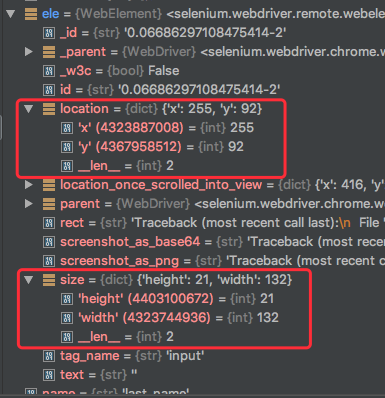
这其中有一个值得关注的问题是retina屏幕的问题
所谓“Retina”是一种显示标准,是把更多的像素点压缩至一块屏幕里,从而达到更高的分辨率并提高屏幕显示的细腻程度。
由摩托罗拉公司研发。最初该技术是用于Moto Aura上。这种分辨率在正常观看距离下足以使人肉眼无法分辨其中的单独像素。也被称为视网膜显示屏。
以MacBook Pro with Retina Display为例,工作时显卡渲染出2880x1800个像素,其中每四个像素一组,输出原来屏幕的一个像素显示的大小区域内的图像。
这样一来,用户所看到的图标与文字的大小与原来的1440x900分辨率显示屏相同,但精细度是原来的4倍,但对于特殊元素,如视频与图像,则以一个图片像素对应一个屏幕像素的方式显示。
故不会产生Windows中分辨率提升使屏幕文字与图像变小,造成阅读困难的问题。这样在设计软件时只需将所有的UI元素的精细度都提高到原来的4倍就可以既保持了观看舒适度,又提高了显示效果。关于iOS设备,也由四个像素代替原来一个像素,通过下图对比就可以较明显地观察到这种关系。
划重点每四个像素一组
所以如果selenium是在mac的主屏或者说是其他retina屏幕上工作的时候我们需要将其获得的元素坐标乘上2才是其真实的坐标:
if is_retina_display(browser):
left = int(captcha_location['x'] )*2
top = int(captcha_location['y'] )*2
right = int(captcha_location['x'] +captcha_size['width'] )*2
bottom = int(captcha_location['y'] + captcha_size['height'] )*2
else:
left = int(captcha_location['x'])
top = int(captcha_location['y'])
right = int(captcha_location['x'] + captcha_size['width'])
bottom = int(captcha_location['y'] + captcha_size['height'])
得到了屏幕截图和元素位置,通过Image类的操作即可以准确获得想要截图的元素的位置
这个也是配合截图使用的,因为截图仅仅是截取当前的屏幕,如果页面可以向下滚动或者向上滚动,则被隐藏的部分无法被截图获得
js_scroll='''$(document).scrollTop({0})'''.format(scroll_num)
browser.execute_script(js_scroll)
其中scroll_num即滚动条的位置,0则代表是在最上方
1.获取元素是否显示、是否可被操作、是否可进行选择

2.获取元素的标签属性,例如获取其name属性
name = ele.get_attribute("name")
ele为元素对象
3.获取元素的css属性,例如获取其color属性
color = ele.value_of_css_property("color") ele为元素对象
4.清除元素的值
ele.clear()
ele为元素对象
北京时间凌晨五点,我完成了对docker镜像的最终测试,并临时借用了朋友的高宽带服务器部署了自己的服务。
北京时间下午一点零一分,成功抢到了课程。
就像花瓶碎了一样,感觉一切顿时有点索然无味。
当然,以上都是假的。
但那些真的,也不知不觉就这样过去了很多年,却又像就发生在昨天。
而今天,我在达观数据,它就像初生的太阳,你又在哪里?
BOUT
关于作者
景健:达观数据后端开发工程师,负责达观数据产品后端开发、产品落地、客户定制化产品需求等设计。爱好数学,喜欢用代码解决生活中的实际问题。




