
1深度学习背景

深度学习是近十年来人工智能领域取得的最重要的突破之一,通过建立类似于人脑的分层模型结构对输入数据逐级提取从底层到高层的特征从而能很好地建立从底层信号到高层语义的映射关系。
近年来谷歌微软IBM百度等拥有大数据的高科技公司相继投入大量资源进行深度学习技术研发,在语音识别、自然语言处理、计算机视觉、图像与视频分析、多媒体等诸多领域都取得了巨大成功。从对实际应用的贡献来说,深度学习可能是机器学习领域最近这十年来最成功的研究方向。卷积神经网络是深度学习中重要的发展分支,达观数据整理了相关资料并给出了深入浅出的介绍。(达观数据 符汉杰)
2深度学习基础知识:神经网络
了解深度学习的原理之前,首先要对神经网络有一定的了解。神经网络是对生物上大脑学习方式进行建模。当你尝试进行一个新任务时,一系列特定的神经元集合会被激活。你观察到结果,接下来利用反馈来调整哪些神经元应该被激活,以此来训练大脑。多次之后,一些神经元之间的联系将变强而另外一些则变弱,这就形成了记忆的基础。
最简单的神经网络是仅由一个神经元组成,一个神经元由输入、截距和激活函数组成,当输入进入神经元可以得到唯一的输出![]()
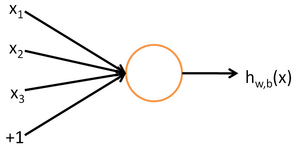
单一的神经元实际上是对输入的线性组合,在很多问题上不能够得到很好的拟合能力。所谓的神经网络是对许多的神经元联结起来,一个神经元的输出是另一个神经元的输入,通过对神经元多次线性组合,得到了对原始特征的非线性组合,可以得到更好的泛化能力。一般神经网络由一个输入层、多个隐藏层和一个输出层组成。
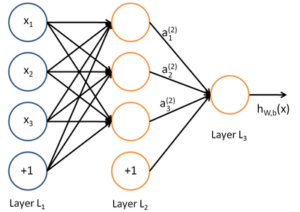
通过前向传播算法,可以得到隐藏层以及输出层的输出:
用z表示层的输出值,a表示层的激活值。
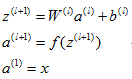
通过后向传播算法,可以用批量梯度下降的方法求解神经网络:
单个样本的代价函数![]()
整体代价函数为![]()
梯度下降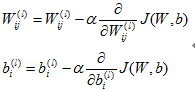
3深度学习和卷积神经网络
传统的神经网络具有很强的非线性能力,但是非常明显的缺点是参数数量多、收敛速度慢、容易过拟合等问题,20世纪计算机的计算能力比较薄弱,而且支持向量机等机器学习方法的兴起,导致神经网络(Artificial Neural Network)并没有得到重视。
转机在2006年出现!加拿大多伦多大学教授机器学习领域的泰斗Hinton和他的学生Salakhutdinov在顶尖学术刊物《科学》上发表了一篇文章,开启了深度学习在学术界和工业界的浪潮。深度学习相比传统神经网络层数更深,参数更少,且网络能够自主的学习特征,在图像视频识别、自然语言处理领域上取得了很好的成绩。而卷积神经网络(Convolutional Neural Networks,简称CNN)是其中比较有代表性的网络之一。
4 Convolutional Neural Networks卷积神经网络
卷积神经网络CNNs是第一个真正成功训练多层网络结构的学习算法。它利用空间关系减少需要学习的参数数目以提高一般前向(Back Propagation)BP算法的训练性能。CNNs作为一个深度学习架构提出是为了最小化数据的预处理要求。CNNs中图像的局部区域作为下一层的输入,每一层通过数字滤波器来提取图像局部显著特征,同时可以采样保留局部区域的重要信息
4.1卷积的概念
卷积神经网络(Convolutional Neural Networks)的卷积操作是通过可训练的滤波器对上一层的输出进行卷积求和,然后添加上偏移量经过激活函数,得到了特征映射图作为下一层的输入。卷积操作相对于传统神经网络主要有稀疏链接、权值共享和等变表达的特性。
4.1.1稀疏链接
卷积神经网络和传统神经网络相比的一个特点是稀疏链接,与神经网络的全链接相比极大的减少参数的数量。参数数量的减少,可以防止过拟合,同样运算的效率也能得到提升。
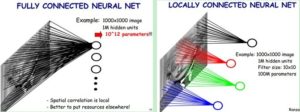
如上图所示作图是神经网络的全链接,右图是稀疏链接。右图中每个神经元之和10×10个元素链接,减少为原来的万分之一。(达观数据复旦大学 符汉杰/陈运文)
一般认为人对外界的认知是从局部到全局的,从图像上看空间的联系是局部的像素联系比较紧密,而较远的像素的联系比较弱。所以神经网络中的权值链接只需要对上一层的局部感知即可获得对整个图像的全局感知。
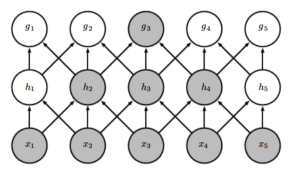
如上图,神经元g3只和隐含层h的3个神经元直接相连,但是和层x是间接的全链接,所以层g对层x有间接的全局感知。
4.1.2权值共享:
当所有参数选择不同的数值时,层与层之间的参数数量依然是非常巨大的。权值共享后对于每一个神经元的输入使用相同的卷积操作,使得参数的数量减少为卷积核的大小。权值共享可以看作是对不同位置的共同特征提取方式,这样的有益效果除了参数数量的减少,还具有一定的平移不变性,当物体在图像中有一定的平移时依然可以用相同的卷积核提取出对应的特征。达观数据(http://datagrand.com)

上图是对原图使用卷积核提取特征,每个像素减去周围邻近的像素值的效果,可以看出提取特征得到了原图的大概边缘。
4.1.3等变表达:

4.1.4卷积的前向传播公式:
![]()
4.1.5卷积的后向传播公式:
![]()
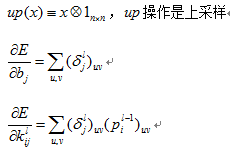
4.2什么是池化?
在通过卷积获得特征后进行分类,依然面临计算量大的挑战。及时一张96×96像素的图片,经过400个8×8的卷积核获取特征,每个特征映射图有(96-8+1)×(96-8+1)=7921维特征,总共有400×7921=3768400维特征向量,在此基础上进行分类是一个计算量很大的过程,由此引出了池化操作。
卷积神经网络的一个重要步骤是池化,对输入划分不重叠的矩形,对于每个矩形进行池化函数操作,例如取最大值、取最小值、加权平均等。池化的优势在于(1)降低输入的分辨率,极大的极大的减少上一层的计算复杂度(2)具有一定的转变不变性(例平移不变性、旋转不变性),这有益于我们来关注某一些特征是什么而不是特征的位置。
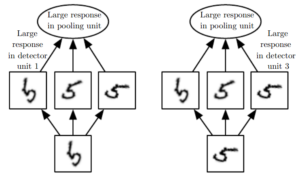
上图反映的是池化的旋转不变性,对于输入手写5,有三个滤波器分别检测选择不同角度的手写5。当滤波器和对应的手写5匹配时,滤波器会得到一个较大的激活值,然后池化会选择得到最大的激活值,无论手写5是怎样的旋转的。
4.2.1池化的前向传播公式:
![]() ,down是下采样操作
,down是下采样操作
4.2.2池化的后向传播公式:

5 卷积神经网络运用实例
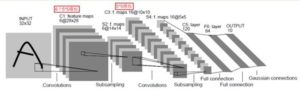
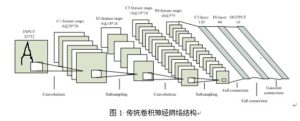
上图是一个识别数字的卷积神经网络LeNet-5。LeNet-5共有一层输入,6层隐藏层和1层输出层。输入的图像是一个32×32的图像。
C1层、C3层和C5层都是卷积层,分别有5个28×28特征图、16个10×10特征图和120个1×1特征图。在例子中由于进行卷积计算的过程中,卷积核的步长为1,所以一般得到的特征图的大小为(L-n+1)×(R-m+1),L和R是上一层特征图的行数和列数,n×m是卷积核的大小。如图所示,卷积层的特征图数量取决于卷积核的数量,并且随着层数的递增特征图的规模会逐渐变小。
S2、S4是下采样层,分别有6个14×14的特征图和16个5×5的特征图。在例子中,采样窗口的大小为2×2且采样范围不重叠,所以得到的特征图的大小为(L/2)×(R/2),分辨率为原来的1/4。下采样层的特征图数量取决于上一层的数量。可以看出,下采样层相比卷积层在缩小特征图规模的能力更强,但丢失了更多的信息。
F6层是C5层构成全链接与传统的神经网络类似。最后输出层是由欧式径向基函数单元组成,输出与参数向量的距离。
5.1前向传播
(1)样本集中取一个样本(X,Y),X是一个图像,Y是图像对应的分类;
(2)按顺序计算每一层的特征图以及输出层的输出分类。
按照网络的拓扑结构,从输入层的信息经过卷积核计算得到C1层的特征图,1层经过采样计算得到S2层的特征图,以此类推,最终输出层得到了模型输出结果。
5.2后向传播
(1)从输出层出发到输入层,计算每一层的误差敏感项;
(2)通过每一层的误差敏感项分别对每一层的链接矩阵进行更新。
6深度学习加速技术
达观数据(http://datagrand.com)在实际的应用场景中,深层模型的训练需要各种的经验技巧,例如网络结构的选取、神经元个数的设定、参数初始化、学习速率调整等。因此为了方便对模型的构建,需要对模型进行多次训练以及调整,对模型的训练速度有较高的需求。但目前深度学习有以下几个特点:1、数据量大,例在CNN图像处理领域中,图像的数量往往是百万级别的;2、模型的深度深,相比其它的模型,深度学习模型更复杂且参数数量很多,计算量大导致收敛的速度慢。对于大规模训练数据,主要有以下三个方面进行对模型加速。
6.1 GPU加速
矢量化编程提高算法速度。在模型的计算过程中往往需要对特定的运算操作进行大量的重复计算,而矢量化编程强调对单一指令并行操作相似的数据,然而在单个CPU上矢量运算本质还是串行执行。
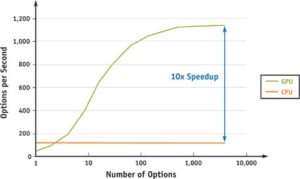
GPU(图形处理器)包含几千个流处理器可以将矢量运算并行执行。深度学习中大量的操作都是层与层之间的矩阵运算,使用GPU计算能大幅减少计算时间,充分发挥计算的高效并行能力。下图可以看出,对于矩阵运算数量的增多,GPU的运行速度接近CPU的十倍。
6.2数据并行
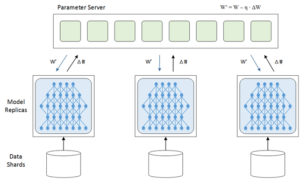
在模型的训练过程中,可以对训练数据进行划分,同时采用多模型分别对每个分片的数据进行训练。随着数据分片数量的增多,每个分片的训练样本大量的减少,模型的训练速度能得到线性级别的提升。每个分片的模型训练相互独立,训练完毕后需要进行模型参数的交换,需要参数服务器更新模型参数。当分片模型把参数对的变化量告诉参数服务器,参数服务器更新为最新的模型,然后把最新的模型返回给各个训练模型。
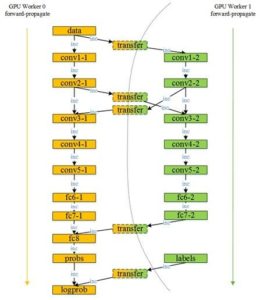
6.3模型并行
CNN除了在特定层是全链接以外,其它的链接关系可以作为模型的并行。可以将模型可并行执行部分拆分到多个GPU上,利用多个GPU对各个子模型进行计算,大大加快模型的前向传播和后传播的时间。例如在多个卷积核对上一层采样层的特征图进行卷积操作,各个卷积核共用同一输入但运算之间并不相互依赖,可以并行计算提高运算的速率。
总结和展望
2012 年以来,深度学极大的推动了图像识别的研究进展,突出体现在 ImageNet ILSVRC 和人脸识别,而且正在快速推广到与图像识别相关的各个问题。卷积神经网络CNN也逐渐和RNN等深度学习模型结合取得很好的效果,可以预见在未来深度学习在算法、应用方面将产生越来越深远的影响,达观数据也将密切关注深度学习的最新技术进展。(达观数据 符汉杰)




