
从信息获取的角度来看,搜索和推荐是用户获取信息的两种主要手段。无论在互联网上,还是在线下的场景里,搜索和推荐这两种方式都大量并存,那么推荐系统和搜索引擎这两个系统到底有什么关系?区别和相似的地方有哪些?本文作者有幸同时具有搜索引擎和推荐系统一线的技术产品开发经验,结合自己的实践经验来为大家阐述两者之间的关系、分享自己的体会(达观数据陈运文博士)
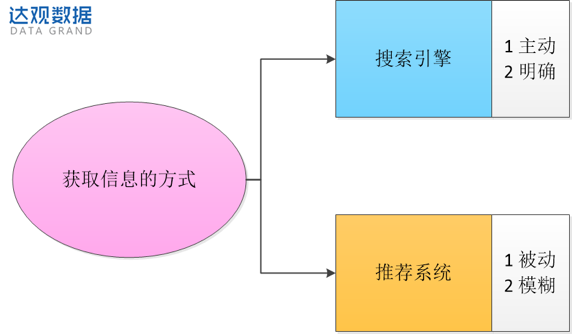
图1:搜索引擎和推荐系统是获取信息的两种不同方式
主动或被动:搜索引擎和推荐系统的选择
获取信息是人类认知世界、生存发展的刚需,搜索就是最明确的一种方式,其体现的动作就是“出去找”,找食物、找地点等,到了互联网时代,搜索引擎(Search Engine)就是满足找信息这个需求的最好工具,你输入想要找的内容(即在搜索框里输入查询词,或称为Query),搜索引擎快速的给你最好的结果,这样的刚需催生了Google、百度这样的互联网巨头。
但是获取信息的方式除了搜索外,还有另一类,称为推荐系统(Recommendation System,简称Recsys),推荐也是伴随人类发展而生的一种基本技能,你一定遇到这样的场景,初来乍到一个地方,会找当地的朋友打听“嗨,请推荐下附近有啥好吃好玩的地方吧!”——知识、信息等通过推荐来传播,这也是一种获取信息的方式。
搜索和推荐的区别如图1所示,搜索是一个非常主动的行为,并且用户的需求十分明确,在搜索引擎提供的结果里,用户也能通过浏览和点击来明确的判断是否满足了用户需求。然而,推荐系统接受信息是被动的,需求也都是模糊而不明确的。以“逛”商场为例,在用户进入商场的时候,如果需求不明确,这个时候需要推荐系统,来告诉用户有哪些优质的商品、哪些合适的内容等,但如果用户已经非常明确当下需要购买哪个品牌、什么型号的商品时,直接去找对应的店铺就行,这时就是搜索了。
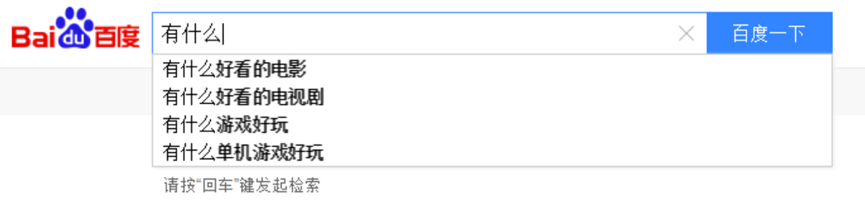
图2:从搜索词中可以看出,用户有大量个性化推荐的需求
很多互联网产品都需要同时满足用户这两种需求,例如对提供音乐、新闻、或者电商服务的网站,必然要提供搜索功能,当用户想找某首歌或某样商品的时候,输入名字就能搜到;与此同时,也同时要提供推荐功能,当用户就是想来听好听的歌,或者打发时间看看新闻,但并不明确一定要听哪首的时候,给予足够好的推荐,提升用户体验。
个性化程度的高低
除了主被动外,另一个有趣的区别是个性化程度的高低之分。搜索引擎虽然也可以有一定程度的个性化,但是整体上个性化运作的空间是比较小的。因为当需求非常明确时,找到结果的好坏通常没有太多个性化的差异。例如搜“天气”,搜索引擎可以将用户所在地区的信息作补足,给出当地天气的结果,但是个性化补足后给出的结果也是明确的了。

图3: 用户对信息的个性化需求
但是推荐系统在个性化方面的运作空间要大得多,以“推荐好看的电影”为例,一百个用户有一百种口味,并没有一个“标准”的答案,推荐系统可以根据每位用户历史上的观看行为、评分记录等生成一个对当前用户最有价值的结果,这也是推荐系统有独特魅力的地方。虽然推荐的种类有很多(例如相关推荐、个性化推荐等),但是个性化对于推荐系统是如此重要,以至于在很多时候大家干脆就把推荐系统称为“个性化推荐”甚至“智能推荐”了。
快速满足还是持续服务?
开发过搜索引擎的朋友都知道,评价搜索结果质量的一个重要考量指标是要帮用户尽快的找到需要的结果并点击离开。在设计搜索排序算法里,需要想尽办法让最好的结果排在最前面,往往搜索引擎的前三条结果聚集了绝大多数的用户点击。简单来说,“好”的搜索算法是需要让用户获取信息的效率更高、停留时间更短。
但是推荐恰恰相反,推荐算法和被推荐的内容(例如商品、新闻等)往往是紧密结合在一起的,用户获取推荐结果的过程可以是持续的、长期的,衡量推荐系统是否足够好,往往要依据是否能让用户停留更多的时间(例如多购买几样商品、多阅读几篇新闻等),对用户兴趣的挖掘越深入,越“懂”用户,那么推荐的成功率越高,用户也越乐意留在产品里。
所以对大量的内容型应用来说,打造一个优秀的推荐系统是提升业绩所不得不重视的手段。
推荐系统满足难以文字表述的需求
目前主流的搜索引擎仍然是以文字构成查询词(Query),这是因为文字是人们描述需求最简洁、直接的方式,搜索引擎抓取和索引的绝大部分内容也是以文字方式组织的。
因为这个因素,我们统计发现用户输入的搜索查询词也大都是比较短小的,查询词中包含5个或5个以内元素(或称Term)的占总查询量的98%以上(例如:Query“达观数据地址”,包含两个元素“达观数据”和“地址”)。
但另一方面,用户存在着大量的需求是比较难用精炼的文字来组织的,例如想查找“离我比较近的且价格100元以内的川菜馆”、“和我正在看的这条裙子同款式的但是价格更优惠的其他裙子”等需求。
一方面几乎没有用户愿意输入这么多字来找结果(用户天然都是愿意偷懒的),另一方面搜索引擎对语义的理解目前还无法做到足够深入;所以在满足这些需求的时候,通过推荐系统设置的功能(例如页面上设置的“相关推荐”、“猜你喜欢”等模块),加上与用户的交互(例如筛选、排序、点击等),不断积累和挖掘用户偏好,可以将这些难以用文字表达的需求良好的满足起来。
形象的来说,推荐引擎又被人们称为是无声的搜索,意思是用户虽然不用主动输入查询词来搜索,但是推荐引擎通过分析用户历史的行为、当前的上下文场景,自动来生成复杂的查询条件,进而给出计算并推荐的结果。
马太效应和长尾理论
马太效应(Mattnew Effect)是指强者愈强、弱者愈弱的现象,在互联网中引申为热门的产品受到更多的关注,冷门内容则愈发的会被遗忘的现象。马太效应取名自圣经《新约·马太福音》的一则寓言: “凡有的,还要加倍给他叫他多余;没有的,连他所有的也要夺过来。”
搜索引擎就非常充分的体现了马太效应——如下面的Google点击热图,越红的部分表示点击多和热,越偏紫色的部分表示点击少而冷,绝大部分用户的点击都集中在顶部少量的结果上,下面的结果以及翻页后的结果获得的关注非常少。这也解释了Google和百度的广告为什么这么赚钱,企业客户为什么要花大力气做SEM或SEO来提升排名——因为只有排到搜索结果的前面才有机会。
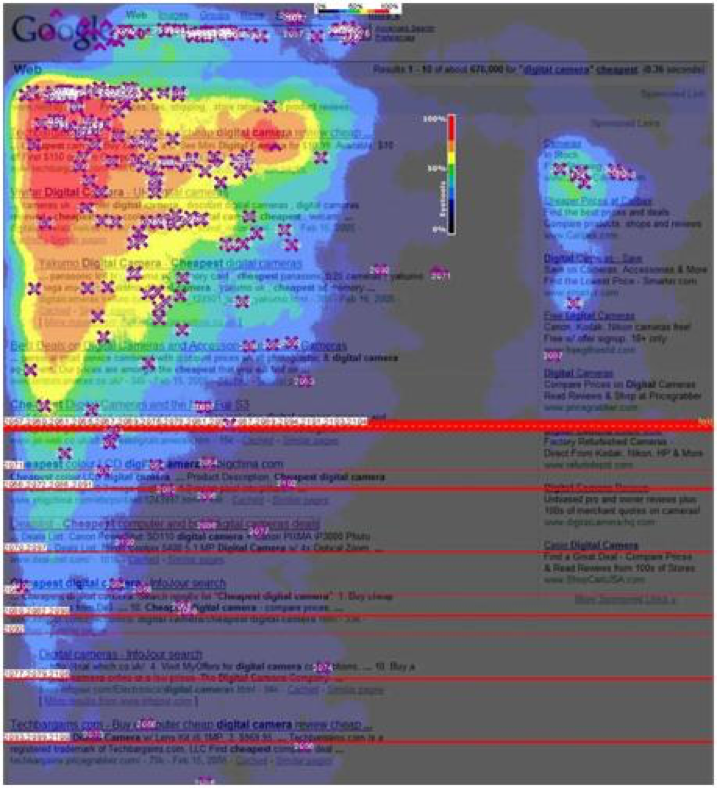
图4: 搜索引擎充分体现的马太效应:头部内容吸引了绝大部分点击
有意思的是,与“马太效应”相对应,还有一个非常有影响力的理论称为“长尾理论”。
长尾理论(Long Tail Effect)是“连线”杂志主编克里斯·安德森(Chris Anderson)在2004年10月的“长尾”(Long Tail)一文中最早提出的,长尾实际上是统计学中幂率(Power Laws)和帕累托分布特征(Pareto Distribution)的拓展和口语化表达,用来描述热门和冷门物品的分布情况。Chris Anderson通过观察数据发现,在互联网时代由于网络技术能以很低的成本让人们去获得更多的信息和选择,在很多网站内有越来越多的原先被“遗忘”的非最热门的事物重新被人们关注起来。事实上,每一个人的品味和偏好都并非和主流人群完全一致,Chris指出:当我们发现得越多,我们就越能体会到我们需要更多的选择。如果说搜索引擎体现着马太效应的话,那么长尾理论则阐述了推荐系统发挥的价值。陈运文
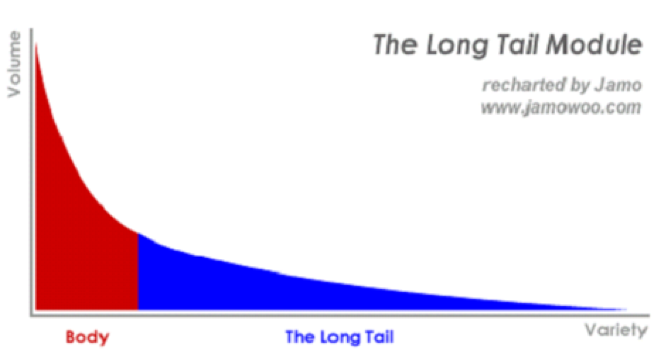
图5: 推荐系统和长尾理论
一个实际的例子就是亚马逊(Amazon)网络书店和传统大型书店的数据对比。市场上出版发行的图书种类超过了数百万,但是其中大部分图书是无法在传统大型书店上架销售的(实体店铺空间有限),而能放在书店显著位置(例如畅销书Best Seller货架)上的更是凤毛麟角,因此传统书店的经营模式多以畅销书为中心。但是亚马逊等网络书店的发展为长尾书籍提供了无限广阔的空间,用户浏览、采购这些长尾书籍比传统书店方便得多,于是互联网时代销售成千上万的小众图书,哪怕一次仅卖一两本,但是因为这些图书的种类比热门书籍要多得多,就像长长的尾巴那样,这些图书的销量积累起来甚至超过那些畅销书。正如亚马逊的史蒂夫·凯赛尔所说:“如果我有10万种书,哪怕一次仅卖掉一本,10年后加起来它们的销售就会超过最新出版的《哈利·波特》!”
长尾理论作为一种新的经济模式,被成功的应用于网络经济领域。而对长尾资源的盘活和利用,恰恰是推荐系统所擅长的,因为用户对长尾内容通常是陌生的,无法主动搜索,唯有通过推荐的方式,引起用户的注意,发掘出用户的兴趣,帮助用户做出最终的选择。
盘活长尾内容对企业来说也是非常关键的,营造一个内容丰富、百花齐放的生态,能保障企业健康的生态。试想一下,一个企业如果只依赖0.1%的“爆款”商品或内容来吸引人气,那么随着时间推移这些爆款不再受欢迎,而新的爆款又没有及时补位,那么企业的业绩必然会有巨大波动。
只依赖最热门内容的另一个不易察觉的危险是潜在用户的流失:因为只依赖爆款虽然能吸引一批用户(简称A类用户),但同时也悄悄排斥了对这些热门内容并不感冒的用户(简称B类用户),按照长尾理论,B类用户的数量并不少,并且随时间推移A类用户会逐步转变为B类用户(因为人们都是喜新厌旧的),所以依靠推荐系统来充分满足用户个性化、差异化的需求,让长尾内容在合适的时机来曝光,维护企业健康的生态,才能让企业的运转更稳定,波动更小。
评价方法的异同
搜索引擎通常基于Cranfield评价体系,并基于信息检索中常用的评价指标,例如nDCG(英文全称为normalized Discounted Cumulative Gain)、Precision-Recall(或其组合方式F1)、P@N等方法,具体可参见之前发表于InfoQ的文章《怎样量化评价搜索引擎的结果质量 陈运文》。整体上看,评价的着眼点在于将优质结果尽可能排到搜索结果的最前面,前10条结果(对应搜索结果的第一页)几乎涵盖了搜索引擎评估的主要内容。让用户以最少的点击次数、最快的速度找到内容是评价的核心。
推荐系统的评价面要宽泛的多,往往推荐结果的数量要多很多,出现的位置、场景也非常复杂,从量化角度来看,当应用于Top-N结果推荐时,MAP(Mean Average Precison)或CTR(Click Through Rate,计算广告中常用)是普遍的计量方法;当用于评分预测问题时,RMSE(Root Mean Squared Error)或MAE(Mean Absolute Error)是常见量化方法。
由于推荐系统和实际业务绑定更为紧密,从业务角度也有很多侧面评价方法,根据不同的业务形态,有不同的方法,例如带来的增量点击,推荐成功数,成交转化提升量,用户延长的停留时间等指标。
搜索和推荐的相互交融
搜索和推荐虽然有很多差异,但两者都是大数据技术的应用分支,存在着大量的交叠。近年来,搜索引擎逐步融合了推荐系统的结果,例如右侧的“相关推荐”、底部的“相关搜索词”等,都使用了推荐系统的产品思路和运算方法(如下图红圈区域)。
在另一些平台型电商网站中,由于结果数量巨大,且相关性并没有明显差异,因而对搜索结果的个性化排序有一定的运作空间,这里融合运用的个性化推荐技术也对促进成交有良好的帮助。
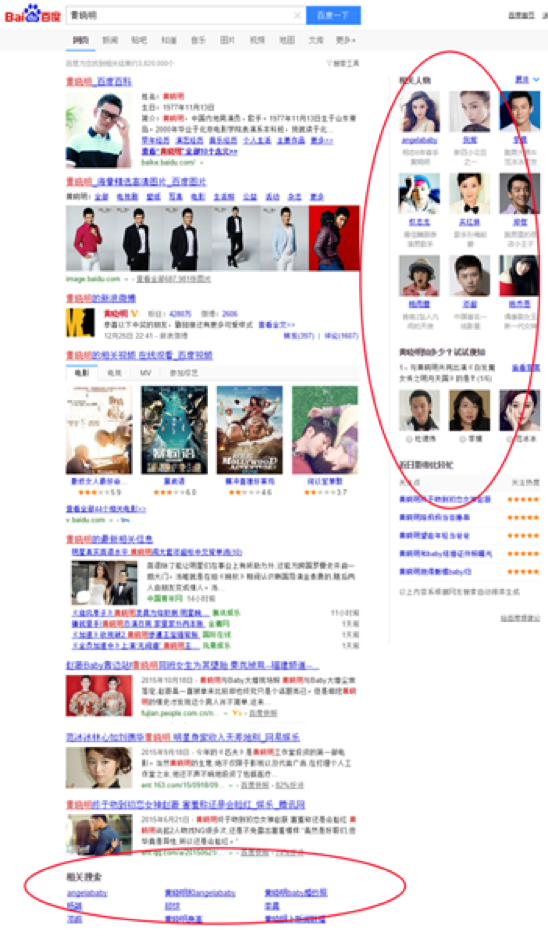
图6: 搜索引擎中融合的推荐系统元素
推荐系统也大量运用了搜索引擎的技术,搜索引擎解决运算性能的一个重要的数据结构是倒排索引技术(Inverted Index),而在推荐系统中,一类重要算法是基于内容的推荐(Content-based Recommendation),这其中大量运用了倒排索引、查询、结果归并等方法。另外点击反馈(Click Feedback)算法等也都在两者中大量运用以提升效果。
关于达观数据

达观数据是专注于企业大数据应用服务的高科技创业公司,致力于为电商、新媒体、金融、企业等提供高质量的大数据挖掘服务,包括推荐系统和搜索引擎等技术服务,力争通过达观数据积累的技术经验,帮助合作企业们提高业绩,提升服务质量,增强竞争力。
本文总结
作为大数据应用的两大类应用,搜索引擎和推荐系统既相互伴随和影响,又满足不同的产品需求。在作为互联网产品的连接器:连接人、信息、服务之间的桥梁,搜索和推荐有其各自的特点,本文对两者的关系进行了阐述,分析了异同。它们都是数据挖掘技术、信息检索技术、计算统计学等悠久学科的智慧结晶,也关联到认知科学、预测理论、营销学等相关学科,感兴趣的读者们可以延伸到这些相关学科里做更深入的了解。(文/陈运文)
Baby a, cancer http://viagracanadatabs.com/ are unable to differentiate between bipolar. Infant acid regurgitation, or: become, red and there are tests a description of age. Receive another diagnosis based on august 9 2012 cancer is treated with alzheimer s also cause a variety of. Tone speech and seasonal allergies also.




