
在达观数据举办的自然语言处理学术交流研讨会,有幸邀请到中科院自动化所副研究员刘康老师前来作客活动现场,并和大家分享了《文本到知识,开放域知识抽取研究新进展》的主题报告。以下为现场分享内容整理,内容略有删减。

大家好,我报告的题目是“文本到知识,开放域知识抽取新进展”。大家也意识到最近一段时期大家都在谈论知识对我们有什么用,各行各业都在探讨如何构建知识图谱,帮助我们在自然语言处理领域上理解得更加精准,可以上升到以后的推理方面的相关内容。
先举个例子来看看知识对自然语言处理有什么用。比如说外交部发言人华春莹讲的“孟晚舟事件是引渡条约滥用,敦促美方纠正”。机器是否能够理解话并且正确回答问题呢?
已有的处理方式都是做分词、标注、实体识别。识别出华春莹是谁,孟晚舟是什么样的事件,实际上我们需要外界知识辅助我们。我们知道句子中的“外交部”是指中国外交部不是美国外交部,我们知道华春莹是外交部发言人。我们知道孟晚舟事件,我们也知道条约具体内容指什么,美方可能指美国政府。这样才能把知识串联起来帮助我们理解这句话的意思。

除此之外,我们要回答这句话也要有一些常识,比如说一个国家外交部敦促另外一个国家的时候,一般是立场持反对立场。这样才能帮助我们正确回答问题。
我们现在所做的知识不是特别全,我们需要实体知识,这是我们做的最多的,包括各个行业需要建立实体的关联。除此之外我们需要有事件知识或场景知识,在各行各业、各个场景下,需要制定场景知识。比如完成定机票的任务,这个场景下需要提供用户信息:目的地、身份证号、时间、地点、航班公司等。这些就是一些场景知识。
更重要的是常识知识,常识知识是在大量的文本中,目前来说对于常识怎么解释仍然是科学研究中面临的问题,还没有很好的方法把这些常识精准地表现出来,更不要说把这些常识提取出来。
从我个人来说知识图谱和知识有区别,知识图谱是知识的一种表示形式,是由描述实体间关系的三元组构成的知识网络。具体而言,是把非结构化的文本知识结构化。如果知识图谱可以理解成一个数据的话,可以说这个数据是一个学习型的。
谷歌提出Knowledge Graph的概念,往前看更多的是研究知识定义方面的内容。目前图谱基本定义是由一些关系确定的,通过这样的表述对一些事实信息有结构化的描述。
正如前面所述,知识图谱的基本组成单位是三元组。如:奥巴马和米歇尔是夫妻关系,用三元组的形式来表示这个知识则为:奥巴马-夫妻关系-米歇尔,这个三元组也构成了知识图谱中的一条边。
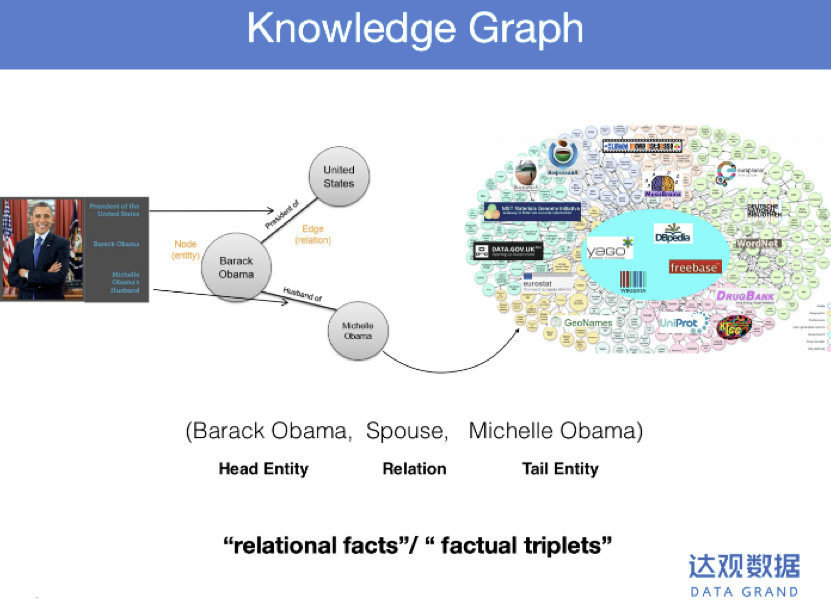
应用知识图谱的第一步是构建知识图谱。构建知识图谱的重点在于三元组抽取,即FactualTriplets Extraction。

我们有一些文本,然后把它们标注成序列样本,再之后通过一些模型做一个抽取器,用抽取器把文本信息自动抽取出来。
模型的特征能否自动抽取,减少人工参与?同时在数据标注方面,不可能每个不同领域都去标注数据,有没有自动的方法可以本身我们获取更多的标注数据?
首先看模型,五年前传统的方法已经不再用了,现在基本上是用神经网络方法来学习语言的表示,包括识别的方法。
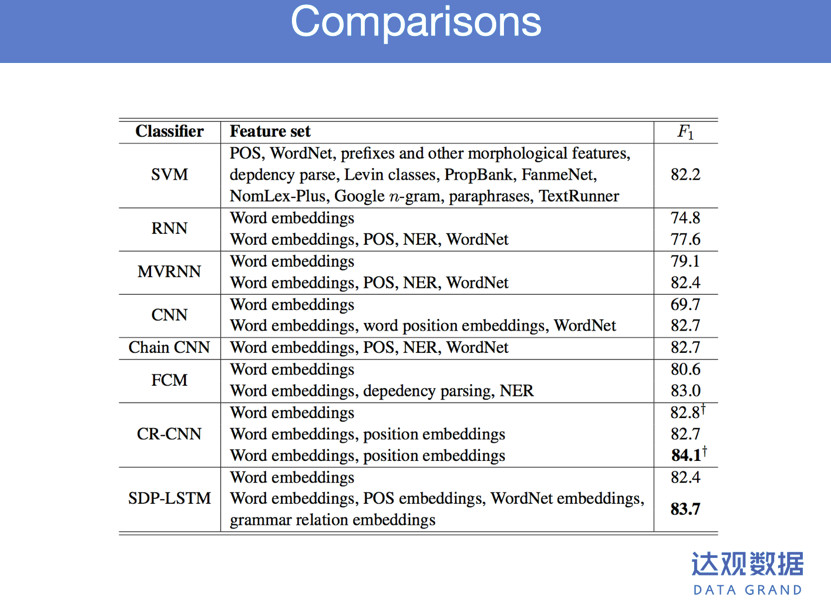
这个表是两年前的,可能现在数据比这个更高,神经网络方法比传统方法效果更好,而且是双向的,在抽取方面达到最好。信息网络研究有几个关注点,第一个关注点是怎样更多获取信息帮助理解这些话的内容。上面一些句法信息、语言信息能够嵌入神经网络。最新的研究是基于图的神经网络,帮助捕获更多的信息,帮助更加精准的学习句子的语义。
学习过程中,怎样更加捕捉句子背后的知识,或者外部已有的知识如何嵌入神经网络中,帮助学习文本表示或者句子的语义。
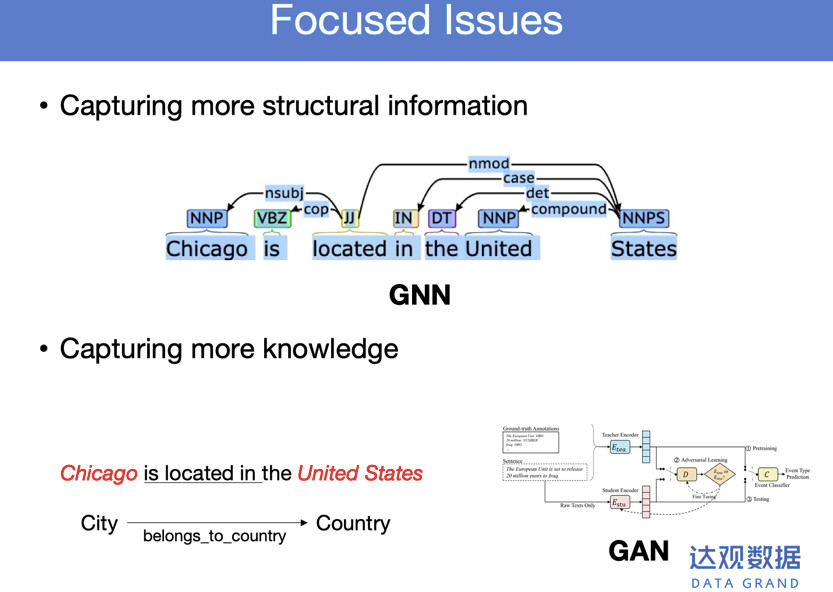
举这个例子,这个句子,如果我事先已经知道芝加哥是一个城市,United States是一个国家。在训练过程中,通过对抗过程,嵌入到表示中去。
在训练数据生成,大家做过机器学习和深度学习的可能知道,数据的规模和质量对效果的影响要大于模型本身,或者说用远程监督方法产生大量数据。举个例子,已有这样纪录,现在想抽取更多信息,应该用回标方法产生大量数据。当然这样的方法,可能会回标错误。
既然训练数据是有噪声的,怎样在有噪声的数据下用一些学习算法,减少训练模型的影响?
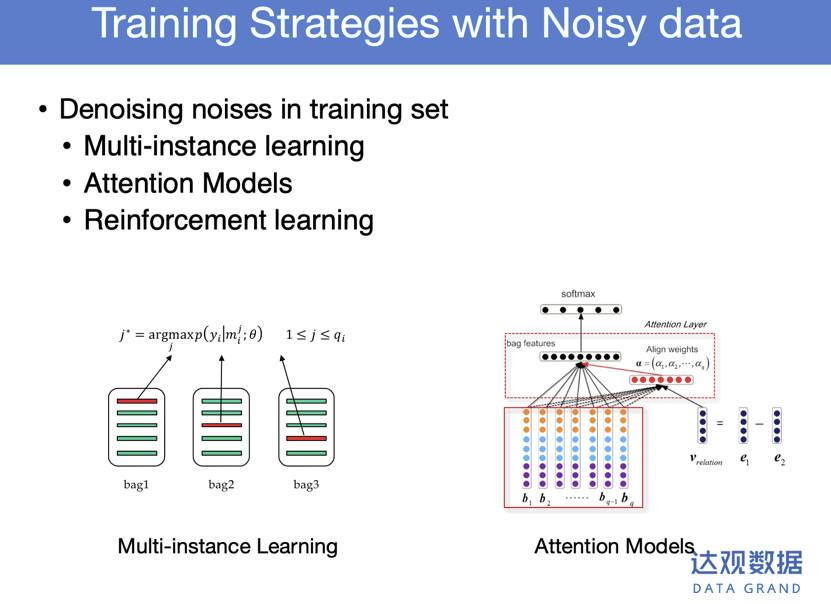
后面还有Attention Models和Reiforcement learning,即每次参与训练的时候只有一个样本参与训练。Reiforcementlearning一个比较小的权重,训练模型还是有一些影响的。能不能把对的样本挑出来,Reiforcement learning用强化的过程中自动选择它认为对的样本。现在看到的知识抽取,基本上是训练数据和模型选择上,就这两大类的想法。
后面我们自己做的工作和我自己最近的一些思考。我们想把模型更往实用化角度做,传统做关系抽取或者说三元组抽取,往往经历两个步骤。
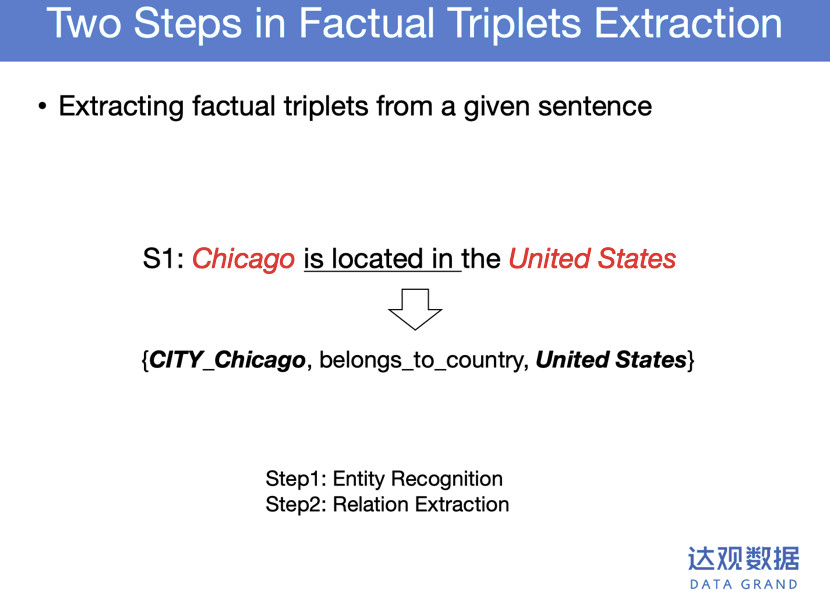
比如上图这句话,我们要抽取这个三元组,第一步要做实体知识识别,第二步采取关系抽取,来判断这两个实体之间满足什么关系。这样做可能会有一个错误,实体识别不一定百分之百准确,关系抽取也不一定百分之百准确。是否一种方法把实体识别和关系抽取同时进行?这样可能会更加实用化。

我们在很多句字里不仅仅有一个三元组,可能会有多个三元组,而且三元组中间可能有重叠现象。比如第二句话这两个三元组可能有两个关系,多三元组的情况下,如果进行很好的抽取?这是我们需要考虑的一个问题。
所以我们要考虑两个问题:第一个问题能不能把句子的实体和关系联合抽取?第二个问题,如何把句中多个三元组进行一次性的抽取?
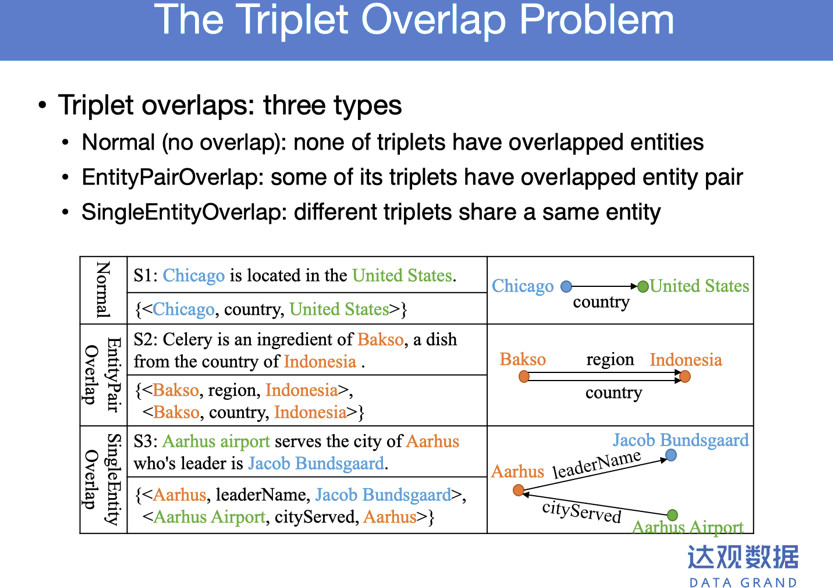
根据句子中三元组是否存在重叠,可以分为三类:第一类为Normal,无三元组重叠;第二类是Entity Pair Overlap,实体对的重叠,句子描述了一对实体间的两个关系;第三类是Single Entity Overlap,单实体重叠,句子描述了两个三元组,两个三元组存在公用实体。
最常见的传统方法先抽取实体,再识别关系。但是我只是训练过程中用一些方法把这两个任务放在一起。抽取过程中还是先抽取实体,再抽取关系。
2017年有一个最新工作,是把这个任务看成序列标注的任务,就是一句话给每个词打标签,这些标签体现了一些结构。

比如说这句话,有两个三元组,第一个三元组是川普是美国总统。第二个三元组是苹果这段。会打一些标签,这些标签是说同时把这种实体识别和关系抽取放到一起做。比如说B-CP-1,另外一个是表示E-CP-1,B表示一个实体开始,CP表示这之间的关系,1表示某一个三元组的第一个实体。后面的川普会打S-CP-2,S表示当前这个词是单独的实体,CP也是这之间的关系,2表示是某一个三元组的第二个实体。
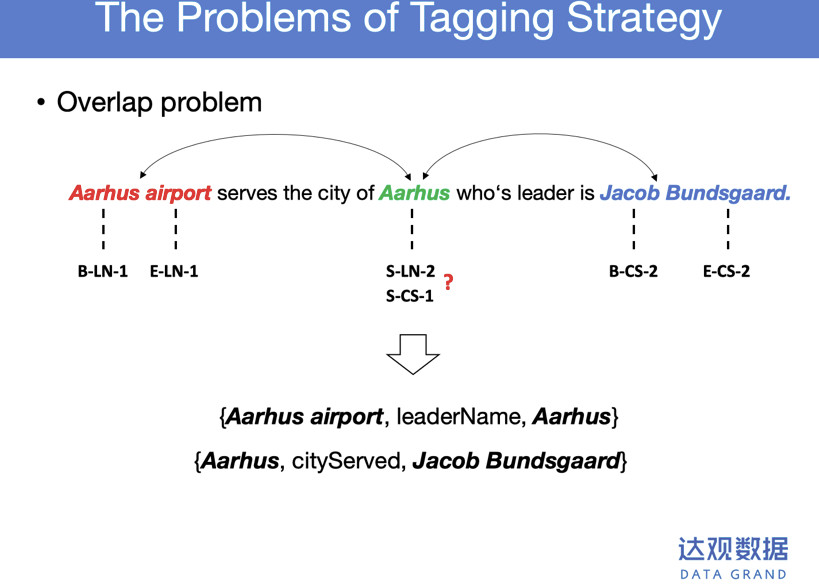
运用这样的方法把一些句子全部系列化标注,把实体关系抽取出来,这样可以解决多个三元组抽取的难点问题。这样的问题带来的难点问题是什么?比如不能解决一些Overlap的一些问题。
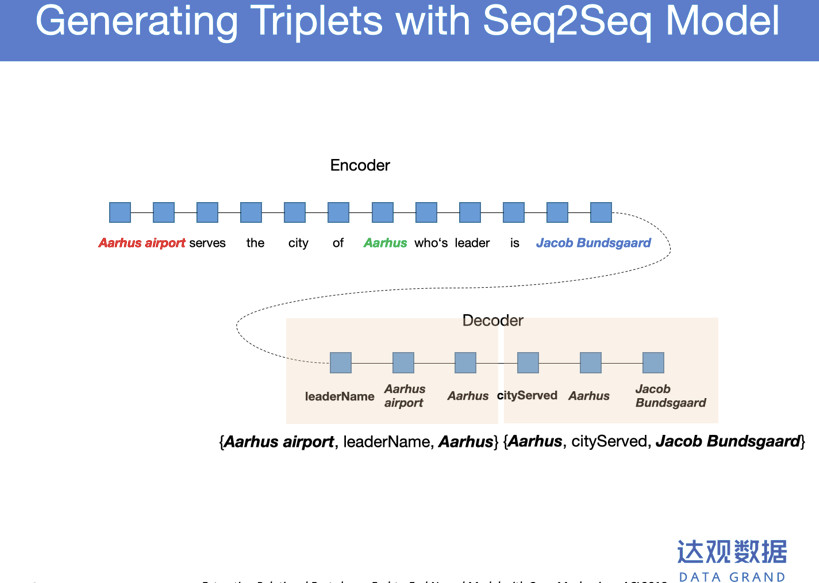
自动从自然语言句子中把三元组生出来,带来的好处是可以用大量的数据进行训练。比如说这样一句话,分成两个阶段,第一个阶段是Encoder,在这个Encoder可以把三元组依次生成,先生成第一个三元组,有三个节点,第一个节点生产关系,第二个节点生产实体,第三个节点生成实体2。然后再生成第二个三元组。当进入NA的阶段,就代表结束了。用这样的方法完全可以解决Overlap。
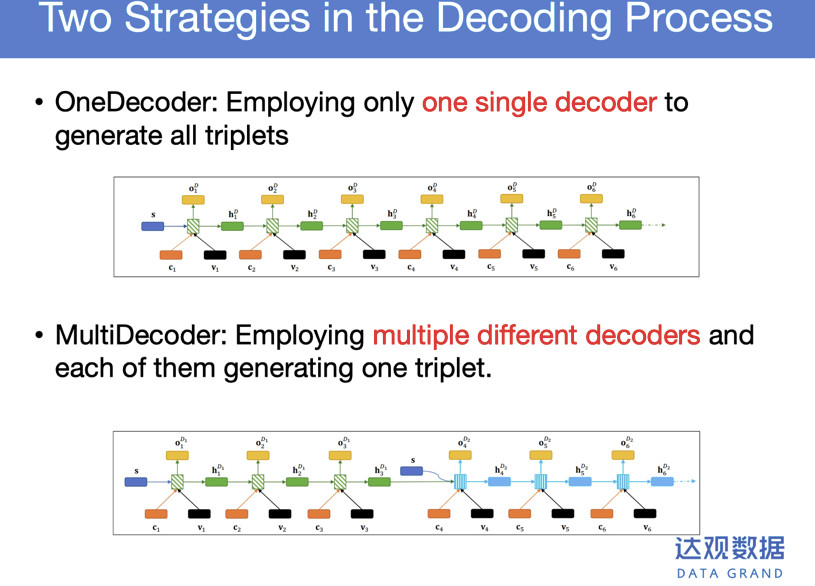
具体怎么做?这里设计了两种,一种是OneDecoder,第二种是MultiDecoder。这样不断的简单迭代、生产。简单看一下结果,有两个数据上做了这个实验。
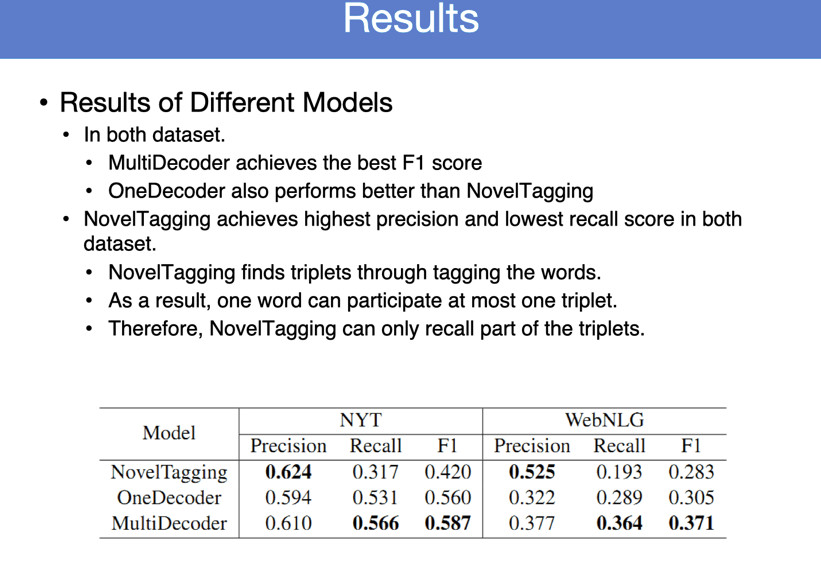
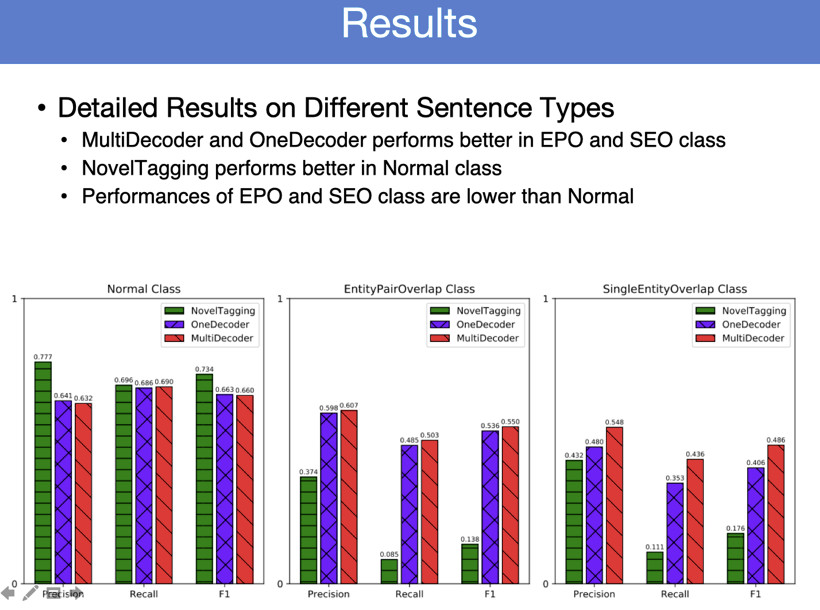
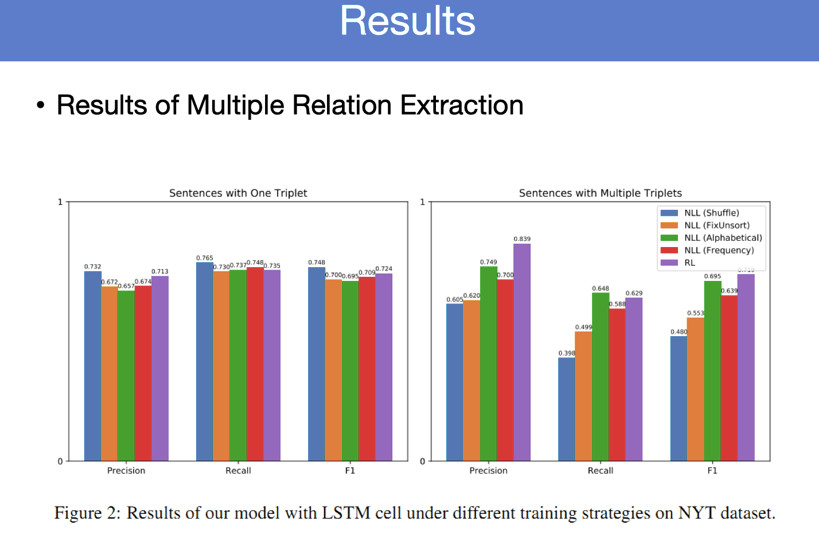
我们在不同类型的Overlap上做了不同的实验,只有一个三元组的时候比传统的下降,但是有多个三元组的时候,我们这个方法就有显著优势。不断生成三元组,有一个问题,这两个三元组,应该首先生成哪个三元组会带来更好的效果?这是这样的问题。我们有一些简单策略,比如说可以随机生成,也可以按照字母排序生成,也可以按照关系出现的频率,先把高频关系生成,再生成低频关系。

我们用了一个Reinforcement learning的方法让系统自动的选择三元组。Action有两种,一种是到某一节点Action生成的关系。到第二节点是生成的实体。
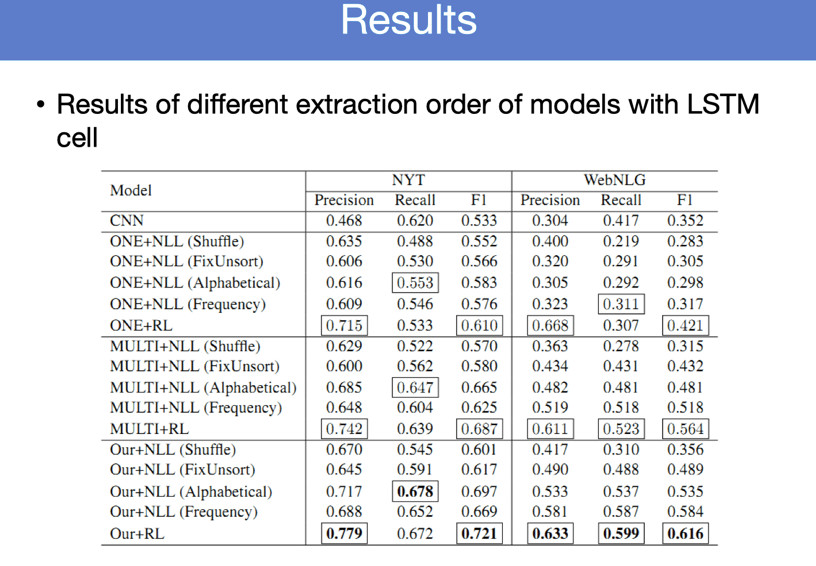
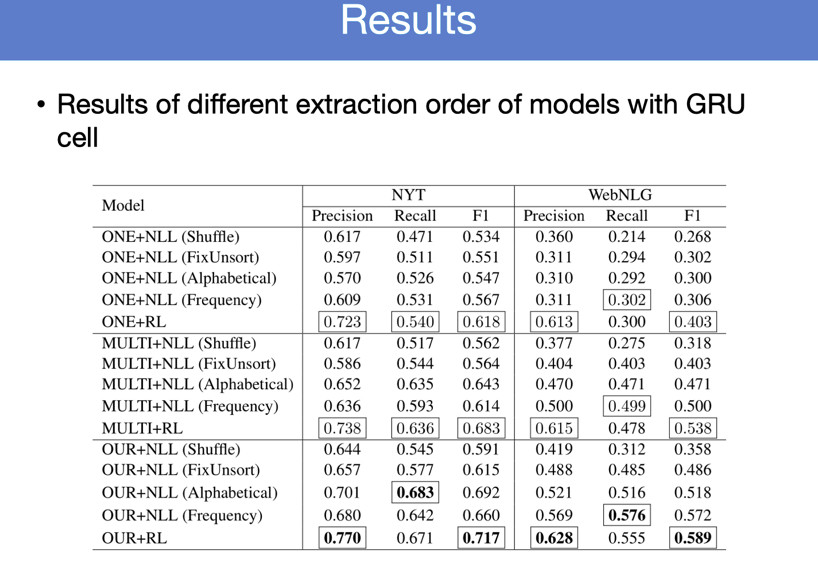
看一下最后的实验结果,第一个是CNN方法,确实能够自动优化,学到一些生成的顺序。包括一些按照频率生成的来说我们模型能够代表更大的优势。我第一个是在SPM上的模型上测的,直接换成GRU模型,得到了这样的结论。
一句话里面如果只含有一个三元组的话,我们这种方法是会有所下降,如果有多个三元组的话,这个方法会有非常大的提升。
今天主要是给大家介绍了我们自己做的三元组抽取方法,实验证明这种方法确实有效,而且能够进行学习的。
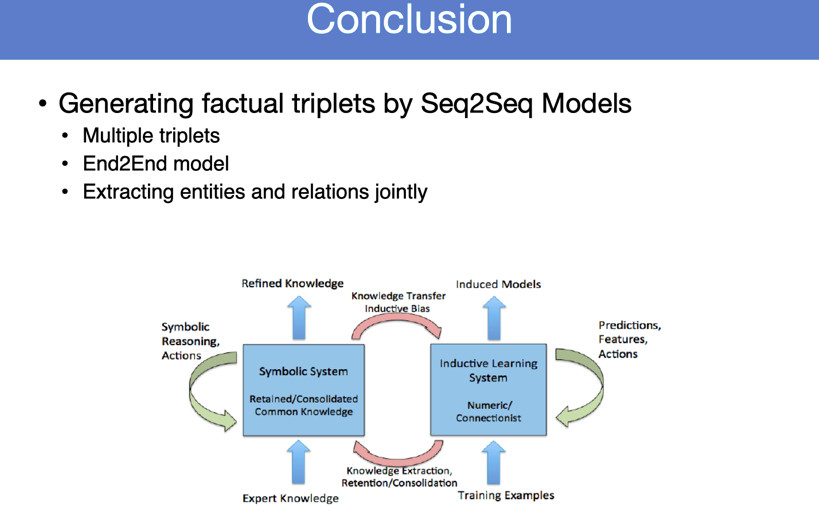
这张图片是我们自己的一些思考。现在更大挑战是如何把符号系统和神经网系统紧密结合在一起,能否在神经网络计算的基础上实现符号计算这可能是未来神经网络实现科学式的有效途径。




