
摘要
1、围棋是一个MDPs问题
2、policy iteration如何求解MDPs问题?
3、WHAT and WHY is MonteCarlo method?
4、AlphaGo Zero的强化学习算法
AlphaGo是GoogleDeepMind团队开发的一个基于深度神经网络的围棋人工智能程序,其一共经历了以下几次迭代[1]:
以4-1击败世界冠军李世石,较于上一版本,其使用了更复杂的网络结构,在生成训练数据时,使用了更加强大的模拟器;
AlphaGo Master在网络上与人类棋手的对阵中保持了60不败的战绩,与之前版本不同的是,只使用了一个神经网络;
DeepMind公开了最新版本的AlphaGo Zero,此版本在与2016年3月版的AlphaGo的对阵中取得了100-0的战绩,并且,在训练中未使用任何手工设计的特征或者围棋领域的专业知识,仅仅以历史的棋面作为输入,其训练数据全部来自于self-play。
一个马尔可夫决策过程(Markov Decision Processes,MDPs)通常包括以下几个要素:
1)状态集合![]() ,包含MDPs可能处在的各个状态;
,包含MDPs可能处在的各个状态;
2)动作集合![]() ,包含MDPs在各个状态上可采取的动作;
,包含MDPs在各个状态上可采取的动作;
3)转换概率![]() ,表示在状态
,表示在状态![]() 上采取动作
上采取动作![]() 后,下一个状态的概率分布;
后,下一个状态的概率分布;
4)回报函数![]() ,
,![]() 表示状态
表示状态![]() 的回报。
的回报。
在定义了以上几个要素之后,我们可以来描述一个典型的MDPs:从某个起始状态![]() 开始,选择采取动作
开始,选择采取动作![]() ,然后,以
,然后,以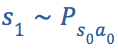 的概率转换到下一个状态
的概率转换到下一个状态![]() ,然后采取动作
,然后采取动作![]() ,并以
,并以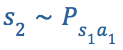
![]()
的概率转换到下一个状态……
如果MDPs的状态集合和动作集合是有限大的,则称之为有限MDPs。
通常,我们还会定义另外一个参数——折扣因子(discountfactor)![]() 。定义折扣因子之后,MDPs的总回报可以表示为:
。定义折扣因子之后,MDPs的总回报可以表示为:![]() 。
。
MDPs的核心问题是如何找到一个对所有状态都适用的最优策略,按照此策略来选择动作,使总回报的期望最大化。在总回报中加入折扣因子后,为使总回报的期望最大化,须尽可能的将正向回报提前,负向回报推迟。
回想一下围棋的对弈,起始状态是一个空的棋盘,棋手根据棋面(状态)选择落子点(动作)后,转换到下一个状态(转换概率为:其中一个状态的概率为1,其他状态的概率为0),局势的优劣是每个状态的回报。棋手需要根据棋面选择合适落子点,建立优势并最终赢下游戏,因此,围棋可以看作是一个MDPs问题。(达观数据)
定义一个策略𝜋的状态值函数(state-valuefunction)为: ![]()
等式右半部即为总回报的期望值。展开等式的右半部分: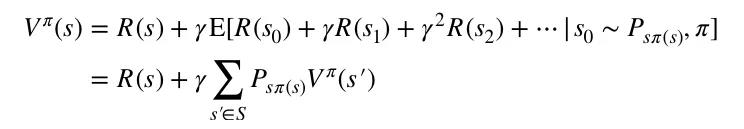
上面的等式称作贝尔曼方程(Bellman equation),从贝尔曼方程可以看出,当前状态的回报的期望包括两部分:
1)当前状态的立即回报;
2)后续状态的回报的期望和与折扣因子之积。
定义最优状态值函数(optimal state-value function)为: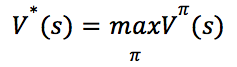
根据贝尔曼方程有: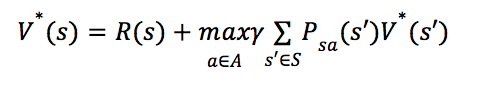
定义策略为: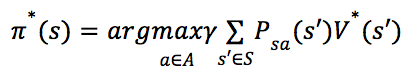
对于任意状态![]() 和任意策略𝜋,均有:
和任意策略𝜋,均有: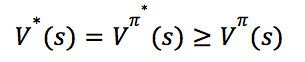
因此,策略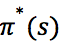 即为最优策略。
即为最优策略。
最优策略可通过策略迭代来求解。一次策略迭代包括两个步骤:
1)策略估计(PolicyEvaluation):基于当前的策略和状态值函数根据贝尔曼方程更新状态值函数;
2)策略提升(PolicyImprovement):基于当前的策略和1)中更新后的状态值函数来更新策略。
策略迭代求解MDPs问题的算法如图1所示[2]。
图1 策略迭代算法
为证明算法的收敛性,定义动作值函数(action-value function)为: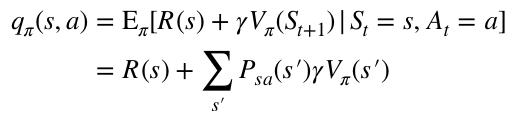
假设有两个策略![]() 和
和![]() ,对于任意状态
,对于任意状态![]() 均有
均有![]() ,那么,对于任意状态
,那么,对于任意状态![]() ,不等式
,不等式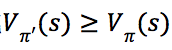 成立,即策略
成立,即策略![]() 优于策略
优于策略![]() 。
。
因此,在策略迭代中,每一次策略提升后,将得到一个更优的解。对于有限MDPs,策略的个数是有限的,在经过有限次的迭代之后,策略将收敛于最优解。(达观数据)
在策略迭代中,为了估计状态值函数,需要计算并存储所有状态的值函数。在围棋中,有超过2 x 10170的状态[3],远远超出了计算或存储的极限,因此,策略迭代的方法不再适用。
蒙特卡洛方法(Monte Carlo Method)通过模拟采样来估计状态值函数和动作值函数,将采样结果的均值作为估计值,根据大数定律,随着采样次数的增加,估计值将趋近于实际值。蒙特卡洛方法适用于“情节任务(episodic tasks)”,即不管使用哪种策略,最终都能到达终止状态,围棋是一种“情节任务”。蒙特卡洛方法对各个状态的估计是相互独立的,即在估计状态值函数或动作值函数时不依赖于其他状态的值函数,因此,不需要计算或存储所有状态的值函数。
为估计策略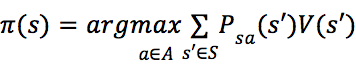 的动作值函数
的动作值函数![]() ,把初始状态置为
,把初始状态置为![]() ,然后开始模拟采样,在
,然后开始模拟采样,在![]() 状态上采取动作
状态上采取动作![]() ,转换到下一个状态,在后续的状态中,依据策略𝜋来选择动作,直到到达终止状态,记录下此时的回报。重复执行以上操作。对于路径上的每一个状态–动作对(state-actionpair),将所有包含此状态–动作对的模拟的回报的均值作为动作值函数
,转换到下一个状态,在后续的状态中,依据策略𝜋来选择动作,直到到达终止状态,记录下此时的回报。重复执行以上操作。对于路径上的每一个状态–动作对(state-actionpair),将所有包含此状态–动作对的模拟的回报的均值作为动作值函数![]() 的估计值。以上过程称之为“深耕(exploitation)”,即在现有的知识下,将每一步都做到最好。
的估计值。以上过程称之为“深耕(exploitation)”,即在现有的知识下,将每一步都做到最好。
策略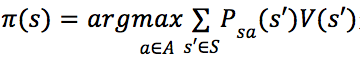 是贪婪的,即在每个状态上均以P=1的概率选择当前最优的动作
是贪婪的,即在每个状态上均以P=1的概率选择当前最优的动作![]() ,因此,对于任意动作
,因此,对于任意动作![]() ,状态–动作对
,状态–动作对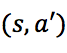 都不会被选择,其动作值函数也不会被估计。估计动作值函数的目的是帮助我们在状态上选择合适的动作,为了比较动作的收益,我们还需要估计这个状态上
都不会被选择,其动作值函数也不会被估计。估计动作值函数的目的是帮助我们在状态上选择合适的动作,为了比较动作的收益,我们还需要估计这个状态上![]() 其他的动作的值函数。为了估计其他动作的值函数,一种常用的方法是
其他的动作的值函数。为了估计其他动作的值函数,一种常用的方法是![]() 策略,其中
策略,其中![]() 是一个接近于0的小数,对于每一个状态
是一个接近于0的小数,对于每一个状态![]() ,以
,以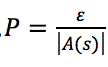 的概率选择非贪婪动作
的概率选择非贪婪动作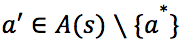 ,以
,以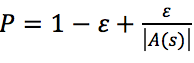 的概率选择贪婪动作
的概率选择贪婪动作![]() 。以上过程称之为“探索(exploration)”,即不满足于眼前的最好,探索未知中可能存在的更好。
。以上过程称之为“探索(exploration)”,即不满足于眼前的最好,探索未知中可能存在的更好。
在蒙特卡洛方法中,“深耕”使得我们更多的在最有希望的方向上搜索,而“探索”使得我们能够同时兼顾到其他方向。(达观数据)
AlphaGo Zero的网络架构
围棋的棋面可以看作是一个19 × 19的图像,每一个棋子对应一个像素点,不同颜色的棋子对应不同的像素值。考虑到深度神经网络,尤其是卷积神经网络在图像领域的成功应用,AlphaGo使用卷积神经网络来估计当前的局面,选择落子的位置。(
AlphaGo Zero所使用的卷积神经网络的输入是19× 19 × 17的张量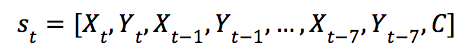 其17个通道中,
其17个通道中,![]() 表示t时刻棋盘上第i个位置是否有己方的棋子,
表示t时刻棋盘上第i个位置是否有己方的棋子,![]() 表示t时刻棋盘上第i个位置是否有对方的棋子,C是一个常数,用于标识当前轮次的颜色;网络包括两个输出,值函数
表示t时刻棋盘上第i个位置是否有对方的棋子,C是一个常数,用于标识当前轮次的颜色;网络包括两个输出,值函数![]() 和策略
和策略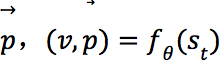 ,
,![]() 是网络的参数,输出值函数的分支称之为值网络(Value network),输出策略的分支称之为策略网络(Policy network)。在之前的版本中,值网络和策略网络是两个同架构但分立的网络,在AlphaGo Zero中,这两个网络合并成一个网络[4]。
是网络的参数,输出值函数的分支称之为值网络(Value network),输出策略的分支称之为策略网络(Policy network)。在之前的版本中,值网络和策略网络是两个同架构但分立的网络,在AlphaGo Zero中,这两个网络合并成一个网络[4]。
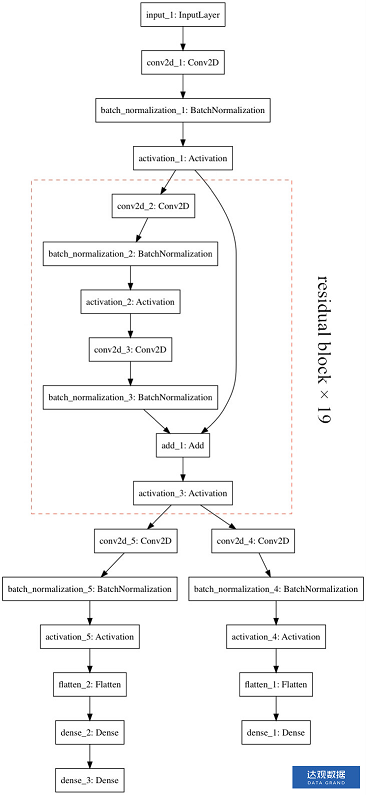
图2 AlphaGo Zero网络架构
策略迭代与蒙特卡洛树搜索
蒙特卡洛树搜索使用蒙特卡洛方法估计搜索树上的每个节点的统计量。AlphaGo将策略迭代与蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)结合了起来。对于每个状态![]() ,根据策略网络输出的策略
,根据策略网络输出的策略![]() 选择动作,执行MCTS。MCTS输出策略
选择动作,执行MCTS。MCTS输出策略![]() ,通常这个策略要比策略网络输出的策略
,通常这个策略要比策略网络输出的策略![]() 更加健壮,因此,这个过程可以看作是策略迭代中的策略提升;根据MCTS输出的策略
更加健壮,因此,这个过程可以看作是策略迭代中的策略提升;根据MCTS输出的策略![]() 选择动作,并转换到下一个状态
选择动作,并转换到下一个状态![]() ,然后执行MCTS…,直到终止状态(游戏结束),将游戏的胜者
,然后执行MCTS…,直到终止状态(游戏结束),将游戏的胜者![]() 作为模拟的结果,这个过程可以看作是策略迭代中的策略估计,如图3(a)所示。
作为模拟的结果,这个过程可以看作是策略迭代中的策略估计,如图3(a)所示。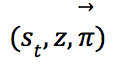 作为一个训练样本,用于训练神经网络
作为一个训练样本,用于训练神经网络![]() ,更新网络参数
,更新网络参数![]() ,如图3(b)所示。在后续的策略迭代中,使用更新后的神经网络来指导MCTS。
,如图3(b)所示。在后续的策略迭代中,使用更新后的神经网络来指导MCTS。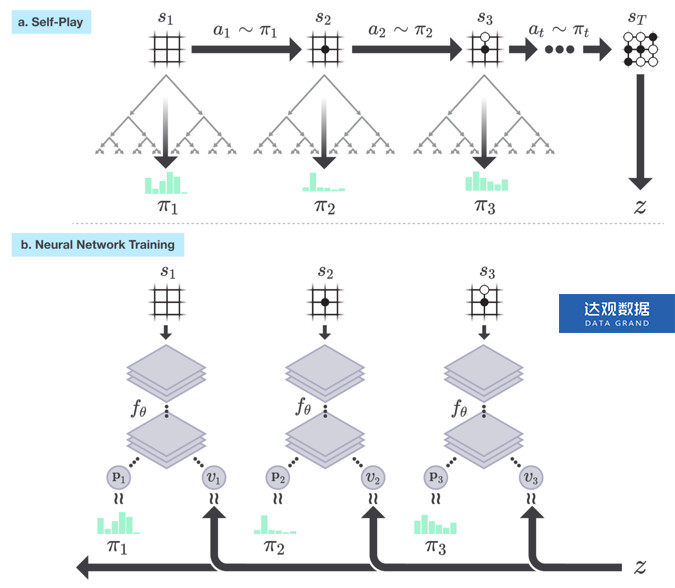
图3 AlphaGo的强化学习算法
2.1 策略提升
在MCTS的过程中,搜索树上的每个节点![]() 的每条边
的每条边![]() 维护一个集合
维护一个集合![]() ,其中,
,其中,![]() 是此条边被访问的次数,
是此条边被访问的次数,![]() 是总的动作值函数,
是总的动作值函数,![]() 是平均动作值函数,
是平均动作值函数,![]() 是在状态采取动作
是在状态采取动作![]() 的先验概率。
的先验概率。
策略提升的一次搜索过程包括以下几个步骤:
1)对于从根节点![]() 到叶节点
到叶节点![]() 之间的每个节点
之间的每个节点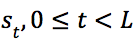 ,动作的选择策略是
,动作的选择策略是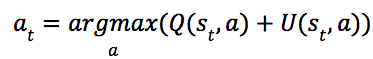 ,其中
,其中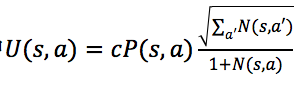 ,c用于控制策略中“探索”的比重,当c=0时,该策略即为贪婪策略,如图4(a)所示。
,c用于控制策略中“探索”的比重,当c=0时,该策略即为贪婪策略,如图4(a)所示。
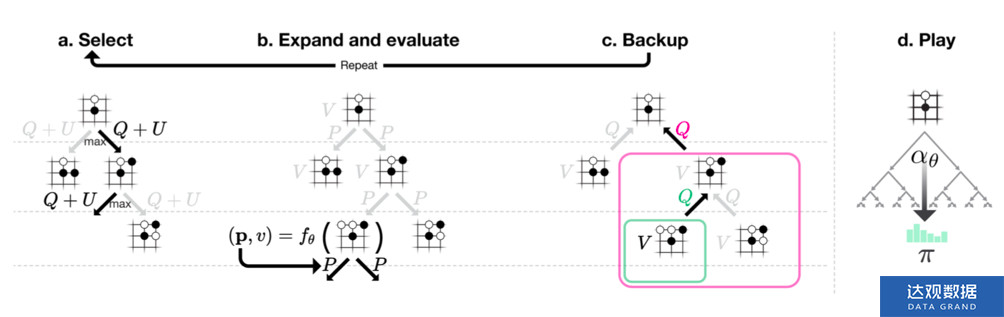
图4 MCTS
在MCTS的初期,该策略倾向于选择先验概率大、访问次数少的动作,随着搜索的进行,将更多地选择值函数大的动作。此外,为了鼓励“探索”,对于根节点![]() 还会在其策略上叠加一个狄利克雷(Dirichlet)噪声,
还会在其策略上叠加一个狄利克雷(Dirichlet)噪声,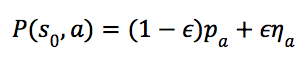 ,其中
,其中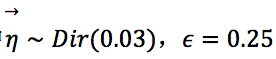 。
。
2)在搜索到达叶节点![]() 后,将
后,将![]() 输入到神经网络
输入到神经网络![]() 中计算值函数和策略
中计算值函数和策略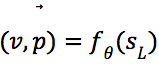 。对于此节点的每条边
。对于此节点的每条边![]() ,初始化其集合为:
,初始化其集合为:
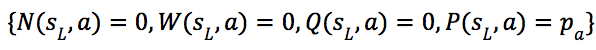 其中
其中![]() 是
是![]() 中
中![]() 动作的先验概率,如图4(b)所示。
动作的先验概率,如图4(b)所示。
3)备份,更新搜索路径上节点![]() 的边
的边![]() 的集合中的元素
的集合中的元素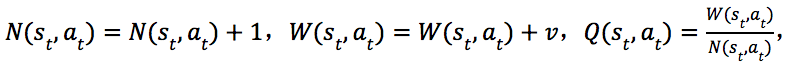
如图4(c)所示。 在多次搜索之后,根据根节点![]() 上的各条边
上的各条边![]() 的访问次数
的访问次数![]() 输出策略
输出策略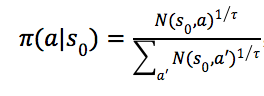
,![]() 是温度参数,用于控制“探索”的比重,如图4(d)所示。
是温度参数,用于控制“探索”的比重,如图4(d)所示。
2.2 策略估计
在状态![]() 上,按照策略提升返回的策略
上,按照策略提升返回的策略![]() 选择落子位置
选择落子位置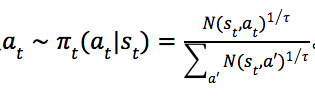 。在游戏的初期(前30手,
。在游戏的初期(前30手,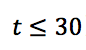 ),为了鼓励“探索”、提升棋局的多样性,将温度参数
),为了鼓励“探索”、提升棋局的多样性,将温度参数![]() 的值设为1,即,选择落子位置
的值设为1,即,选择落子位置![]() 的概率正比于节点
的概率正比于节点![]() 的这条边在策略提升中被访问的次数;在30手之后,温度参数
的这条边在策略提升中被访问的次数;在30手之后,温度参数![]() ,此时,策略是贪婪的,以P=1的概率选择访问次数最多的边。
,此时,策略是贪婪的,以P=1的概率选择访问次数最多的边。
在![]() 状态上执行
状态上执行![]() 动作后,进入到下一个状态
动作后,进入到下一个状态![]() ,将搜索树上
,将搜索树上![]() 所对应的节点作为新的根节点,执行MCTS,返回提升后的策略
所对应的节点作为新的根节点,执行MCTS,返回提升后的策略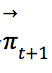 ,…,直到游戏结束,将游戏的胜者
,…,直到游戏结束,将游戏的胜者![]() 作为状态
作为状态![]() 的值函数的估计值。
的值函数的估计值。
这个过程即self-play。为了提高搜索的效率,在策略提升时,当搜索到叶节点后,使用值网络估计状态值函数作为收益返回,避免继续向下搜索,限制搜索的深度;在策略估计时,使用策略提升输出的策略来指导动作的选择,限制搜索的广度。另外,如果值网络估计的局势的收益(胜率)低于一个阈值之后,便放弃此局游戏。
2.3 旋/翻转不变性
将围棋的棋盘旋转或翻转之后,不会影响局势,落子的位置也只需要做相应的变换即可。即,如果状态![]() 被旋转或翻转,值网络的输出
被旋转或翻转,值网络的输出![]() 不变,策略网络的输出
不变,策略网络的输出![]() 做相应的变换,假设d为变换函数,则有
做相应的变换,假设d为变换函数,则有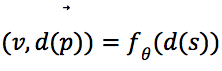 。在策略提升中,当搜索到达叶节点后,从8种旋/翻转变换中随机地选取一种对叶节点的状态进行变换,变换之后的状态作为神经网络的输入。
。在策略提升中,当搜索到达叶节点后,从8种旋/翻转变换中随机地选取一种对叶节点的状态进行变换,变换之后的状态作为神经网络的输入。
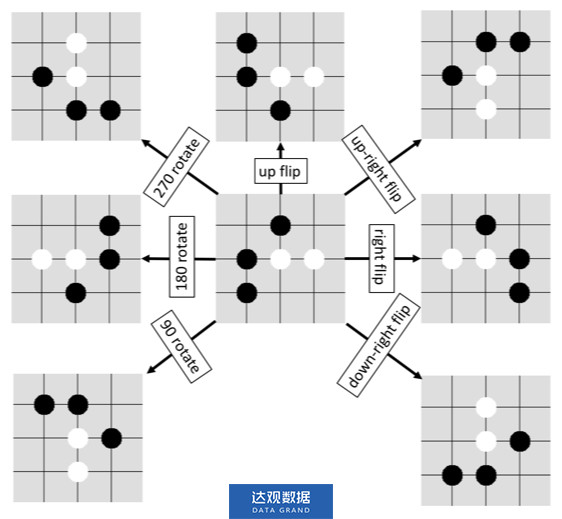
图5 旋转和翻转
模型优化
在self-play的每一局游戏中,会生成一系列的状态–策略–值元组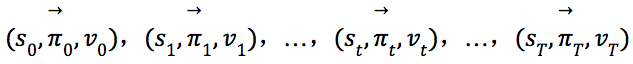
这一系列状态是强关联的。为了避免过拟合这种关联,每局游戏只随机地选择一个元组来组成训练集[5]。
模型优化的损失函数是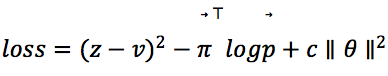 ,其中,第一项为值网络的输出与self-play实际结果的均方误差,第二项为策略网络的输出与策略提升的输出的交叉熵,第三项为L2正则项。在损失函数中,由于
,其中,第一项为值网络的输出与self-play实际结果的均方误差,第二项为策略网络的输出与策略提升的输出的交叉熵,第三项为L2正则项。在损失函数中,由于![]() ,(值网络的最后一层使用tanh激活函数),因此,均方误差对损失函数的贡献被限定在范围内。给予均方误差和交叉熵相同的权重,避免由于过拟合了状态值函数而出现“模型能够精准预测游戏胜负却输出糟糕的策略”的现象。
,(值网络的最后一层使用tanh激活函数),因此,均方误差对损失函数的贡献被限定在范围内。给予均方误差和交叉熵相同的权重,避免由于过拟合了状态值函数而出现“模型能够精准预测游戏胜负却输出糟糕的策略”的现象。
模型参数更新使用带动量和学习率衰减的随机梯度下降方法,动量因子设为0.9,学习率在优化的过程中从0.01衰减到0.0001。每次从最近的500,000局游戏中随机地选取一个大小为2048的mini-batch,每1000次更新之后,对模型进行评估。
模型评估
更新后的模型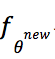 与当前最优的模型
与当前最优的模型![]() 对战400局,即,在策略提升中,分别使用和
对战400局,即,在策略提升中,分别使用和![]() 来估计叶节点的值函数和各条边的先验概率,在选择落子位置时,温度参数
来估计叶节点的值函数和各条边的先验概率,在选择落子位置时,温度参数![]() ,在每一步均贪婪地选择访问次数最多的边。如果新模型的胜率大于55%,则新模型成为当前最优的模型,并使用此模型进行self-play生成训练数据,以确保训练数据的质量。
,在每一步均贪婪地选择访问次数最多的边。如果新模型的胜率大于55%,则新模型成为当前最优的模型,并使用此模型进行self-play生成训练数据,以确保训练数据的质量。
人工智能在很多领域已经显示出了超越人类的水准,并且还在不断的攻城略地。达观数据作为中国知名的文本智能处理企业,利用先进的文字语义自动分析技术,为企业、政府等各大机构提供文本自动抽取、审核、纠错、搜索、推荐、写作等智能软件系统,让计算机代替人工实现业务流程自动化,大幅度提高企业效率。
[1]https://deepmind.com/research/alphago/
[2]Sutton, R.S. and Barto, A.G., 2011. Reinforcement learning: An introduction.
[3]https://en.wikipedia.org/wiki/Go_(game)
[4]Silver, David, et al.”Mastering the game of Go without human knowledge.” Nature 550.7676 (2017): 354
[5]Silver, David, et al.”Mastering the game of Go with deep neural networks and treesearch.” nature 529.7587 (2016): 484
BOUT
关于作者
刘思乡:
达观数据数据挖掘工程师,负责达观数据推荐系统的开发和部署,对推荐系统在相关行业中的应用有浓厚兴趣。




