
在上篇文章中,笔者主要围绕社会化聆听的概念、价值和开展方法,下面,笔者将以一个汽车行业案例,来详细讲述上面关于社会化聆听步骤。
02 从凯迪拉克在汽车之家的口碑数据中挖掘出有价值的信息
在这一部分,笔者想通过一个完整的社会化聆听案例达到两个目的:
1.通过“一条龙”式的全流程分析(为了保证读者能够清晰的了解社会化聆听的方法和技巧,笔者采用的是编程的手段,而不是直接使用工具),使读者能了解社会化聆听的大致实施过程。
2.通过案例的讲解,使读者能够掌握一些实用的社会化聆听分析方法。
2.1 数据获取
本文的数据获取来源为汽车之家。那为什么选择汽车之家作为分析对象呢?
汽车之家成立于2005年6月,成立至今已有14年的历史,它为汽车消费者提供选车、买车、用车、换车等所有环节的全面、准确、快捷的一站式服务,是基于汽车专业内容的垂直社区,是全球访问量最大的汽车网站。因此,它上面能集中大量优质的用户UGC,可以“倾听”到用户关于汽车及其品牌的“声音”。
在这里,笔者获取的是汽车之家上“口碑频道”的数据,是关于购车消费者买车后的评论。该频道提供的数据维度丰富,包括汽车各方面的评分及其文字评论、晒图,以及各帖子的互动数据等。
下图是一条口碑评论的截图,可以看到一条口碑评论由许多结构化和半结构化的数据维度组成:
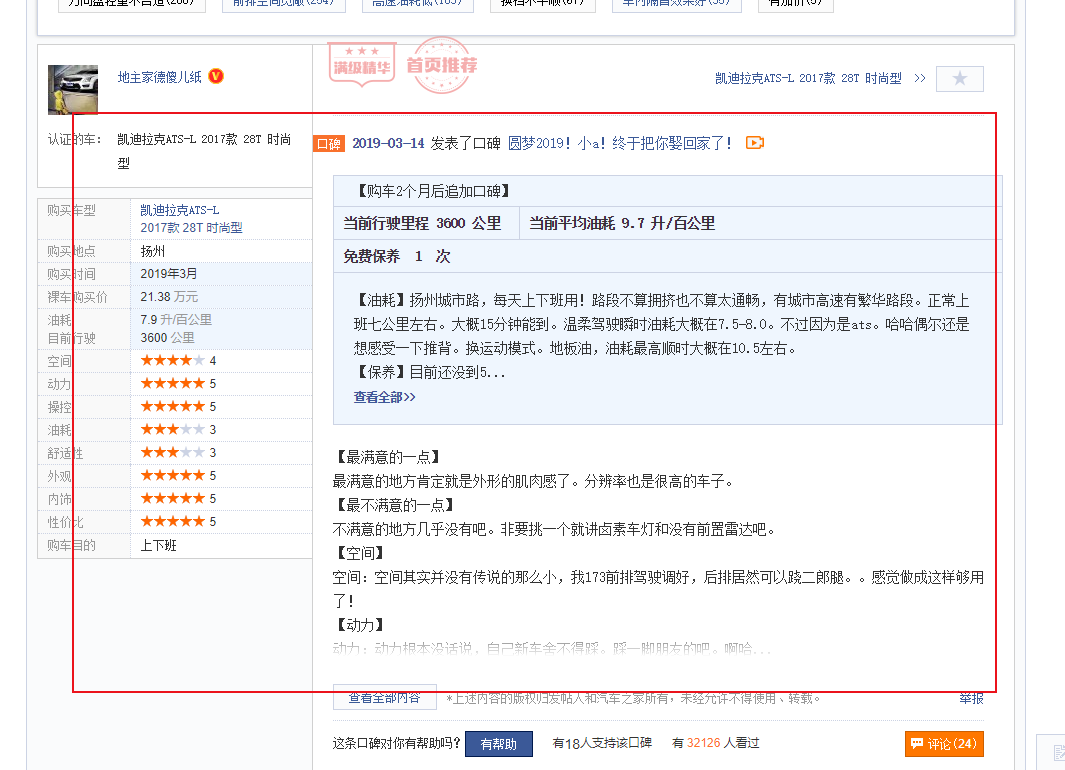
图8 汽车之家口碑社区蕴含有大量用户关于产品的观点、意见和情绪
笔者在这里进行数据采集的根据是Python中的Scrapy,它是Python下的一个快速、高层次的web抓取框架,用于抓取web站点并从页面中提取结构化的数据。获取的数据对用户和帖子详情信息做了处理,不涉及用户隐私,且本分析不作商业用途,仅供学习探讨。
获取的口碑评论量为30w+,其中凯迪拉克下的评论有12,900条,存储在SQL SERVERerver 2017Mongodb中。
2.2 分析目的
以下是笔者接下来分析挖掘的重点内容,主要集中在凯迪拉克的产品反馈和品牌调性方面:
- 了解消费者的购车目的,从用途/使用场景角度进行分析
- 了解消费者的购车原因,从汽车的几个重要维度,如安全性,操控,动力,油耗等
- 了解消费者比较重要的购车因素,即用户比较关注哪些汽车功能或汽车器件
- 分析消费者眼中的品牌调性,与事先设定的品牌调性有何差异
- 在上述分析中加入竞品分析,分析其异同点
2.3 数据特征及分类
现在,根据分析目的对获取到的数据的字段进行分类和挑拣,选择部分可作为分析的数据:(1) 评级类数据:
- comfortableness_score(舒适性评分)
- internal_score(内饰得分)
- maneuverability_score(操控性得分)
- oil_score(油耗评分)
- power_score(动力评分)
- apperance_score(外观评分)
- costefficient_score(性价比评分)
- space_score(空间评分)
- Satisfaction (满意度)
(2)半结构化数据:
- purpose (购车目的/用途)
- bought_Address(购买地址)
- brand_name (品牌名称)
- buy_date(购买日期)
- buy_price(购买价格)
- carowner_levels(车主等级)
- prov_name(省份名称)
- city_name(城市名称)
- Comment_count(评论数)
- Helpful_count(有用数)
- Visit_count (浏览量)
- product_name(产品名称)
- pub_date(发布日期)
(3)文本类数据:
- apperance_feeling(外观感受)
- comfortableness_feeling (舒适性感受)
- costefficient_feeling (性价比感受)
- maneuverability_feeling (操控性感受)
- internal_feeling (内饰感受)
- power_feeling (动力感受)
- oil_feeling (油耗感受)
- space_feeling(空间感受)
- car_defect(车辆缺陷)
- car_merit(车辆优点)
- review_summary (评论总结)
- bought_reason (购买原因)
本文分析所用到的数据主要是文本类数据和小部分的半结构化数据。
2.4 消费者购车目的分析
在“消费者目的”分析中,笔者选取了宝马、捷豹、奔驰、凯迪拉克和路虎这5个汽车品牌作为分析对象,想要知晓消费者在这5个汽车品牌的使用场景上有什么不同,这也是汽车厂商较为关注的方面 — 自己的产品定位与消费者心智中的定位是否一致,宣传策略是否需要强化或者调整。
在口碑频道的评论中,存在“购车目的”这一字段,是一个半结构化的选项,评论者可以选填自己喜欢购买小车的应用场景。
官方提供了10个候选项:
- 购物
- 接送小孩
- 拉货
- 跑长途
- 泡妞
- 赛车
- 商务接送
- 上下班
- 越野
- 自驾游
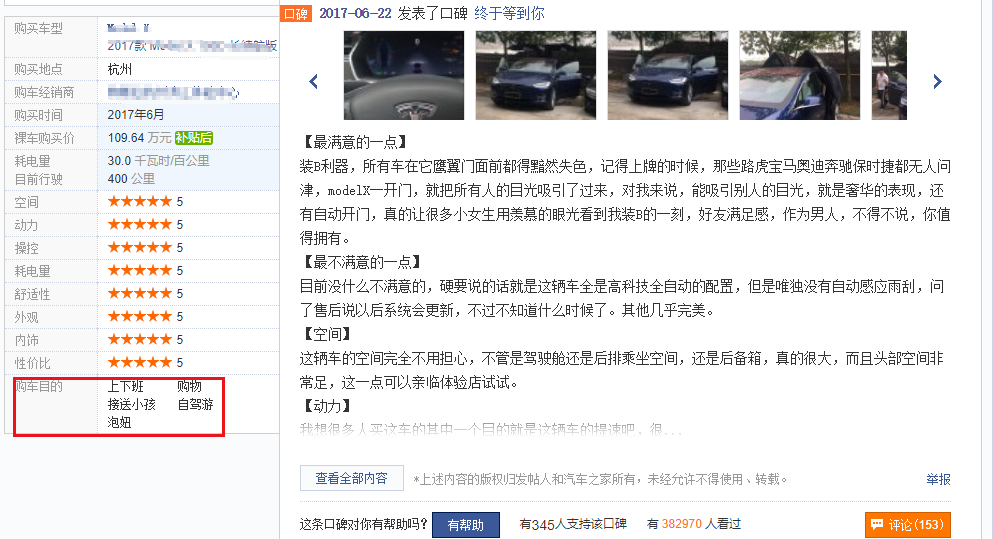
图9 购车目的是半结构化的数据
从上图中可以看到,消费者可以同时填写多个购车目的标签。所以,在正式分析之前,需要对该标签数据进行拆分,出现多个标签的行要拆解成多行,对结果进行透视表统计,最后整理成交叉列联表。结果如下表所示:
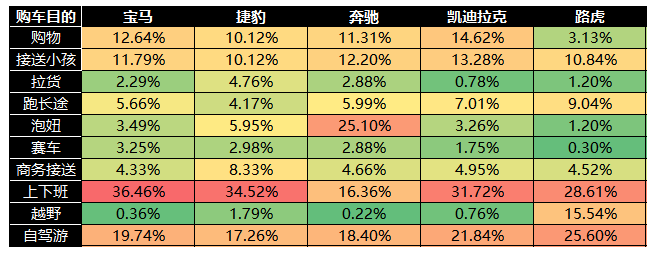
图10 5个汽车竞品的购车目的交叉列联统计表
从上面的表格中,我们可以看到,宝马、捷豹、凯迪拉克和路虎这4个汽车品牌的主要购车目的是“上下班”,用于上下班通勤,而奔驰的主要购车目的集中在“泡妞”上,购车目的不单纯……
然而,上面的表格并没有完全挖掘出多元关联数据中的价值,此时该对应分析(Correspondence Analysis)出马了!
对应分析(Correspondence Analysis)也称关联分析、R-Q型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,通过分析由定性变量构成的交互汇总表(也就是上表)来揭示变量间的联系,它可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系,是一种强有力的数据可视化技术 。
对应分析主要应用在市场细分、产品定位、地质研究以及计算机工程等领域中。原因在于,它是一种视觉化的数据分析方法,它能够将几组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来。
对应分析的基本思想是将一个列联表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。它最大特点是能把众多的样例(这里是汽车品牌)和众多的变量(这里是购车目的)同时作到同一张图解上,将样例的大类及其属性在图上直观而又简洁地表示出来,具有直观性。另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样例进行直观的分类,而且能够指示分类的主要参数(主因子)以及分类的依据,是一种直观、简单、方便的多元统计方法。
得到对应分析二维坐标图以后,要想作出正确的解读,还需要使用点“小手段”:
从坐标轴中心向任意汽车品牌连线(具有方向,是一条射线),指向汽车品牌的方向为正向,然后将所有的使用场景往这条连线及其正反延长线作垂线,(使用场景的)垂点越靠近该连线及其延长线的正向方向,就代表该使用场景对于该汽车品牌而言更常见。
下图是将上表数据映射到二维坐标系的可视化呈现:
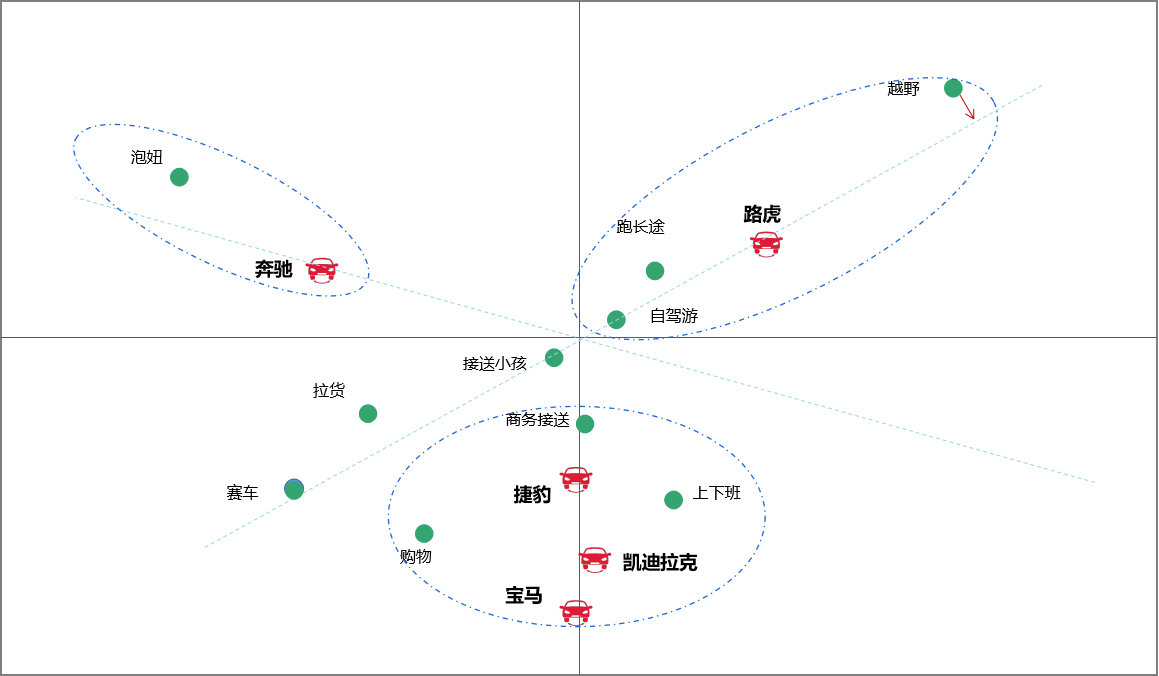 图11 由交叉列联表转化成的竞品对应分析图
图11 由交叉列联表转化成的竞品对应分析图
转换后的可视化结果更能发现一些有趣的事实:
- 捷豹、凯迪拉克和宝马从使用场景(购车目的为购物、上下班、商务接送、接送小孩等)上来说,几乎是重叠的,彼此是竞争对手;
- 奔驰最突出的使用场景还是泡妞(射线正向上离得最近),其他使用场景并不突出(在射线负向上);
- 路虎的越野特性还是最突出的,跑长途和自驾游的特性也较突出。
由分析的结果可知,凯迪拉克的使用场景比较泛,当然原因也有可能在于笔者分析的是品牌而不是具体的车系和车型,分析的粒度较粗,笔者将会在文末聊到这一点。
2.5 了解消费者关注的典型话题
这里,笔者将凯迪拉克口碑数据的两个字段 — Car_defect(车辆缺陷)、Car_merit(车辆优点)整合到一起,对评论内容进行一个“鸟瞰式”的分析,迅速识别出汽车消费者较为关注的话题。
此处的分析基于HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)实现。相较于K-means、Spectral clustering、Agglomerative clustering、DBSCAN等传统聚类算法,笔者特别欣赏它的3大特性:
- 不需要设定聚类数,有算法自动算出来簇群数
- 可以较好的处理数据中的噪音
- 可以找到基于不同密度的簇(与DBSCAN不同),并且对参数的选择更加鲁棒(Robust,模型更加健壮)
基于自动聚类形成的关键词词云,能自然的反映评论数据中的潜在结构和语义特征,由此能准确且清晰的知晓消费者对于汽车及其功能、器件的关注侧重点。
对于生成的可视化结果,可以这样解读:
- 字体大小表示词汇的权重值大小,注意,这里的权重非词频数,而是TF-IDF值,更能表示该词汇在评论中的重要性
- 颜色代表不同的话题
- 词汇之间距离越近,说明它们在同一语境中出现的频率较高,越具有语义相关性,比如“胎噪”、“轮胎”、“啃胎”、“噪音”、“隔音”等词汇挨得很近,我们能迅速联想到是胎噪导致噪音或者隔音效果差,而不是汽车发动机或者车厢内组件老化产生的摩擦声引起的。
下图是自动聚类出来的结果,自动聚为12个主题:
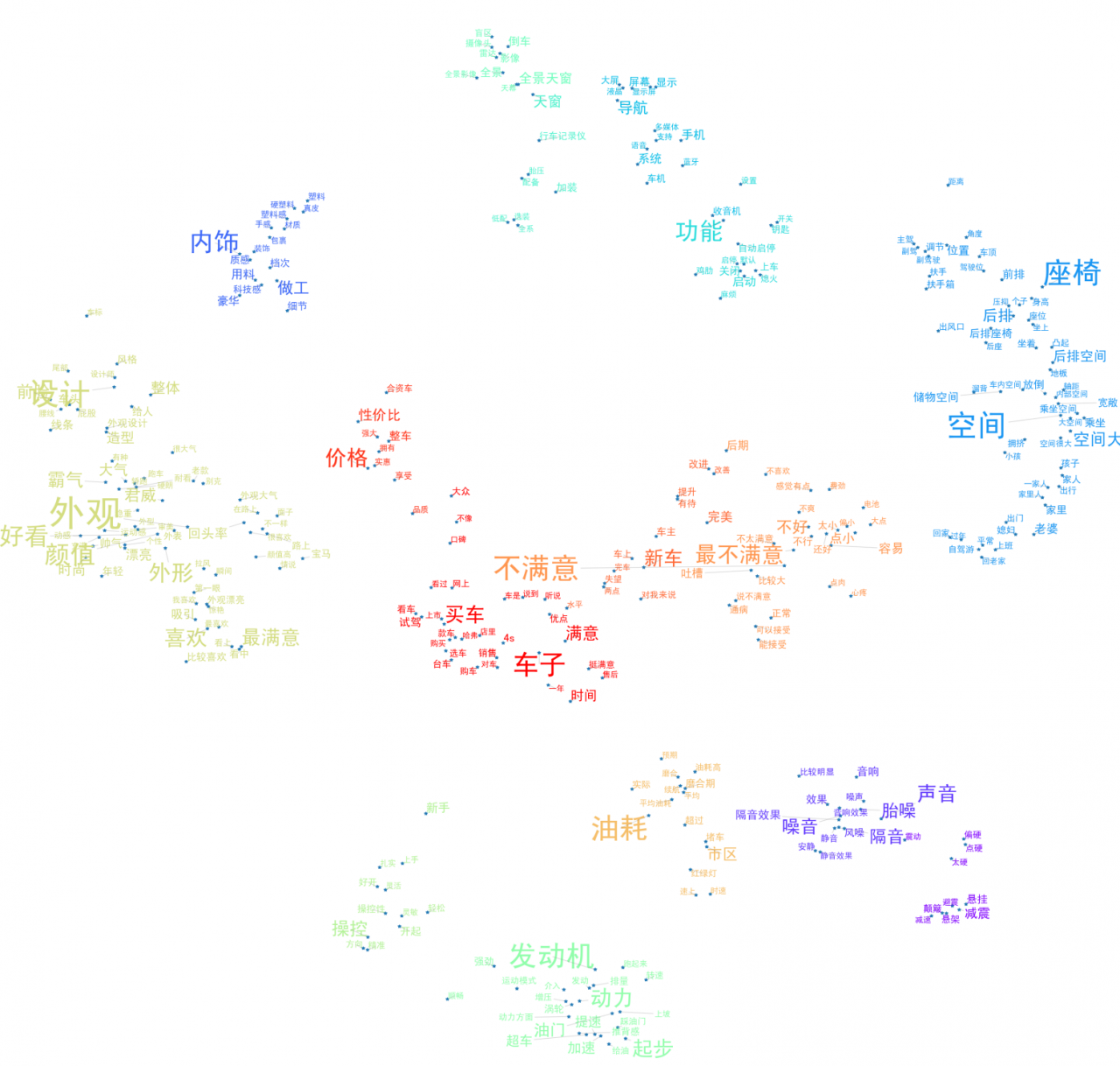
图12 自动聚合的用户话题关键词云
为了将各主题的界限划分得更清晰些,笔者给每个主题加了虚线框(点击图片放大看高清大图):
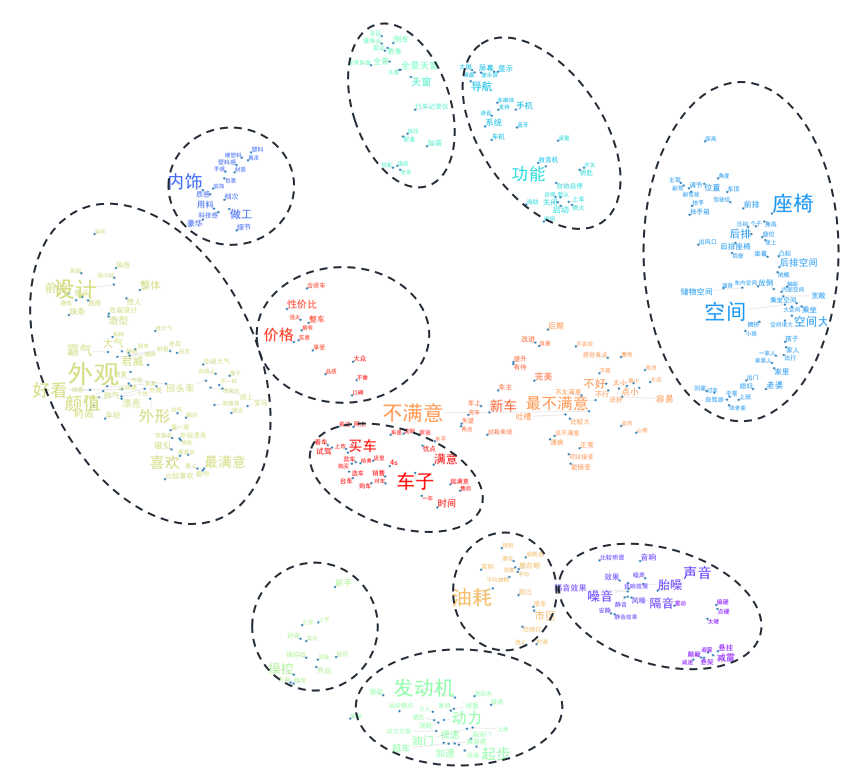
图13 经锚定的用户话题关键词云
上图中,较为突出的是11个主题,按其重要性程度(字体大小、主题词数)选出TOP5,根据其中的关键词可以推测消费者的热门讨论内容,依次是:
- 外观:汽车的整体设计,主要是外形,买车的消费者大都是“颜控”
- 空间:后排空间、储物空间和后排座椅是大家比较关注的方面,另外,一家人出行的时候,空间问题就容易突显
- 动力:发动机、汽车起步(油门、起步)、提速/加速问题是动力这一主题下消费者较为关心的方面
- 配置:汽车配置这块,消费者对导航系统和内部的显示屏较为关心
- 内饰:内饰这块,消费者反映较多的是材质的塑料感
由于笔者不是汽车行业的从业人员,平时也不开车,所以对该领域的关键词不太敏感。不过,如果是这方面的从业者,根据词汇之间的关联性(距离远近),会有可能从总体上发现一些业务相关问题。
2.6 从“车辆缺陷”中识别凯迪拉克的重要产品缺陷
刚才的关键词云是一个“鸟瞰式”的分析,可以在较短的时间内抓住海量评论的重点。但是,如果我们想要进一步了解消费者对于凯迪拉克的哪些缺点比较关注,也就是挖掘消费者关于凯迪拉克的产品缺陷的典型意见,这就涉及到分析Car_defect(车辆缺陷)这个字段了。
这里,笔者想找到凯迪拉克的12,900条负面评价中最具代表性的差评,思路如下:
- 抽取语句中的主观性信息(形容词、副词、习语,反映消费者的评价),和客体信息(名词,主要是汽车各器件、功能、使用场景等,排除掉人名、地名、时间等实体)。
- 对每条评论中代表主观性信息和客体信息的词汇的TF-IDF值进行累加,得到每个评论语句的重要性得分。
- 对这些评论进行聚类,最终形成了10个规模较大的簇群,数量较少的被当做噪音处理,尽管它们具有一定的长尾价值。
- 在每个簇群中,找出重要性得分最高的语句,且词汇数限定在100个以内,字数太多,观点不明确,重点不突出,对于后续浏览者的影响力也有限。

图14 评论中的每个词汇都有一定的权重
以下是按照上述思路挖掘出的TOP10典型意见,代表了购买凯迪拉克的用户对于凯迪拉克车辆缺陷中的10个方面较为不满:
- 30多万的车标配的卤素大灯,没有前后雷达让人有点无语
- 提速没有传说快!倒车后视镜显示太模糊!A柱有点挡视线!
- 储物空间明显不够用 比起我家之前的小6子(编者注:马自达6)少太多,特别是手机完全不知道怎么搞
- 基本没有,硬要找的话可能是有时会有点异响
- 6AT确实老了点,算是够用吧。
- 最不中意的就是排挡杆,巨丑
- 暂时没有,再就是新车油耗有点高。漆有点薄,准备去做镀晶。
- 这个也不算是不满意吧,因为后轮驱动的原因,中间的隆起实在是有点影响乘坐,后备箱也因为这样子不是很大平时东西多的时候都要放在后座。
- 底盘确实硬一点,舒适度差了一点~
- 感觉这个车的音响效果并不如想象中的好。
上面这些典型缺陷可以作为汽车厂商接下来产品改进的重要考量。
对于“30多万的车标配的卤素大灯,没有前后雷达让人有点无语”这个典型观点,利用基于LSI的相似语句检索,可以看到最相关的若干信息,看看在这个话题下,用户具体的槽点和痛点是哪些:

图15 具体槽点/痛点语句的检索
2.7 从“购车原因”中挖掘出重要的购车影响因素
在这部分分析中,笔者将所有文本类字段进行合并,做进一步文本挖掘,看看具体是哪些因素诱发消费者购买凯迪拉克的。笔者的做法是,从每条语句中抽取TF-IDF最高的TOP15关键词,主要是汽车实体词(描述汽车零部件、特性、配置相关的词汇)、功能或者评价词。

图16 提取评论语句中包含重要语义信息的词汇
然后按词汇顺承关系(时间先后顺序,箭头指向方为向后提及)做词汇共现分析,去词频数较高的若干词汇,最后形成下图:
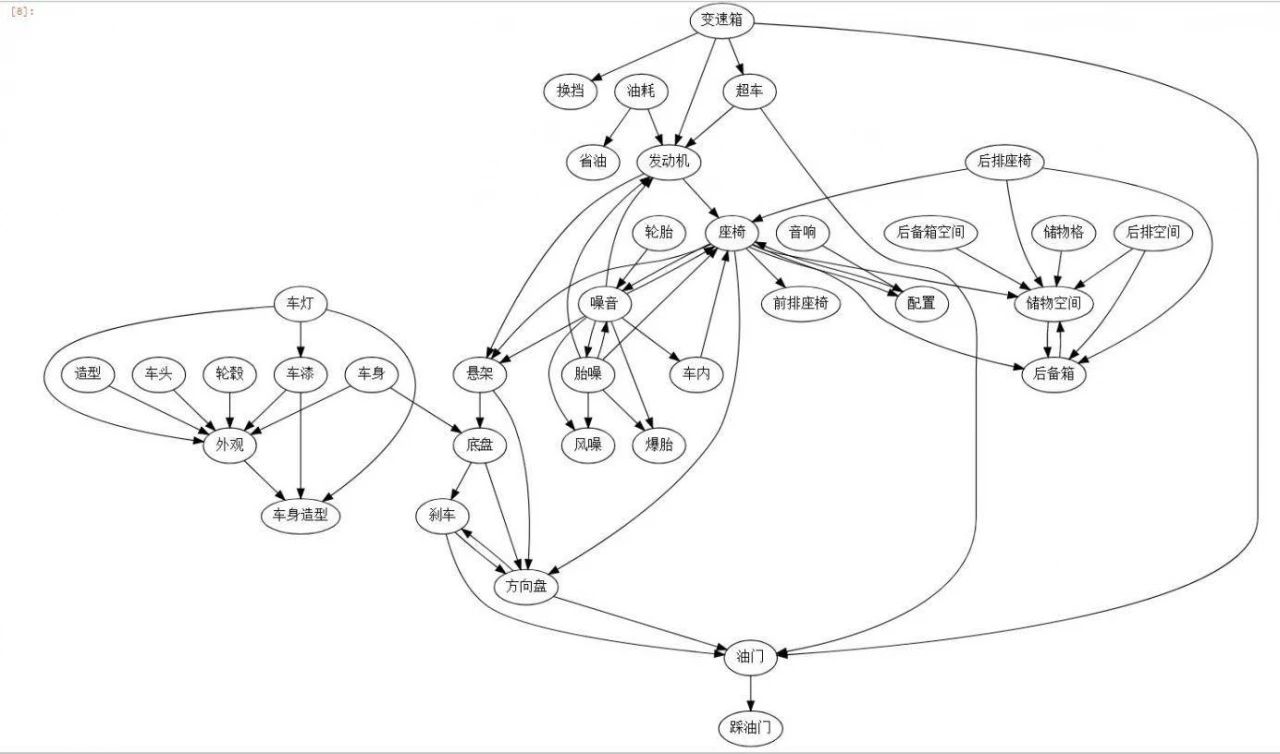
图17 购车影响因素图谱
从上图可以看到,外观、座椅、储物空间、发动机、方向盘、后备箱是凯迪拉克购车者较为关注的方面,至于是好的评价还是差的评价,现在还未可知。这些关键词节点的“Betweenness Centrality (中介性核心性)”较高,该词学术的解释是“两个非邻接的成员间的相互作用依赖于网络中的其他成员,特别是位于两成员之间路径上的那些成员,它们对这两个非邻接成员的相互作用具有某种控制和制约作用“,在评论中经常与其它汽车器件共同出现,说明这些器件是购车者较为关注的方面。如果想看到消费者关于这些器件的具体看法,可以采用上述LSI检索相关的语句,笔者在这里就不做赘述。
2.8 基于微博数据的消费者兴趣挖掘
了解消费者的兴趣爱好对于打造品牌调性、营销内容创作及投放渠道选择都有帮助,是产品市场调研和竞品分析中的重要事项。
这里,笔者先挖掘出汽车品牌对于人群的兴趣图谱,然后结合使用与满足理论(Uses and Gratifications)对结果进行解读,为内容创作和媒体投放方面提供思考方向。
对于消费者的兴趣爱好的挖掘,笔者会用到新浪微博的消费者个性标签数据。该部分数据基于关键词命中,也就是说,采集到的标签数据仅针对提及目标汽车品牌的微博用户。
在这里,笔者采用的标签数据涉及到5个品牌,即凯迪拉克、宝马、奔驰、路虎和捷豹,时间跨度为近一个月。数据预处理方式跟前面的一致,最终得到如下对应图谱:
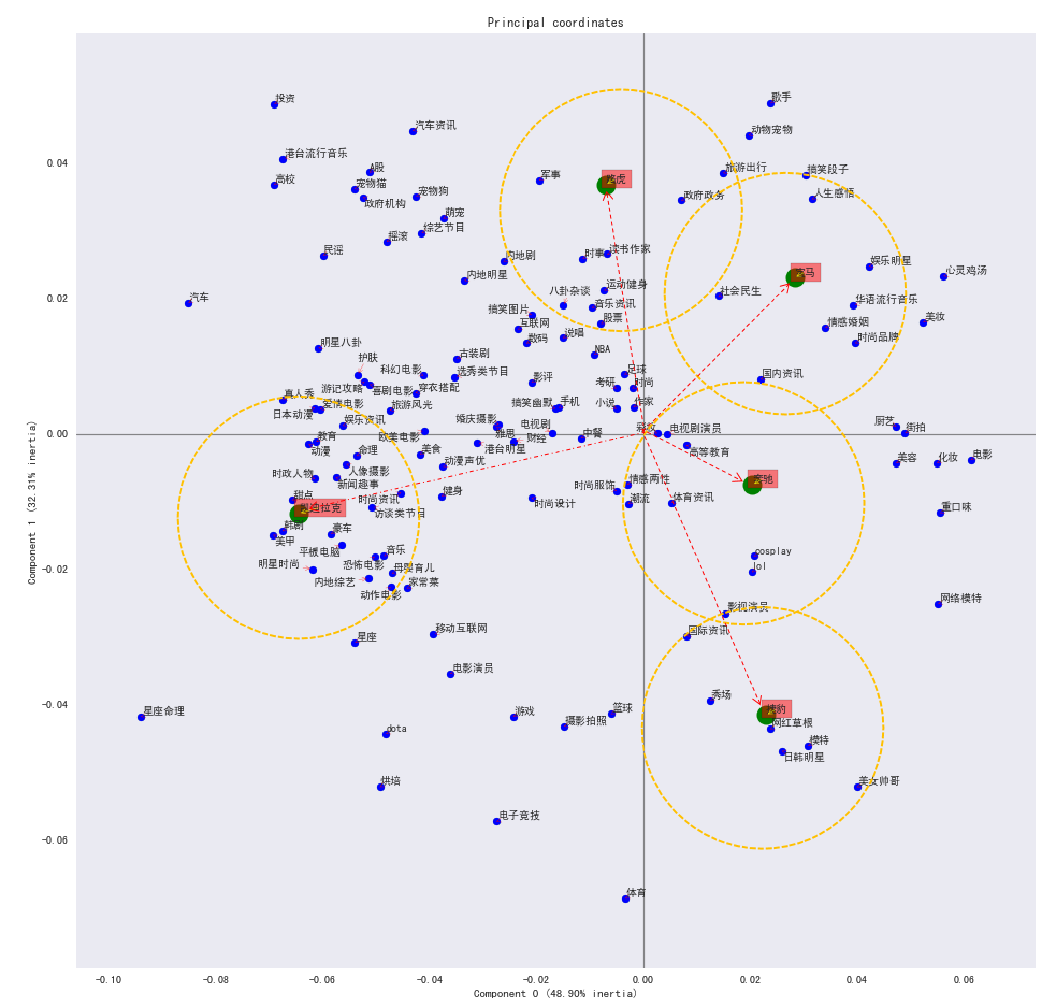
图18 5个汽车品牌的用户兴趣对应分析图谱
(数据来源:新浪微博,时间:2018-12-01 ~ 2019-05-01)
比照之前对应分析图谱的分析方法,我们可以得到与各个汽车品牌典型且最为接近的微博消费者兴趣标签:
- 凯迪拉克:星座命理、汽车、美甲、韩剧、内地综艺等
- 宝马:心灵鸡汤、歌手、娱乐明星、搞笑段子、人生感悟等
- 奔驰:美女帅哥、网络模特、模特、重口味、网红草根等
- 路虎:投资、汽车资讯、歌手、旅游出行、A股、军事等
- 捷豹:体育、美女帅哥、电子竞技、日韩明星、模特等
可以看到,这几个汽车品牌的关注人群的兴趣大体上都呈现娱乐化的特点,影视、明星方面的兴趣较多,这也与微博娱乐化的平台特性有关。
挖掘出汽车品牌所对应人群的兴趣爱好以后,可采用使用与满足理论(Uses and Gratifications)对结果进行深度解读和应用。
使用与满足理论是一种以受众为中心的理论,侧重于对大众传播的理解。虽然其理论框架来自传统媒体,并远远早于互联网和社会化媒体,但其理论假设使其完全适用于互联网和社会化媒体研究。该理论假设可以概括为:
- 在选择媒体和内容时,受众是积极的参与者,会根据个人目标选择媒体和阅读倾向;
- 媒体渠道彼此之间竞争,还与其他资源竞争,以获得受众的关注;
- 人们在选择媒体和内容时,是主动、自我清醒且受动机驱动的,这使得他们能够清楚的表达选择媒体的原因。
基于这些假设,该理论认为受众会积极的寻求满足,而满足的类型将推动他们对社会化媒体及内容的选择,因而媒体选择是目标导向和实用驱动的,也就是受众的需求要被所选择的社会化媒体满足。
满足类型背后往往潜藏着更为个性化的内在需求,E·卡茨、M·格里维奇和H·赫斯将其归纳为5个大类:
1)认知需求——获得信息、知识和理解,如上知乎提问或者浏览感兴趣的话题、母婴论坛找育儿知识等;
2)情感需求——情绪的、愉悦的或美感体验,如快手、抖音上看美女直播;
3)个人整合需求——加强信心,稳固身份地位,如通过加入线上圈子,观察同类的言行,并通 过这种方式获得身份认同;
4)社会整合需求——如利用即时通讯软件与熟人、生人进行交流,发展或维护人际关系;
5)舒解压力需求——逃避或转移注意力,主要是娱乐活动,包括各种真人秀节目、网络游戏等。利用使用与满足理论对上述各汽车品牌的兴趣标签结果进行分析,大体上可以得出如下结果:
- 凯迪拉克:舒解压力需求
- 宝马:舒解压力需求、情感需求
- 奔驰:情感需求
- 路虎:个人整合需求
- 捷豹:舒解压力需求、情感需求
上述结果反映了各汽车品牌用户在媒体选择时的内在需求,在内容制作和媒体选择时可以作为参考。比如,凯迪拉克可以选择舒解压力需求的内容频道或者社会化媒体(比如即刻、一条等),内容制作上可采用游记类主题,音乐可以采用舒缓的轻音乐,图片风格则是小清新…
此外,从竞品分析的角度,对应分析图还可以作如下解读:
1. 向量的夹角大小:从向量夹角的角度看不同品牌之间的相似情况。上图中任意两个汽车品牌向量之间的夹角越小,代表这两个汽车品牌的消费者兴趣爱好相近,实际上反推出品牌调性的趋同。这里可以看到,奔驰和捷豹的在微博上的关注人群的兴趣爱好趋同,由此反推出品牌调性较为接近。凯迪拉克和其他4个汽车品牌之间的品牌调性差异较大,个性较鲜明。
2. 距离坐标轴的远近:从统计学上来看,品牌越靠近坐标轴中心,越没有特征;越远离坐标轴中心,说明特征越明显。从品牌角度来考虑,说明越远离中心的汽车品牌,消费者越是容易识别,说明品牌特征(特点、特色)很明显;越靠近中心的品牌,消费者越是不容易识别,要说明品牌定位有问题,没有显著的特征可以识别,差异化还不够。从这一点来看,凯迪拉克和捷豹的品牌个性较为鲜明,奔驰的品牌定位最为模糊。了解了品牌在潜在消费者心中的品牌形象以后,如果发现跟预期接近,继续加强这方面的投入即可,如果发现偏离预期,就需要及时调整思路了,在社会化媒体平台上发布能反映品牌调性的内容,引发关注人群的互动,长此以往,可以对塑造特定的品牌印象起到一定帮助。
2.9 基于评论内容的品牌调性挖掘
现今这个消费时代,消费者的消费模式逐步从实用主义消费过渡到象征性消费,从仅注重产品的功能和质量,转变为更注重品牌与自身品位、气质的契合度,从这个方面来讲,品牌越来越成为消费者的自我延伸。
与此同时,与早期产品和品牌宣传事实信息、功能化描述及产品诉求不同,强调品牌调性的情感式营销聚焦于产品、服务和品牌的“人格化”因素,展现品牌的“人性化特征”逐渐成为社会化媒体语境下强化传播和建立关系的主要手段,更为人性化的积极互动在社交媒体体验中的重要性越来越突出。
如果品牌与追随它的消费者保持持续的“人性化交流”,那么,相对于硬性推销方式,这种注重消费者关系维护的营销方式更能打动消费者,同时也能够鼓励消费者积极参与并长期追随。
为营造消费者与品牌之间积极互动的条件,品牌必须不断采用“拟人化”的方式来进行营销传播,使品牌具有人的性格和气质,这就涉及到“品牌调性”的话题了。
比较常规的做法是,品牌会用“拟人化”的方式在社会化媒体上去宣扬产品和服务的独特品质,这种方式可能是活泼的,也可能是清新的,抑或是高贵的…总之,品牌会着力打造一个属于自己的品牌个性和风格,从而与消费者在情感上产生联结,催生出大量拥簇。
然而,品牌所创造的品牌调性是通过各类媒介及内容呈现的,其中的重要信息随着表现的形式或者传播层级的递增而消减,最终反馈到消费者脑海中的可能是另一番景象,可能会产生一定的品牌个性认知偏差。因此,品牌运营者需要经常性的进行消费者品牌调性印象调研,及时了解消费者对于品牌个性的认知情况,视理解偏差的程度进行调整或优化。
在本文中,为了测量消费者对于凯迪拉克的品牌调性的实际认知情况,笔者采用千家品牌实验室改良过的品牌个性模型。千家品牌实验室向忠宏近六年来对20个行业领域1000多个品牌的持续监测与品牌个性的分析,提取出一些中国本土化的品牌个性词汇,这些新增的品牌个性语汇对应的品牌人格通过合并到三个品牌层面,最终也并入了Aaker提出的品牌个性的五个维度中。
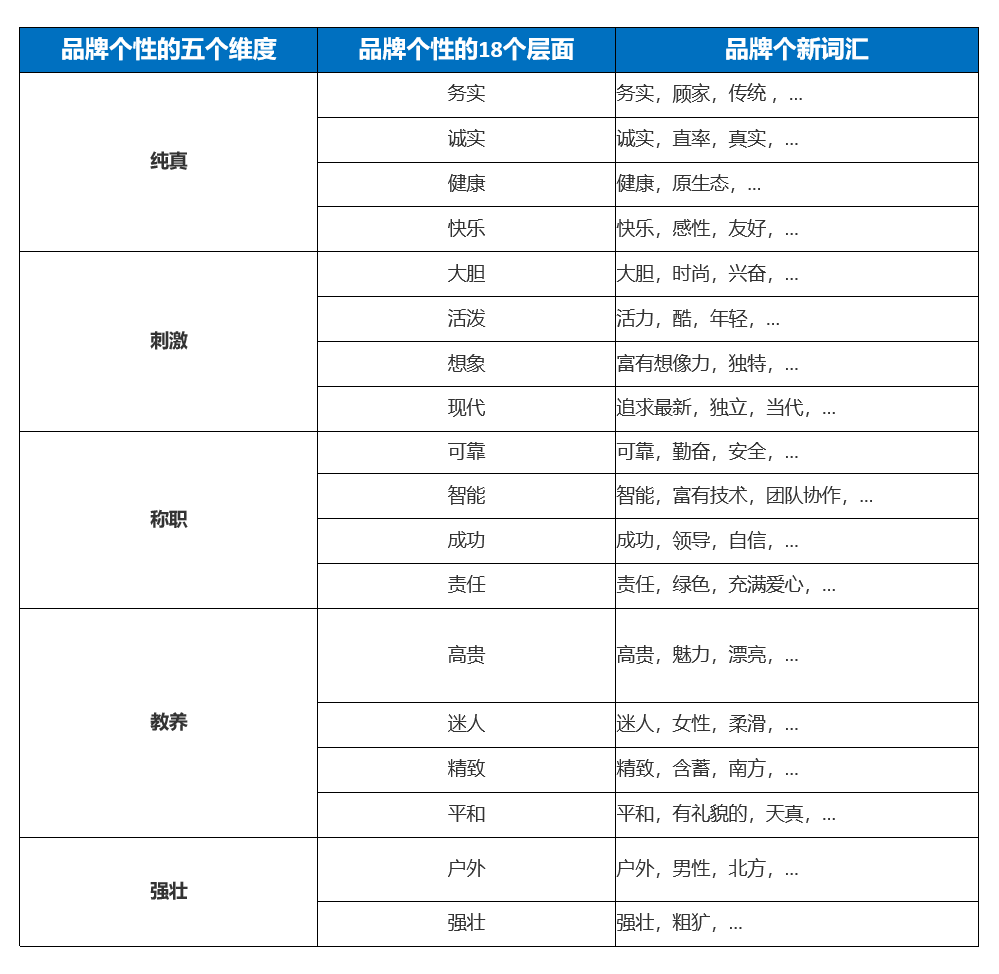
图19 中国本土化品牌个性词汇对照表
(数据来源:千家品牌实验室向忠)
下面是笔者进行品牌个性挖掘的实际步骤:
1)将凯迪拉克口碑数据中的所有文本类数据进行合并,包括外观感受、 舒适性感受、性价比感受、操控性感受、内饰感受、动力感受、油耗感受、空间感受、车辆缺陷、车辆优点、评论总结、购买原因等;
2)经过自然语义分析,即“实体/属性—情感词”抽取分析,得到7035个“物件词+情感词”组合:
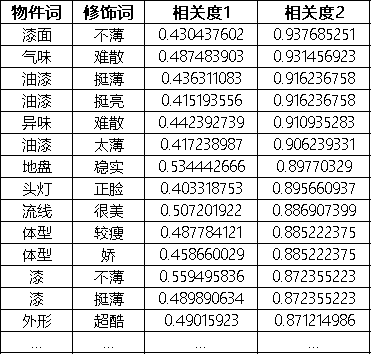
图20 “物件词+情感词”样例
3)去除掉功能性的形容词,保留跟品牌调性相关的情感词。剔除掉描述汽车器件及功能的形容词,如“漆面+不薄”、“起步+很肉”、“气味+难散”、“真皮+柔软”等,其中的观点词/形容词对于描述品牌个性意义不大,而要保留拟人化的观点词,如“腰线”+“刚劲”中的刚劲,“体型+娇”中的“娇”;
4)根据品牌个性维度语汇库,对保留下来的品牌调性形容词进行归类统计。结果如下所示:
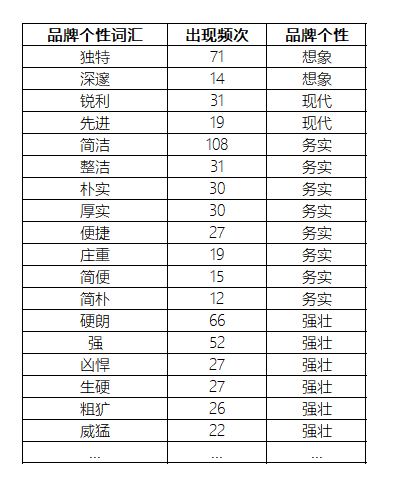
图21 品牌个性综合统计结果
5)对统计结果进行旭日图可视化呈现,反映2个层级的品牌调性占比关系。结果如下图所示:
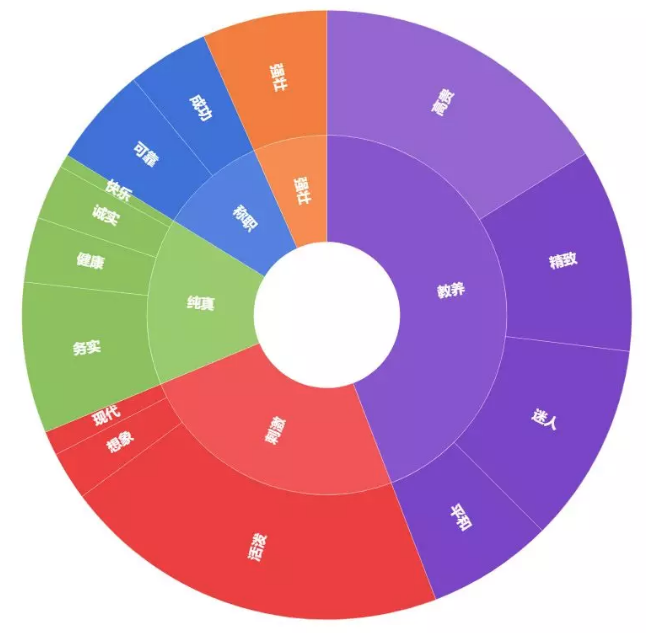
图22 凯迪拉克的品牌个性图谱
从最终结果可以看到,凯迪拉克的品牌调性偏于教养,主要在于高贵、精致、迷人的气质;其次是其“刺激”的一面,主要在于其活泼的个性。
我们不妨从百度百科上的凯迪拉克品牌史概略来看待这个结果:
“一百多年来,凯迪拉克汽车在行业车内创造了无数个第一,缔造了无数个豪华车的行业标准;可以说凯迪拉克的历史代表了美国豪华车的历史。在韦伯斯特大词典中,凯迪拉克被定义为“同类中最为出色、最具声望事物”的同义词;被一向以追求极致尊贵著称的伦敦皇家汽车俱乐部冠以“世界标准”的美誉。凯迪拉克融汇了百年历史精华和一代代设计师的智慧才智,成为汽车工业的领导性品牌。
一款美国汽车可以很狂野,也可以很豪华,但是如果想要很尊贵就比较难了。不过卡迪拉克就是一个例外,他的创始人为了纪念底特律的奠基者、法国贵族安东尼凯迪拉克,就将其家族的徽章作为了车标。现在的卡迪拉克车标已经有了很大的变化,比如少了象征着三圣灵的黑色小鸟和镶嵌着珍珠的王冠,只是由桂冠环绕着经典的盾牌形状,而盾牌形状则由各种颜色的小色块组成,其中红色代表勇气,银色代表纯洁的爱,蓝色代表探索。”
如此看来,挖掘的结果较能反映事实情况,与品牌发展历程相符。
结合使用与满足理论和品牌调性分析,可以对于内容的规划、制作,以及渠道的投放提供参考,辅助决策。比如,分析汽车品牌跟网红的调性以及粉丝群体是否契合,找到合适的品牌代言人。
03社会化聆听产品化的成功实践 ——以达观数据的客户意见洞察平台为例
上面的案例分析固然精彩,但是要充分发挥社会化聆听在企业中的业务价值,我们必须将其视为一个长期工作,使之“嵌入”到企业的业务流程之中来,为此,我们还得有一套产品化的解决方案。
在这里,笔者结合自身的工作实践,聊聊达观数据的客户意见洞察平台在这方面的独到理解。
基于先进的自然语言处理和知识图谱技术,达观数据构建了新一代的智能客户意见洞察平台。通过对各行业/领域的社会化媒体进行实时数据抓取和深度处理,可以帮助政府/企业及时、全面、精准地从海量的数据中了解公众态度、掌控舆论动向、聆听用户声音、洞察行业变化,实现产品、用户、渠道、竞品、危机感知等多维度的全景分析。
除了一般性的舆情/social listening能力外,达观数据的客户意见洞察平台还注重如下3个方面:
3.1 注重数据分类的精准性
在采用先进深度学习模型的同时,达观客户意见洞察平台还有知识图谱的“加持”,能最大限度的提升文本预处理和语义分析阶段的文本分类精准度,使得后续的统计和挖掘的结果具有较高的可信度,从而能放心的将分析结果应用于指导实践。

图23 达观数据的客户意见洞察平台较为注重(文本)数据分类的准确性
3.2 注重文本数据的深度挖掘
无论是图片数据还是语音数据,后续还是会转成文本数据进行处理,因而文本数据的处理是非结构化数据的重中之重。达观数据专注于文本数据的处理和挖掘,在许多领域积累了大量成熟、领先的文本智能处理解决方案。除此之外,达观客户意见洞察平台在立足业务场景的前提下,还广泛借鉴营销学、心理学和咨询等领域的分析方法和手段,充分挖掘数据的业务价值。
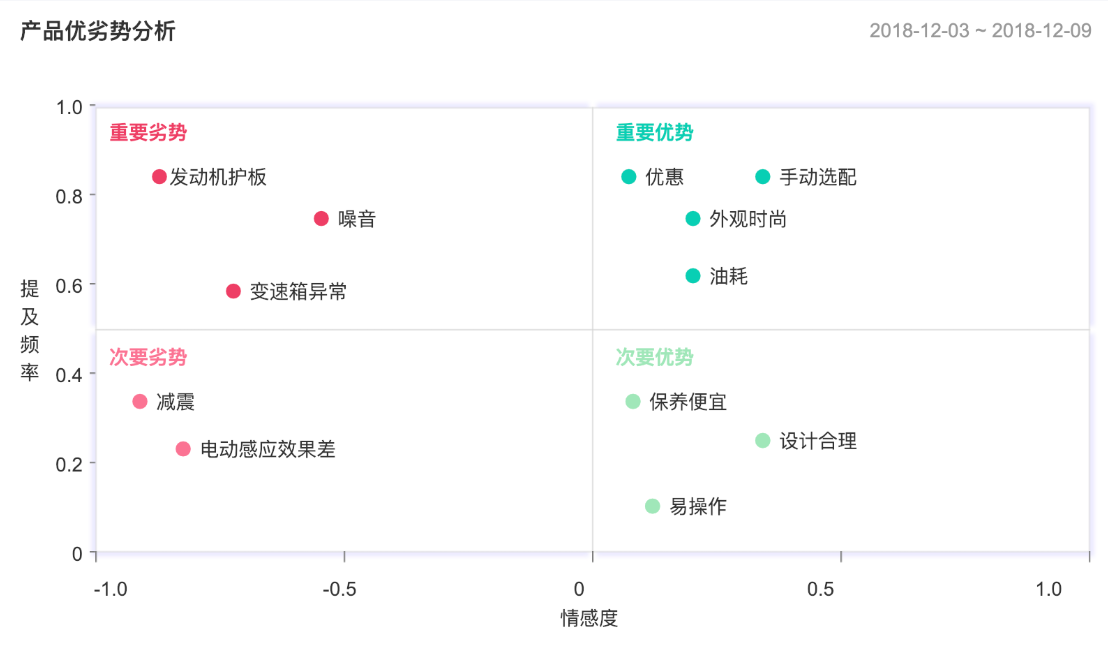
图24 咨询界“法宝”—波士顿诊断矩阵在达观客户意见洞察平台中的应用
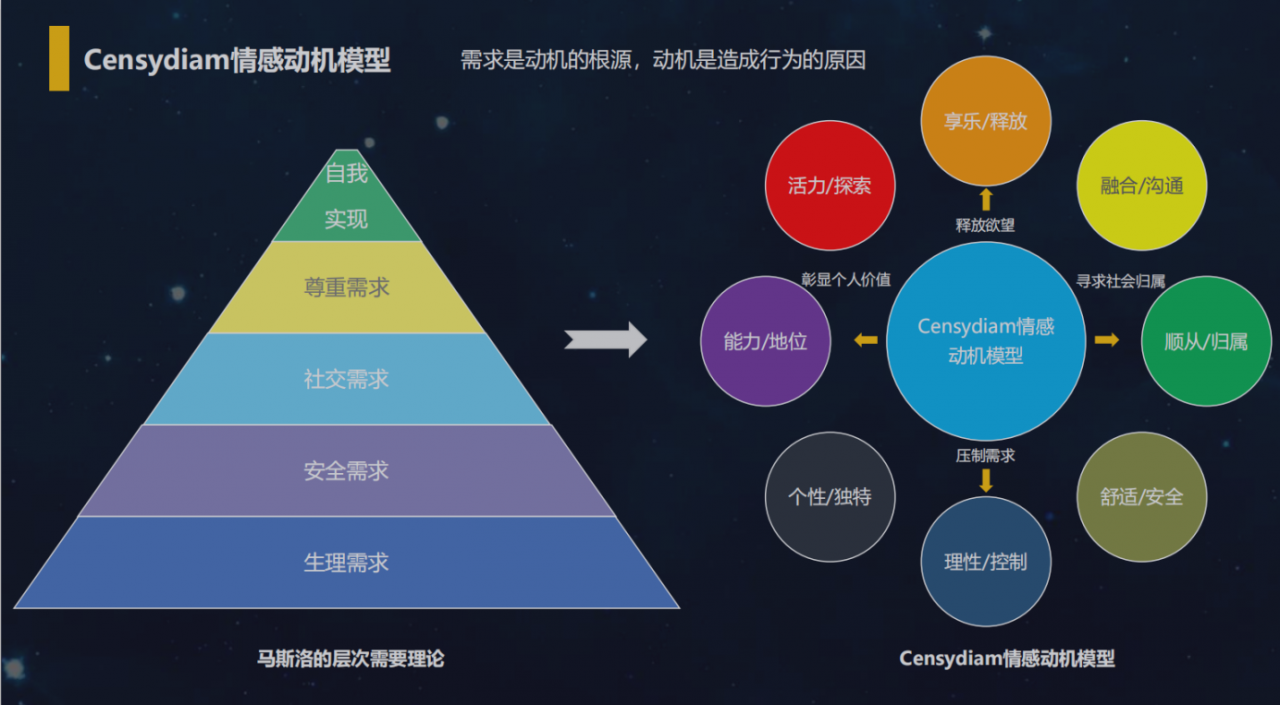
图25 Censydiam可以挖掘用户在做出购买决策时的深层情感动机

图26 Censydiam消费动机模型在旅游领域的应用
3.3 注重业务分类体系的智能化构建
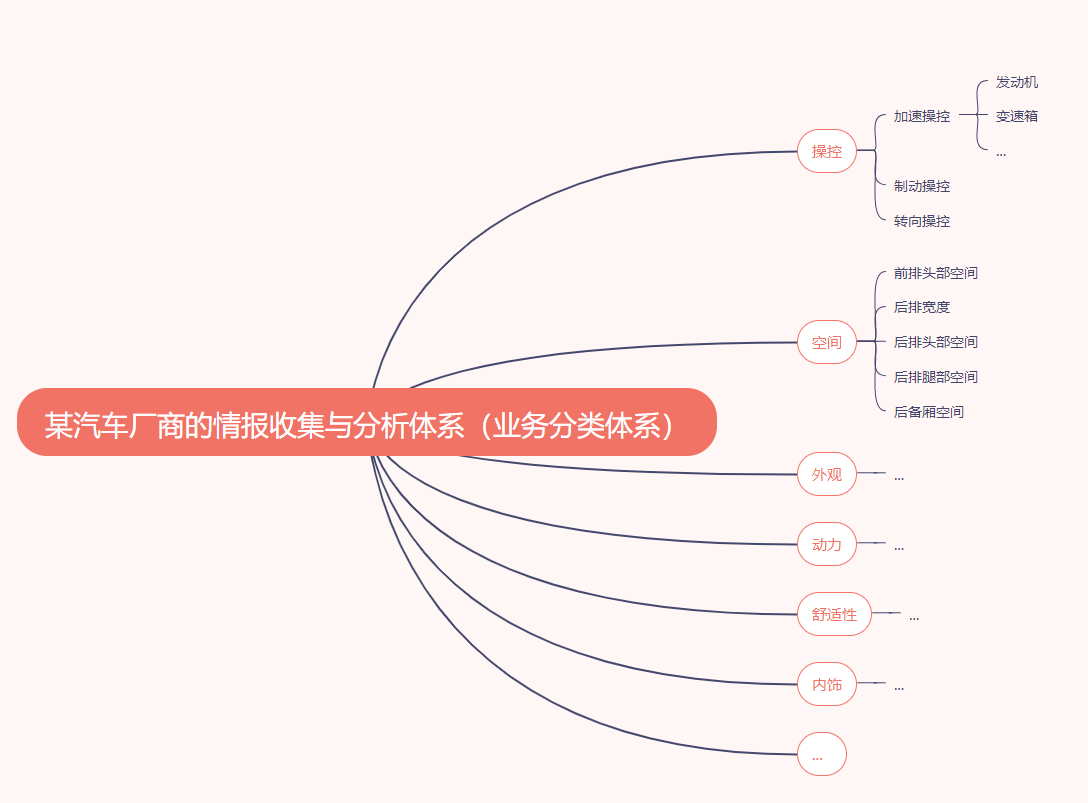
图27 业务分类体系一般是符合MECE原则的多层嵌套结构
在很多涉及语义分析的业务场景中,建立一个符合MECE法则(Mutually Exclusive Collectively Exhaustive,中文内涵为“相互独立,完全穷尽”)的业务分类体系至关重要,因为该业务分类体系体现了企业对其自身业务的认知——产品/品牌/服务中包含哪些要素,哪些要素是相对重要的。该业务分类体系会涉及数据的收集、预处理、分析挖掘,以及数据结果呈现等阶段,不可谓不重要。 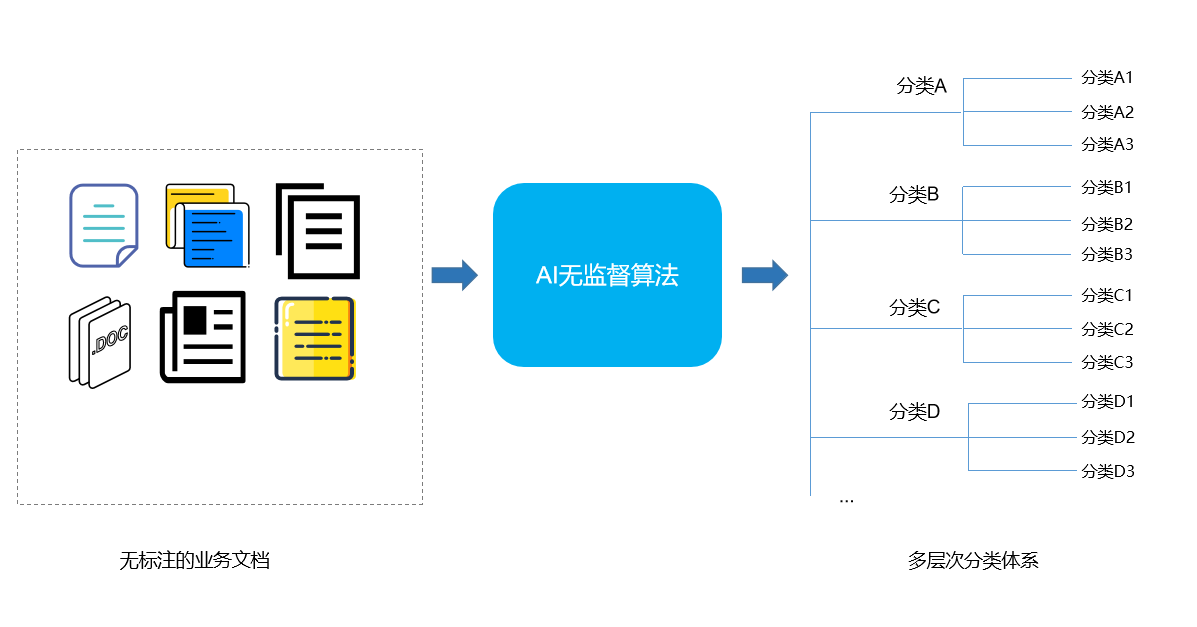
图28 基于无监督AI算法可以从大量无标注的业务语料中发现潜在的业务结构
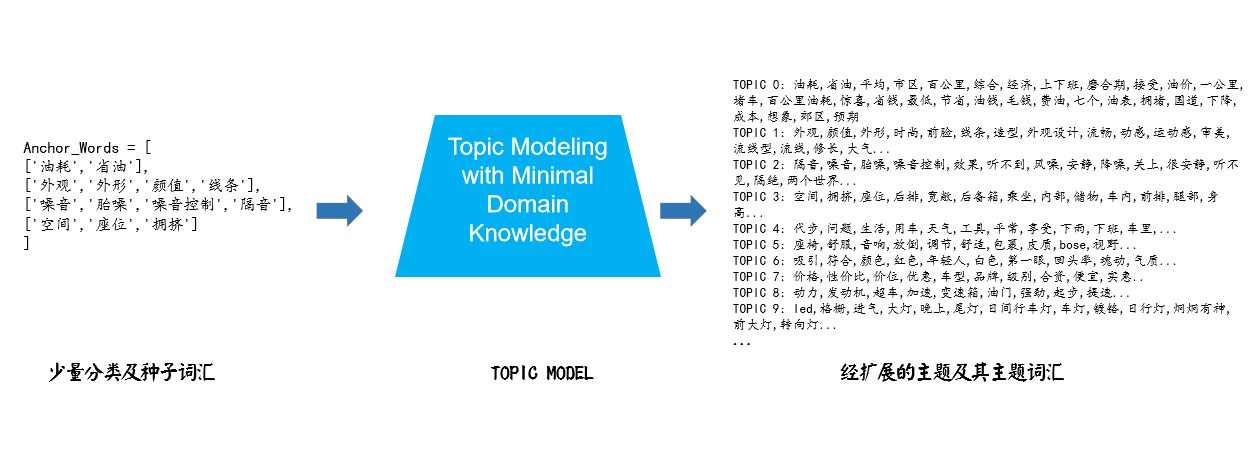
达观客户意见洞察平台在构建客户专属业务指标体系方面有着丰富的经验。一般的,体系的大体框架会由客户方的业务人员梳理出来,同时对方会提供的少量语料(或者分类种子词),达观数据会利用先进的无监督方法挖掘业务体系中的潜在结构(或者扩展分类词汇),辅助业务人员归纳符合自身实际的分类体系,从而提高搭建业务分类体系的效率。

图29 达观数据客户意见洞察平台
基于少许先验知识(即有一定结构的种子词汇)的主题模型可以提高主题划分和主题词拓展的质量。
总体来说,达观数据的客户意见洞察平台充分利用机器学习/深度学习、自然语言处理等前沿人工智能技术,形成“聆听—>分析/预警–>行动–>聆听”的业务闭环,实现客户意见洞察的数据采集、数据处理、模型构建,最终展现可视化智能分析成果。




