
2.本文适合人群:本文通过通俗易懂的语言和例子介绍核心思想,不拽高大上的名词,适合于不懂机器学习的小白
3.看完本文后可以学习到什么?:你会觉得原来机器学习算法核心思想如此简单!
1.什么是机器学习
机器学习是什么?机器学习是从历史数据(历史经验)中获取模型(规律),并将其应用到新的类似场景中。
举个很简单的例子:
民政局婚姻登记处工作人员小王在民政局工作了20多年,历年来5.20号去登记结婚的情侣比平日增加好几倍,于是小王推测2019年5月20日来登记结婚的情侣数据也会大幅上升,便加派工作人员。
在这个例子中通过20多年来每天登记结婚的数量的统计,就是历史数据;5.20号登记结婚的人数大幅上升就是一个很明显的特征,历年来5.20号登记的人数都大幅增加就是一个模型,预测2019.5.20登记结婚的人数也会有一个大幅提升就是将模型应用到新的类似场景。当然在实际的应用中会增加其它维度,例如天气状况,是否是周末等影响因素。
2.机器学习的分类算法
分类算法就是通过一种方式或按照某个标准将对象进行区分。分类是一个有监督的学习过程,目标数据库中有哪些类别是已知的,分类过程需要做的就是把每一条记录归到对应的类别之中。由于必须事先知道各个类别的信息,并且所有待分类的数据条目都默认有对应的类别。
常用的分类算法:
单一的分类方法主要包括:决策树、贝叶斯、人工神经网络、K-近邻、支持向量机和基于关联规则的分类等;
组合单一分类方法的集成学习算法,如Bagging和Boosting等。
在本文中,作者只介绍常用的几种算法,通过通俗易懂的案例让朋友们理解高大上的人工智能机器学习算法。
3.分类算法之k-近邻
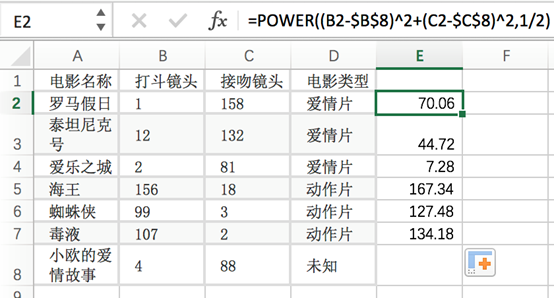
电影可以按照题材分类,每个题材又是如何定义的呢?那么假如两种类型的电影,动作片和爱情片。动作片有哪些公共的特征?那么爱情片又存在哪些明显的差别呢?我们发现动作片中打斗镜头的次数较多,而爱情片中接吻镜头相对更多。当然动作片中也有一些接吻镜头,爱情片中也会有一些打斗镜头。所以不能单纯通过是否存在打斗镜头或者接吻镜头来判断影片的类别。那么现在我们有6部影片已经明确了类别,也有打斗镜头和接吻镜头的次数,还有一部电影类型未知。
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
| 罗马假日 | 1 | 158 | 爱情片 |
| 泰坦尼克号 | 12 | 132 | 爱情片 |
| 爱乐之城 | 2 | 81 | 爱情片 |
| 海王 | 156 | 18 | 动作片 |
| 蜘蛛侠 | 99 | 3 | 动作片 |
| 毒液 | 107 | 2 | 动作片 |
| 小欧的爱情故事 | 4 | 88 | 未知 |
我们只需要计算欧氏距离(这个是真的叫欧式距离)
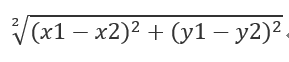
公式就是:
| 电影名称 | 计算公式 | 与未知电影的距离 |
| 罗马假日 |
|
70.06 |
| 泰坦尼克号 |
|
44.72 |
| 爱乐之城 | … | 7.28 |
| 海王 | … | 167.34 |
| 蜘蛛侠 | … | 127.48 |
| 毒液 | … | 134.18 |
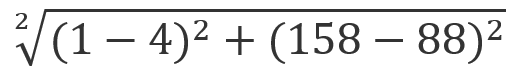
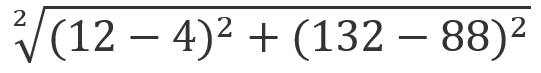
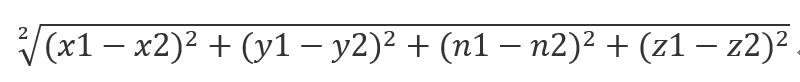
K值选择,距离度量,分类决策规则是K近邻法的三个基本要素
总结: k-近邻算法采用测量不同特征值之间的距离来进行分类 优点:精度高、对异常值不敏感、无数据输入假定 缺点:计算复杂度高、空间复杂度高 使用数据范围:数值型和标称型
4. 分类算法之决策树
决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。
通常决策树学习包括三个步骤:特征选择、决策树的生成和决策树的修剪。
特征选择就是特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率,如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的影响不大。通常特征选择的准则是信息增益,这是个数学概念。
下面用一个简单的案例分析,来帮助大家对决策树进行理解。
|
电影名称 |
电影类型 |
电影放映日期 |
电影价格 |
电影评分 |
|
罗马假日 |
爱情片 |
周一 |
99 |
99 |
|
泰坦尼克号 |
爱情片 |
周日 |
198 |
98 |
|
爱乐之城 |
爱情片 |
周六 |
89 |
78 |
|
海王 |
动作片 |
周六 |
88 |
78 |
|
蜘蛛侠 |
动作片 |
周四 |
98 |
88 |
|
毒液 |
动作片 |
周日 |
89 |
98 |
|
小欧的爱情故事 |
未知 |
周六 |
19 |
100 |
假如我周末的时间想去看一部爱情片的电影,电影的票价不能超过一百块,并且评分比较高,那么我会在上述的电影中选择哪一部电影呢?
我们来看特征选择的过程:
![]()
通过决策树算法,最终得到的结果是《小欧的爱情故事》这部电影。
假如我们觉得最终得到的这部电影是我们想看的,那么我们的判定流程就是对的,也就是说这个决策树的生成。
假如我们觉得电影价格无所谓不能作为特征,我们把电影价格这个特征去除,这就是决策树的剪枝。
决策树的一些优点:
- 简单的理解和解释。树木可视化;
- 需要很少的数据准备。其他技术通常需要数据归一化,需要创建虚拟变量,并删除空值。但请注意,此模块不支持缺少值;
- 使用树的成本(即,预测数据)在用于训练树的数据点的数量上是对数的。
决策树的缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树。这被称为过拟合。修剪(目前不支持)的机制,设置叶节点所需的最小采样数或设置树的最大深度是避免此问题的必要条件。
- 决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成。通过使用合奏中的决策树来减轻这个问题。
5.分类算法之随机森林
随机森林是一种重要的基于Bagging的集成学习方法,可以用来做分类、回归等问题。
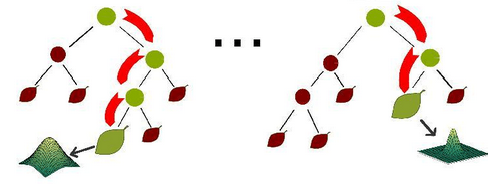
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。利用相同的训练数搭建多个独立的分类模型,然后通过投票的方式,以少数服从多数的原则作出最终的分类决策。
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个数的结果是False, 那么最终结果会是True.意思就是在上述的决策树算法流程中,每一个结点都随机选择特征,随机特征变量选取是这样的,由于随机森林在进行节点分裂时,不是所有的属性都参与属性指标的计算,而是随机地选择某几个属性参与比较。
随机特征变量是为了使每棵决策树之间的相关性减少,同时提升每棵决策树的分类精度。这样我们可能得到多个决策树的结果,可能我们得到八个结果其中6个结果是《小欧的爱情故事》,两个是《爱乐之城》,这样我们取决策的多的一项,得到算法结果就是《小欧的爱情故事》。
在前面的决策当中我们提到,一个标准的决策树会根据每维特征对预测结果的影响程度进行排序,进而决定不同的特征从上至下构建分裂节点的顺序,如此以来,所有在随机森林中的决策树都会受这一策略影响而构建的完全一致,从而丧失的多样性。所以在随机森林分类器的构建过程中,每一棵决策树都会放弃这一固定的排序算法,转而随机选取特征。
随机森林有许多优点:
- 具有很高的准确率
- 随机性的引入,使得随机森林不容易过拟合和很好的抗噪声能力
- 能处理很高维度的数据,并且不用做特征选择
- 既能处理离散型数据,也能处理连续型数据,数据集无需规范化
- 训练速度快,可以得到变量重要性排序
随机森林的缺点:
- 当随机森林中的决策树个数很多时,训练时需要的空间和时间会较大,训练和预测时都比较慢
- 随机森林模型还有许多不好解释的地方,有点算个黑盒模
总结:通过以上案例对三种算法的分析,相信大家都已经理解算法的核心思想,机器学习中的分类算法不同的算法都各有自己的优缺点,每种算法都有自己适用的场景。
BOUT
关于作者
欧阳仁浚:达观数据后端开发工程师,负责达观数据产品后端开发、产品落地、客户定制化产品需求等设计。对后端开发,文本处理算法落地方面有比较深入的了解。




