在2020年世界人工智能大会云端峰会中,达观数据与浦东青联联合举办了“智能时代,语你同行”行业论坛,围绕语言智能,在云端与多位行业专家与学者展开了一场精彩线上交流盛宴。

同济大学特聘研究员王昊奋教授围绕知识图谱详细介绍了多模态知识图谱的构建、以及大规模知识推理、多策略知识问答等关键技术,并就行业知识图谱在金融、工业互联网、泛传媒、抗疫等领域的实践进行了详细介绍。
以下为演讲内容:
大家好!非常荣幸受邀来到2020年世界人工智能大会由达观数据主办的智能时代 “语”你同行的云端高峰论坛。在经历了互联网和移动互联网的高速发展后,我们积累了很多文本大数据,此外也拥有了大量语音、图像、视频等多模态数据。
面对这样的数据增长与丰富,我们也悄然进入了人工智能的下半场。上半场的人工智能多由感知智能主宰,能够做到能听会说,能看会认。下半场则不满足于模拟人的各种感知能力,而要去提升其认知能力。也就是说,我们开始研究人类大脑并探索认知的机理,从而做到具备能理解、会思考、可解释等特征的认知智能。
2017年国务院发布了新一代人工智能发展规划,科技部、工信部以及国家各部委纷纷发布了各种重大专项指南,布局新一代人工智能。其中有很多词被反复提起,认知出现16次,知识图谱则出现13次。同时大家非常关注在金融、客服、教育、医疗等各个行业的落地。

图1 人工智能的下半场:认知智能
自从2012年谷歌率先提出知识图谱依赖,各大互联网公司和科研院所已经把知识图谱摆到与深度学习同样重要的地位,且作为认知智能的关键技术来进行深入研究。那么知识图谱能够做什么?简而言之两件事情:第一让机器更好地理解数据,第二让机器更好地解释现象。
围绕我们本次主题,知识图谱在各类深度学习的技术中也开始与各种感知智能技术做深入结合,比如图像识别技术、语音识别技术等。另一方面,知识图谱的动态性和多模态性也慢慢成为一种趋势。
知识图谱有完整和清晰的生命周期,主要包含三部分:
-
首先,解决知识从哪里来以及知识图谱如何进行高效构建?
-
其次,知识如何用?在原有知识的基础上,如何进一步发现隐含知识,从而增加额外价值;
-
最后,获得完成的知识图谱后,如何在各种行业和互联网应用中做大规模的智能化赋能是关键。
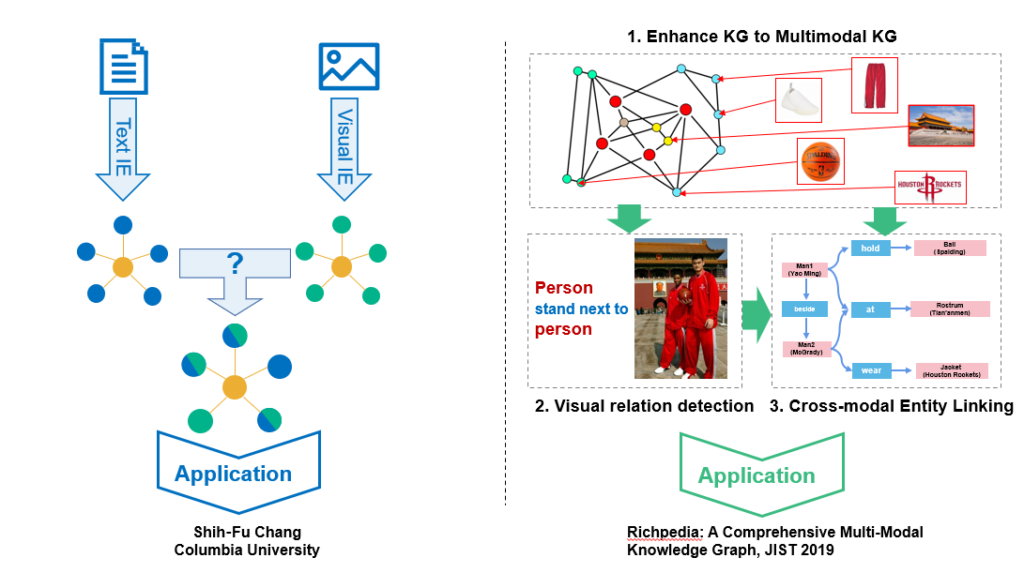
图2 多模态知识图谱构建方法比对
对于知识(尤其是多模态)图谱的构建,传统的做法把将不同模态分别完成抽取并通过图谱融合来形成最后的多模态图谱。如图2左半部分所示,先基于文本和图像进行信息抽取,对于抽取得到的多个特定模态图谱融合成多模态知识图谱。
这样构建形成的多模态图谱存在以下问题:源头上并没有考虑不同模态特征之间的依赖和对应关系,使得最终融合的结果无法很好地刻画多模态数据本身蕴含的各种关联。因此,我们更进一步,使得图谱本身一开始就具备多模态的特性。所构建的多模态图谱能帮助可帮助理解多模态的数据,完成可视关系识别和跨模态实体链接等任务,并进一步应用在问答、搜索、可视分析和辅助决策等方面。
从知识图谱到多模态图谱
如何从传统图谱拓展到多模态图谱?对于图谱中每一个实体或概念,关联相对应的图象。我们希望收集到全天候不同角度、不同方位、以及不同主题下的内容,使得更好的刻画多模态知识,尤其是可视化的关系。由于初始关联的图像比较少,我们进一步采用近似K近邻来做图像扩展,保障相关性的同时也达到多样性的目的从而更完整的表达对应的图谱节点对象。
图3 从KG到多模态KG:图像选取与扩充策略
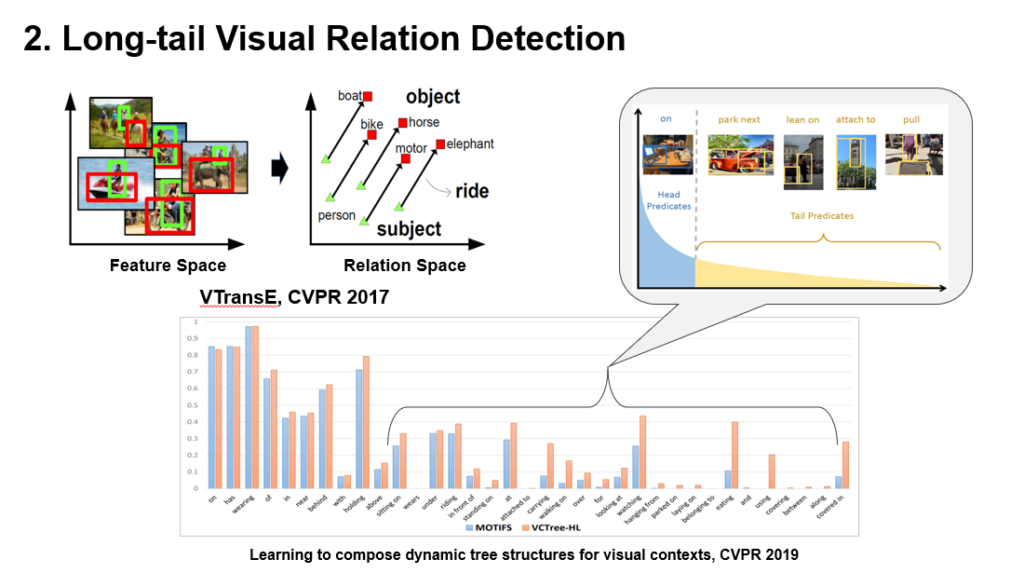
长尾可视关系识别
给定一张图片,我们可以识别到很多对象,在此基础上,进一步可以检测不同对象之间的关系。
-
第二张图里面的红色框代表人,绿色框是摩托车,而两者之间的可视关系是人坐在摩托车上,即 person-on-motorcycle;
-
第三张中的绿框代表的是头盔,可视关系则是人佩戴头盔,即person-wear-helmet;
-
最后一张中红框识别的是摩托车,绿框是轮子,则识别的可视关系是motorcycle-has-wheel等。
可视关系识别是视觉场景理解的关键之一,但是由于可视关系的稀疏性,大量长尾关系的有效预测往往具有很大的难度。计算机视觉顶级会议CVPR 2017中发表的一项工作则,借鉴知识图谱表示学习技术,对经典的基于翻译的表示学习方法TransE进行扩展为VTransE,将图片的可视特征空间映射到关系空间使得在映射后的语义空间中头实体和可视关系的向量和接近于尾实体向量。
这种做法虽然简单易实现,但无法避免TransE在应对一对多、多对多等关系预测时的不足。之后CVPR 2019的改进工作通过学习动态树结构的组合来刻画视觉上下文,并基于此来预测可视关系,从而一定程度上缓解了长尾关系检测难的问题。
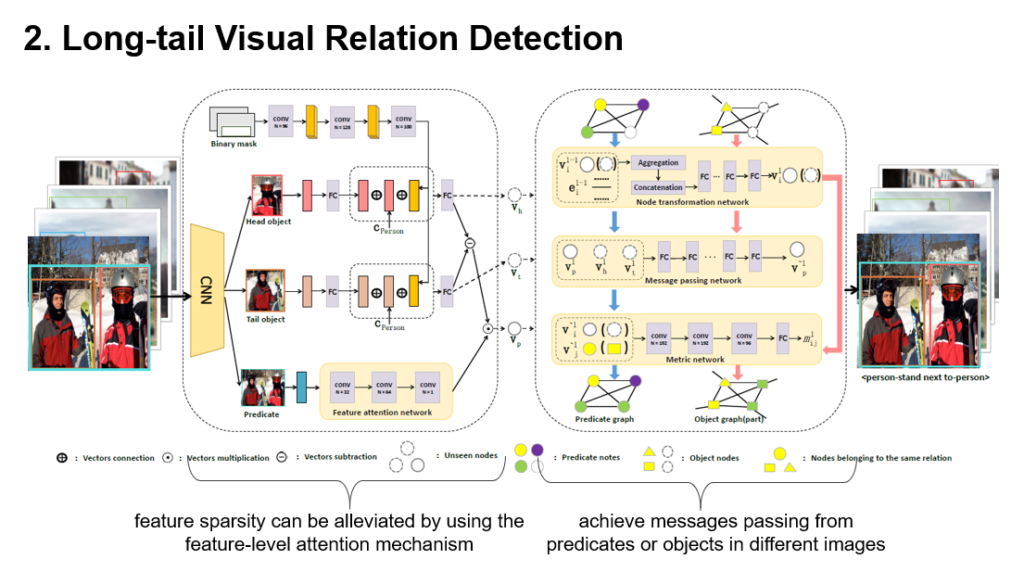
图6 长尾可视关系识别:我们的方法
在上述工作的 基础上,我们利用多模态图谱来进一步优化长尾可视关系的识别效果。首先,在特征非常稀疏的情况下,利用各种模态特征之间的交互去做特征的扩充。其次,利用来自不同图像中的对象或关系之间形成的相似图,通过消息传递,进一步缓解数据层面的稀疏。
跨模态实体链接
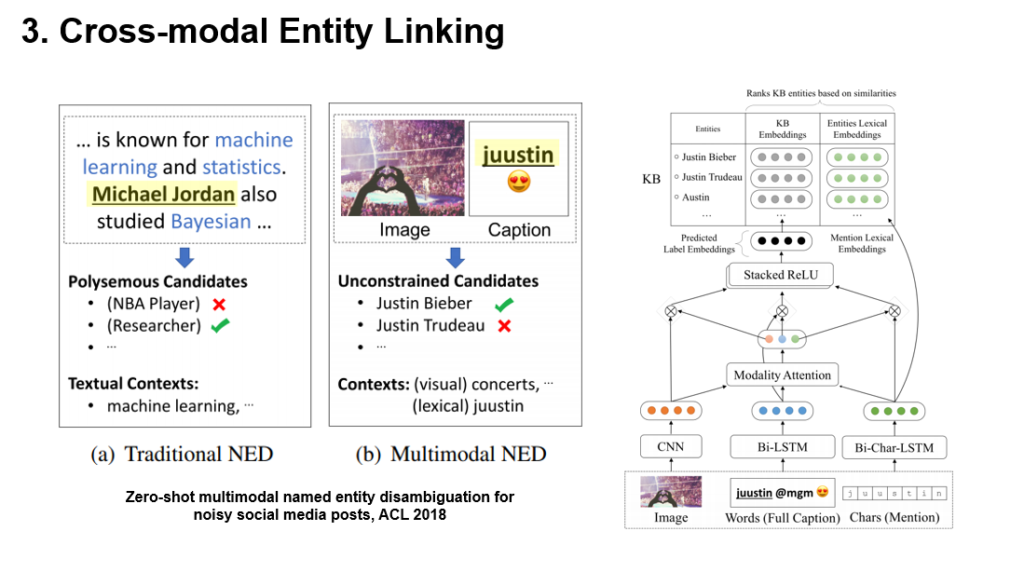
图7 跨模态实体链接典型架构
实体链接在文本智能处理中被广泛应用,在图7左侧(a)的文本中,对于黄色标记的Michael Jordan,自动消歧并将其关联到篮球之神或著名的机器学习和统计学习专家,这个任务我们称之为叫实体链接。图7左侧(b)扩展了实体链接到多模态场景,即给定一张图片和所对应的文本描述,自动判断图片所包含的对象。
对于跨模态实体链接,往往将图片、文字描述和待链接的词或词组采用不同的神经网络(针对图像采用CNN,而文字采用双向LSTM或其变种)并经过包含模态注意力的上层网络得到的mention表示与通过图谱结构与标签描述结合得到的候选实体表示进行语义匹配排序来完成。
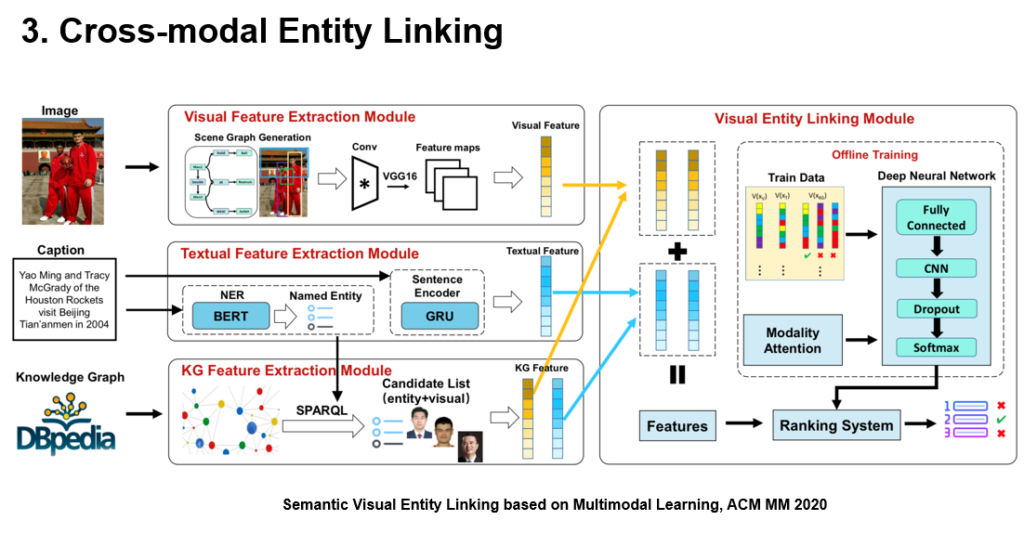
图8 基于多模态交互学习的语义视觉实体链接
我们进一步考虑到不同模态之间的关联关系。在抽取模态特征时考虑图象中不同视觉对象之间的关联,形成一个场景图。同时对于文本描述,也进一步用SOTA模型得到了其中包含的命名实体,这一部分命名实体又作为后续链接的候选项。此外,我们还考虑到模态的注意力机制,使得在选择过程中,既考虑文本模态的特征也考虑视觉特征。
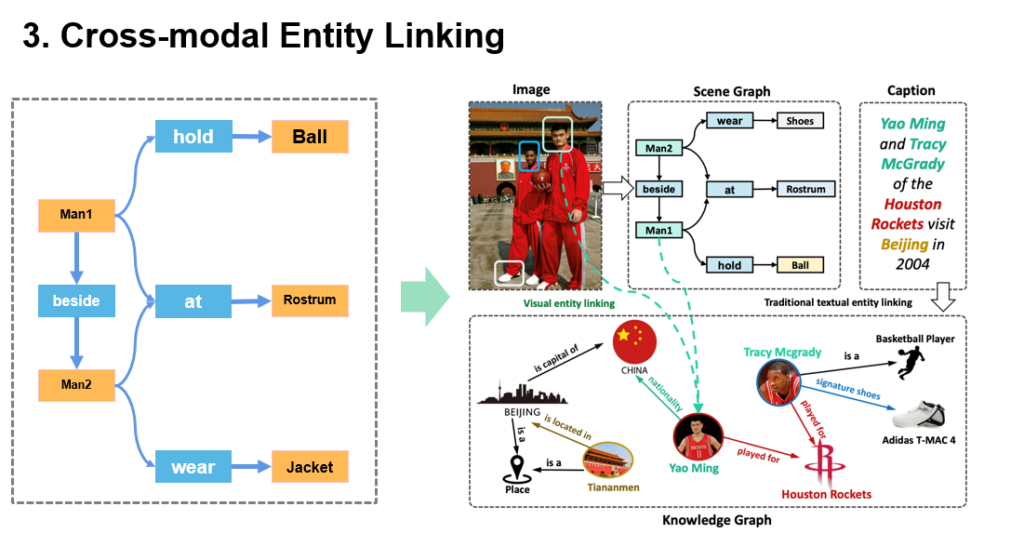
图9 跨模态实体链接示例
如图9所示,姚明与麦迪身穿火箭队队服站在天安门前的照片可以形成左边的场景图,结合文本标题描述,该场景图中的实体(如Man1和Man2)完成了与多模态图谱中的Yao Ming与Tracy Mcgrady的链接。刚刚讲了多模态图谱的构建,那么有了知识后能进一步做什么呢?为了要发现隐含知识,一件很重要的事情是知识推理,即根据现有知识推出新知识或者新事实。一般来说知识推理有四类:
- 第一种是演绎推理,根据前提条件推导出结论,是基于符号逻辑的推理;
- 第二种是归纳推理,根据有限的观察现象推导出后背的原理或机制等,各种机器学习都属于归纳推理范畴;
- 第三种是溯因推理,溯因推理是基于结果反推出原因。往往用于故障发现与诊断时的问题定位和究因分析;
- 第四种是类比推理,进行不同类型的对象或空间之间进行映射对齐,在各种文本蕴含或语义相似度计算时被广泛使用。
图10 神经网络方法用于知识图谱推理
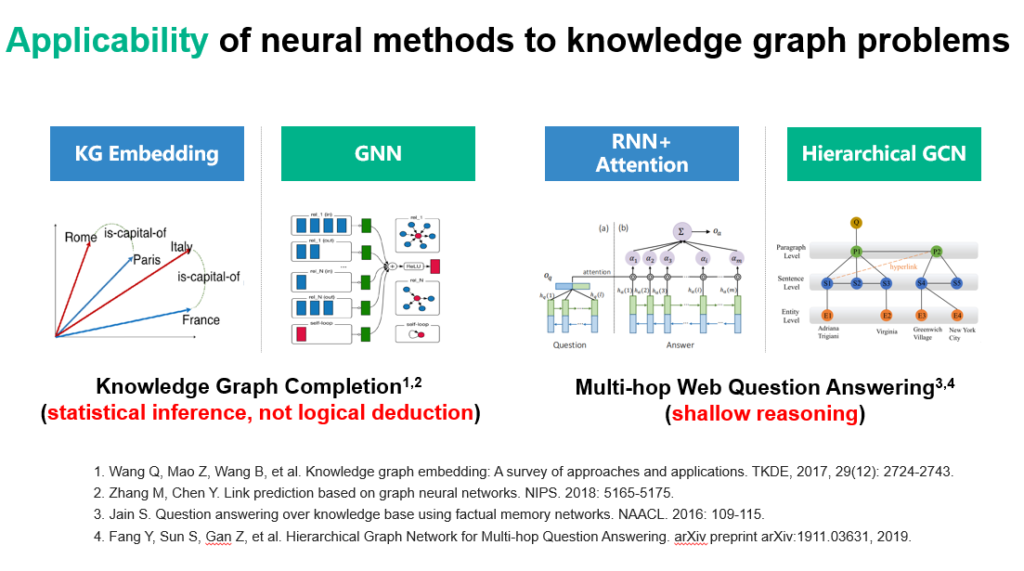
在各种知识推理推理任务中,也越来越多地出现了深度学习的身影。首先,知识图谱或知识库往往是不完备的,这种情况下我们就希望扩充图谱。知识图谱表示学习,以及最近比较火热的图神经网络都被用于该任务中。
同时,各种循环神经网络+注意力机制的网络或层次化图卷积网络及其扩展被广泛用于需要多跳的复杂知识问答中。但问题在于这些方法是基于统计的推断,仅能完成浅层的推理,无法覆盖全部逻辑演绎的能力,导致本身的可解释性有一定这折损。
图11 神经网络方法用于知识图谱推理(续)
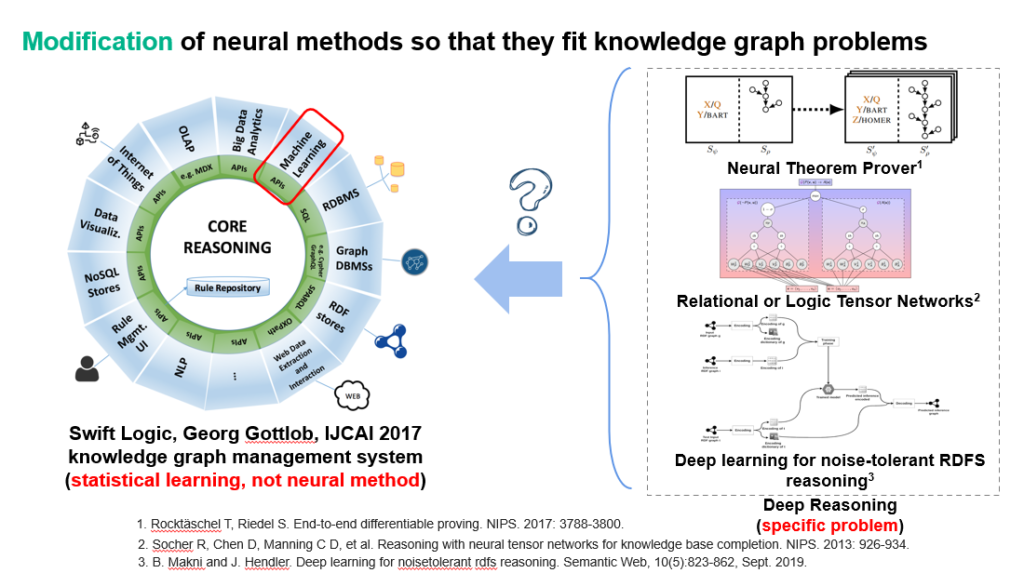
此外,不少工作设计神经网络来完成特定的逻辑推理或公理证明(如图11右侧)。而这些具有语义等价的统计学习可被进一步融合到知识图谱管理系统中,从而同时支持精确的逻辑计算和数据驱动和概率推断(图11左侧)。
深度学习往往需要有大数据的支持。即使在做多模态的问题情况下,很多时候我们面对的都是小数据,数据的稀疏性非常明显。如何利用知识和图谱结构来帮助我们做这样的事情?比如利用知识图谱和远程监督学习来支持数据增广和迁移,以及支持更复杂表达能力(如规则等更强的知识)的表示学习都是目前的通过知识图谱来支持深度学习的不同有益尝试。
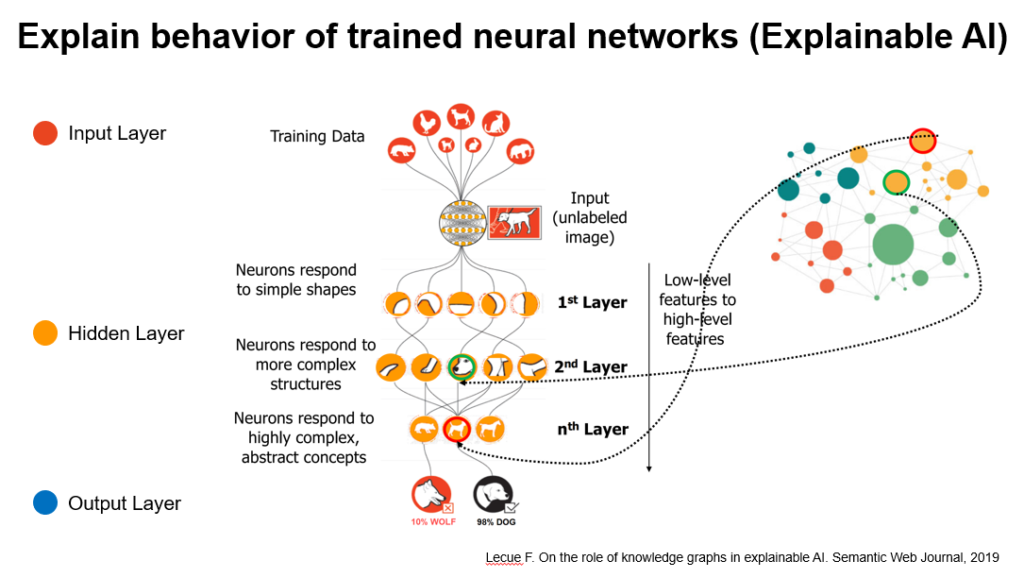
图12 使用知识图谱解释神经网络中间结果
正如之前提及的,认知智能的可解释性非常关键。为了让深度学习使用的神经网络模型可以在各种辅助决策任务中更好的使用,通过对通过非线性变换得到的中间结果进行解码映射到知识图谱中的相应节点,方便人们更好理解。
除了知识推理,另一种多模态情况下的典型应用是问答。问答经历了很多过程,包括上世纪90年代的检索式问答,基于众包社区的问答,以及在个人助理和各种行业中的知识问答。现在我们希望把上述各种互补的技术进行融合来支持不同类型数据上的多策略问答。
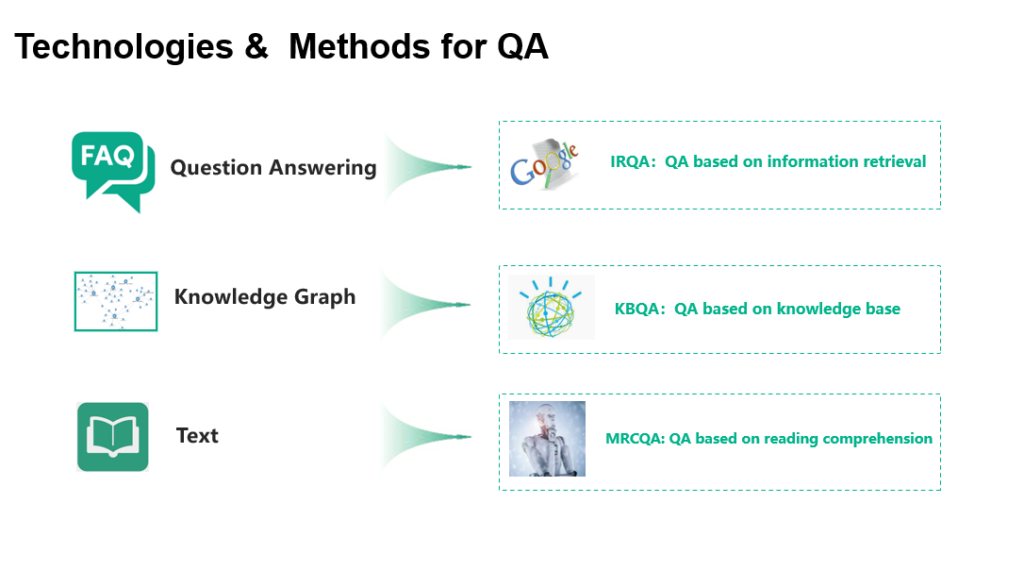
具体来说,如图13所示,面对问答对型数据,可采用基于检索的问答技术即IRQA,而面对结构化程度比较好的图谱数据,可采用基于知识库的问答即KBQA,而面对文本或语料库数据,则可采用基于机器阅读理解的问答即MRCQA。
随着预训练模型的普及, 从最早的word2vec/ glove,到后续的上下文感知的模型如ELMO、GPT和BERT等,使得我们在大规模通用语料上训练得到的模型的基础上,在下游任务中(如这里的问答)使用少量的领域数据进行精调来完成。
图13 典型的问答数据和技术范式
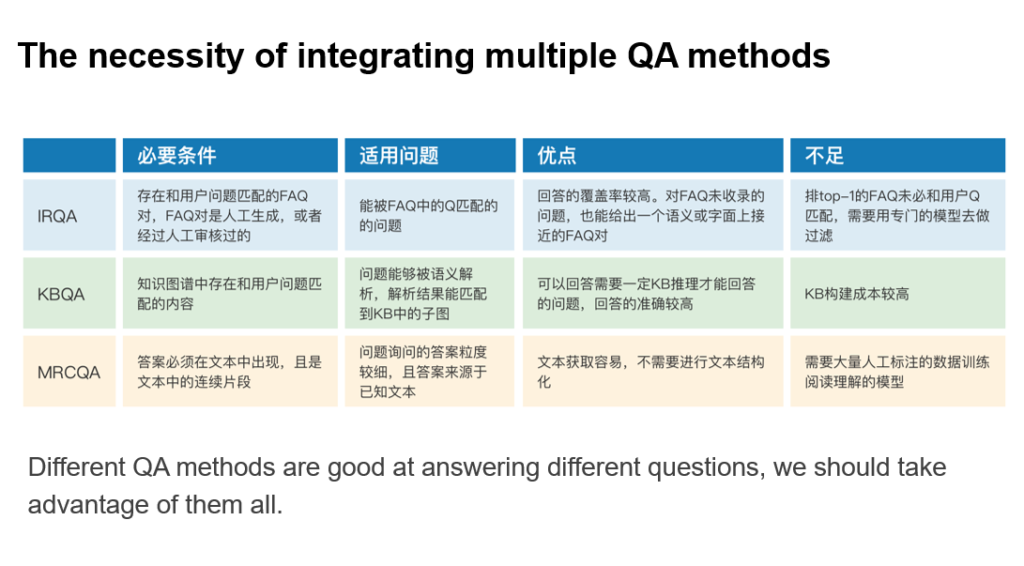
同时,每一种问答技术都有其可被使用的必要条件,适用的问题范围,以及相应的优点和不足(具体描述如图14)。为了完成能在真实场景中可用的问答系统,需要采用多策略方式来综合不同问答系统的优点。
图14 多种问答技术的优缺点
多模态知识图谱的典型应用
下面举几个多模态知识图谱的典型应用:
金融证券领域
例如在金融证券领域,一个典型应用是最终控制人识别。这是通过利用散落在各地方的不同源的数据,特别是多模态数据,进行整合后我们可以发现他们之间的蛛丝马迹,并最后找到隐藏在背后的最终控制人。同时也可以应用在信用风险评估和关联交易预警等方面。

工业互联网
在工业互联网中,可以应用在电力系统的故障识别。这其中涉及多学科知识,也有多模态知识,需要通过各种计算得到相应的经验公式结果,同时通过神经网络识别对应的异常,转换对应故障检测和分类问题,应用溯因推理的技术,能够发现可能的原因并推荐相关的检测方案。
我们相信在智能时代“语”你同行的蓝图下,多模态和知识图谱将在金融、客服、教育、医疗等领域发挥更多作用。