

在这个人工智能备受推崇的时代,即便如华为这样的大型科技企业也无法忽视人工智能的正向作用,因为时代在召唤,科技的助推只会帮助企业更好地释放价值。
企业堆积海量信息,合理利用才是解决之道
科技企业充斥着大量有复用价值的数据、资料和内容性信息,以各种电子文档的形式散落于计算机各个硬盘,并且信息不断堆叠累积。比如企业中一个项目的开展,必然会附带产生一系列文档信息,或是技术性质,或是产品说明;企业客户的产品问题咨询和企业的疑问解答,都是企业的积累起来的信息和知识。

束之高阁的文档资料和信息是毫无意义的,企业如何将有价值的文档资料进行结构化处理加以利用才是其意义所在,否则既耗费企业的资源海量,文档信息又无所适从。例如大型科技企业必定会出现很多相同类型或同种性质的项目,高效利用前期项目中的有用信息或许可以大幅提高企业的工作效率;此外企业通过对所积累的客户问题和回答进行归档整理,以便遇到同类问题可以从知识库中快速提取,免去高成本人工回复。
但是,企业面临的不只是提取重要信息进行复用或使用,更重要的是提取出来的信息所带来的效益是否远远高于提取信息所付出的成本和代价。如果企业耗费较大人力或时间去“翻看”之前的项目资料,机会成本过高,甚至得不偿失。
面对海量信息,企业处理步履维艰
目前很多大型科技企业的电子文档资料仍然主要依靠人工手段进行核心内容的阅读和提取,进而焕发文档内在可用信息的“第二春”。但人力的工作时段有限,不具备实时性,更不具备连续工作性,且工作效率呈边际递减状态,而人力成本却不低。
另外面对企业每天产生的信息数据,实现高效分类也能提高企业工作效率的一大利器。而多数企业除却人工分类就是基于简单文本特征的建模进行文本分类,人工分类效率低,而简单建模分类不仅成本高,还面临着因为已有类别的扩充或变化需要大量投入进行调整的问题。有的企业借助普通第三方服务,比起人工和简单的二次开发分类效果自然好很多,但多数第三方服务无法给予定制化开发,且不能自动升级。

因此,企业力求文档高效分类,只依靠人工和普通的技术难以实现高度准确的分类效果。
达观智能文本语义理解,快速分析海量文档
达观文本语义理解技术,恰如其分地解决企业在处理海量文档资料中的需求和问题实现文档资料结构化。具体可以实现的功能囊括了文本分类、实体识别、摘要提取、情感分析等。下图是对一句话进行分析的简化处理过程说明。
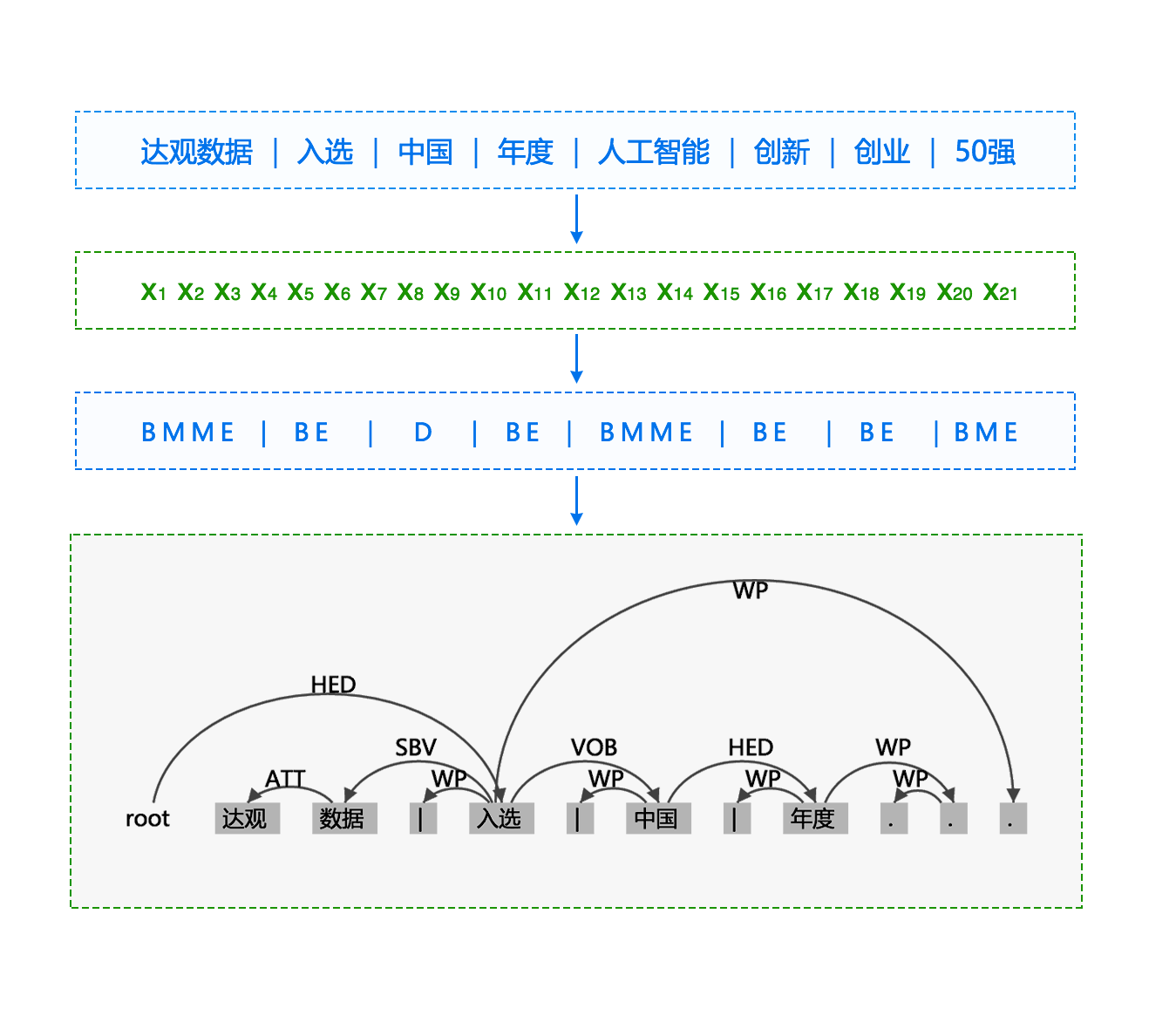
针对科技企业的海量文档内容,达观机器学习技术自动从每篇文档中提取摘要,从而反映文档的中心内容,类似于中学里语文考试从一篇文章中概括出主体思想和中心大意。与此同时,达观利用企业提供的样本数据,通过机器学习结合NLP技术构建企业独有的分类模型。
针对上述企业出现的信息分类效率低下和准确率不高的困境,达观采用多层分类器解决方案,通俗地说就是融合之道,利用不同分类器的优势,取长补短,最后综合多个分类器的结果。千万不要以为分类器组合就是简单累加即可使用,而是通过机器来训练组合参数,实现最优组合。
-4.png)
如果面对长篇累牍的科技企业文档资料,晦涩枯燥,实行人工分类,抛开对人身体的折磨,心灵会不会有创伤都未可知,达观人工智能技术虽是不断拟人化,却不会似人般有累感。可稳定连续工作,没有长期工资的负担,高效实时,更重要的是它也在持续学习,不断提高分类准确率。
科技企业与自然语言处理技术的双赢
企业与员工可能在某种程度上存在一种微妙的零和博弈,员工的付出与企业的“攫取”,至少利用身体的机能损耗为公司带来些许价值,用“此消彼长”来说也不为过。但企业与自然语言处理技术之间存在的只会是非零和博弈,且是正和博弈,大型科技企业的这种现象更为明显。
达观自然语言处理技术助力企业提高文档信息的核心内容提取效率,减少人工成本,而技术则能从这些庞大的企业里获取海量的数据进行机器学习,通过不断自学提高技术实力。于企业和自然语言处理技术而言,这是一个双赢的局面。




