
一、深度学习概述
深度学习是从机器学习基础上发展起来的,机器学习分为监督学习、非监督学习以及强化学习三种类型。
深度学习是在机器学习的基础上把特征抽取工作放到里面一起来完成的,直接实现了端到端的学习。通常我们遇到的深度网络包括:堆叠自编码器、深度信念网络、卷积神经网络和循环神经网络。
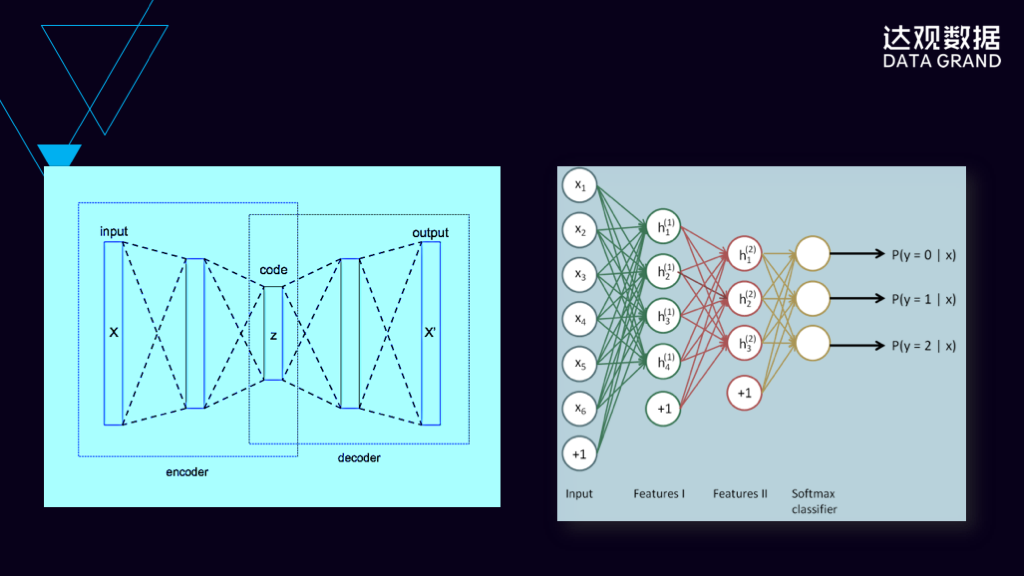
左边这张图是自编码器的一个网络结构示意图,自编码器的特点是输入和输出是完全一样的,它通过将输入复制到输出,去学习它在隐层里面的表示。右边是堆叠自编码器,它可以把自编码器的隐层不断堆叠起来,形成多层的深度网络。与堆叠自编码器一样,深度信念网络是在限制玻尔兹曼机基础上叠出来的一个网络,受限玻尔兹曼机是神经网络里面最基础的网络结构之一,通过将多个受限玻尔兹曼机堆叠起来形成的深度网络,是深度学习里面最基本的网络结构之一。
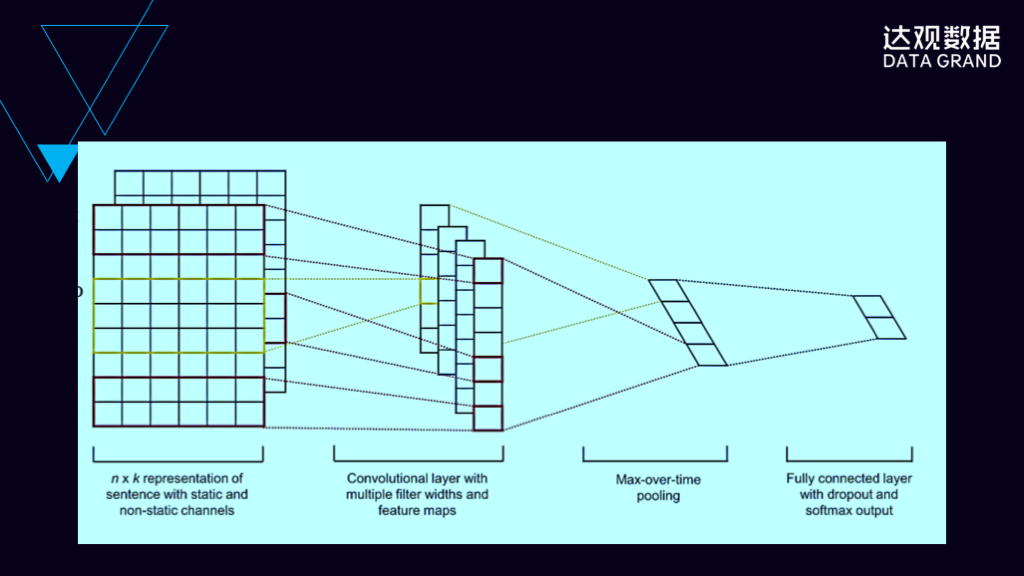
深度学习被最广泛使用的是从卷积神经网络开始的,卷积神经网络的示意图如这张图片所示,它通过卷积和对输入的局部特征进行学习,来达到最终的目标。卷积神经网络被广泛应用于文本处理和图像识别当中。
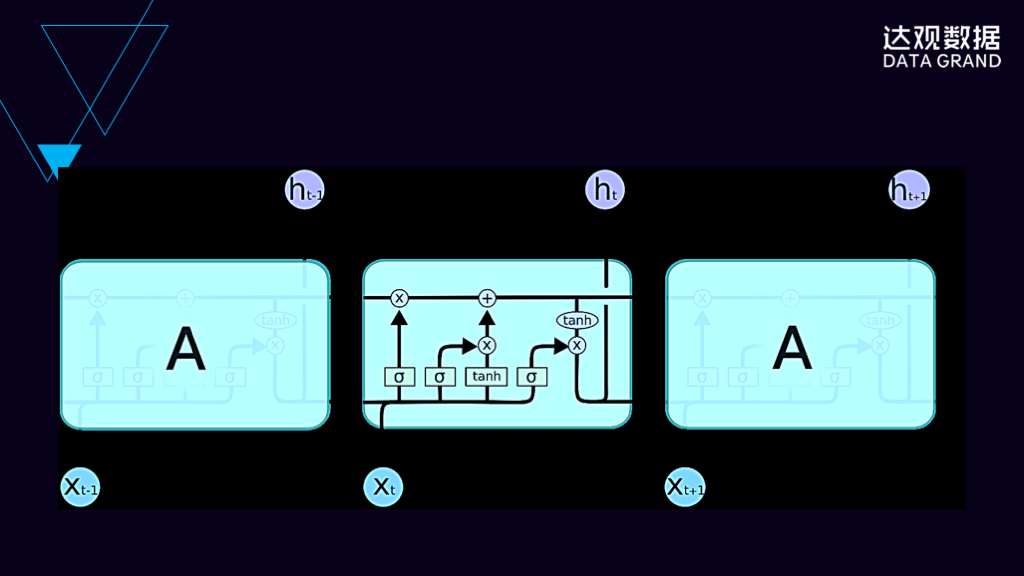
深度学习另外一个被广泛使用的网络是循环神经网络,循环神经网络有非常多的变种,这张图是它其中的一个,叫LSTM,经常被用于语音识别和文本处理当中。

从上面网络可以看出来,深度学习是在神经网络的基础上发展起来的,神经网络早期的效果并不是特别好,但是从两千零几年开始,因为海量数据的积累、逐层训练技术的出现以及以GPU为代表的计算性能的极大提升,使得深度学习能效果越来越好,被广泛应用于语音识别、计算机视觉、自然语言处理中。自然语言处理就会用到非常多深度学习的算法。
二、自然语言理解概述
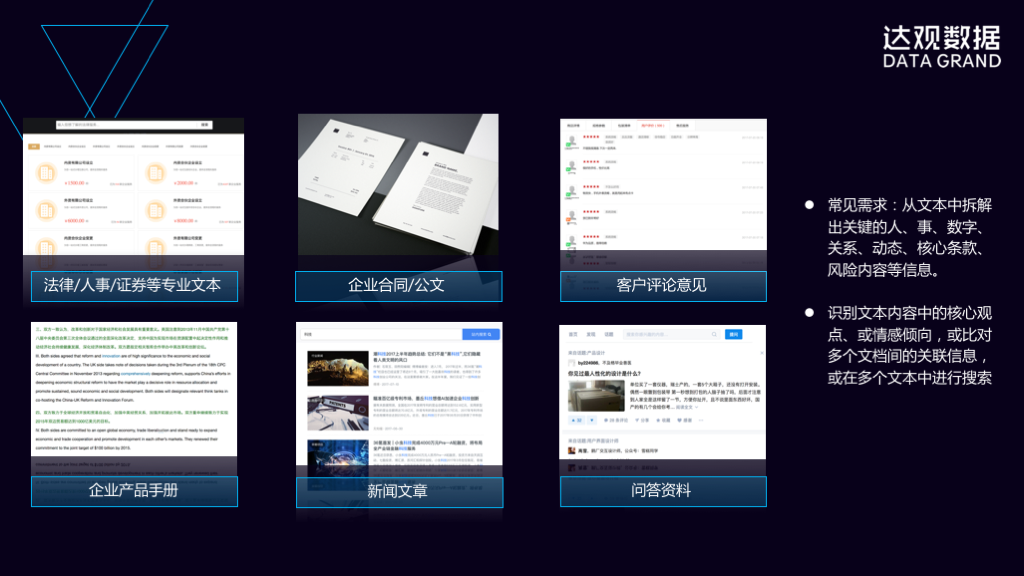
自然语言理解所处理的对象是文本,文本是广泛存在于我们的日常生活和工作当中的,像达观数据所擅长处理的是正式文本或者长文本,长文本像法律文书、人事档案、证券专业文书、企业手册、新闻文章、问答资料、客户评论意见等都是我们常见的文本,它几乎存在于所有的行业中,金融、法律、媒体、互联网、政府、公共机构、大型企业,无所不在,如果能够使用自然语言理解和机器学习的方法,使得大量需要人工处理的海量文档自动化,将会非常大地提高企业和政府部门的工作效率。
然而,让计算机来理解文本是非常难的一件事情,首先,计算机缺乏常识以及专业的背景知识,而人类通常拥有非常丰富的专业知识和背景。比如对“future”的理解,普通人认为是“未来”,但对于金融相关的专业可能就会认为是“期货”,而“期货”对金融专业人士来说是一个语境,这是计算机所不存在的一个场景。

除此之外,人类说话本身非常的抽象和模糊,通常拥有非常多的歧义或者语境信息在里面。我们通常在见到朋友时会说“吃饭了吗?”
“吃饭了吗”对计算机来说就是“吃饭了吗”四个字,而对人类来说它通常拥有丰富的隐含意义在里面。
从分词的角度,我们可以看词本身的粒度问题,“中华人民共和国”和“中国”本身意义是一样的。还有指代归属问题,当人与人之间交流时候,你说的“你、我、他”能够自然而然的被替换成相应的目标,而计算机来解决指代归属问题也是非常难的一个事情。除此之外,还有同义词、近义词、局部转义、一词多义等问题。
比如一词多义的问题,大家在网络上看到过一个段子,“方便方便,意思意思”然后去理解“方便方便”和“意思意思”不同的意思。计算机同样存在这个问题,它如何理解“方便方便”和“意思意思”的不同意思和不同的方便程度。
再从词语构造成句子的过程中也会遇到非常多的问题,因为对人类来说,句子之间的部分结构发生颠倒,人类依然能够正常的理解,但是对计算机来说,它对于像“你上班了吗?”“班上你了吗?”就有难度。
再往上,语义层面的歧义就更多了,“咬死猎人的狗”如果在没有上下文语境的情况下,人类也非常的难以理解,到底是狗咬死了猎人,还是某些动物把猎人的狗给咬死了,这就是所谓的语境。
除了语境之外,还有比较多的领域知识、专家知识,比如最近爆雷非常多的P2P,有一个特点是利息比较高。当利息高过了一定程度,存在问题的概率比较高了。这类专家的知识对计算机来说也是一个问题。
“企业清算时按投资年复率20%给予补偿”,这句话如果存在合同当中,往往是需要注意的点。因为通常不超过12%,20%的利率过高。这个『过高』是写错了、还是因为其他特殊原因,遇到这种问题时就需要通过双重确认,来确保文本的正确。

为了解决这些问题,我们使用各种机器学习和深度学习的方法来建立模型,通过海量的文本进行训练这个模型来预测未来。这个方式有点类似于人脑,人是要通过学习,学习很多专业知识,当学完知识之后,在未来遇到这些问题时,就会通过类似于机器学习的模型来实现预测和判断。
在建立这些模型的过程中,我们通常会分为字词级分析、段落级分析、篇章级分析。
字词级分析是我们通常所遇到的像分词、命名实体识别、同义词分析等。
段落级分析是从句子到段落层面来对文本进行建模,它一般包括依存文法分析、文本纠错等。从段落往上是篇章级分析,篇章级分析更多是语义层面的理解,它通常包括像文本相似度、主题模型、文章的聚类分类和标签提取。
三、文本语义分析及其应用实践
文本语义分析首先是表示学习。表示学习通常传统上对文本的表示是通过One-hot编码来实现的,在深度学习出来以后,往往使用稠密的向量编码来对文本表示。
词向量的稠密表示具有非常大的优势,一方面是它的维度降低得非常多,一般情况下200-300维就足够以表达中文的词汇,而one-hot编码往往需要50万-100万维来表示。除此之外,词向量还能表达词的语义层面的相似性。
对词向量经典的训练方法是谷歌发表的原始的“Word2Vec”这篇论文里提到的两种方法,CBOW和skip-gram。CBOW是用词的上下文信息来表示这个词本身,而skip-gram则是用词的本身来表达词的上下文信息。在“Word2Vec”基础之上还发展出包含了全局信息的GloVe方法。
除了词向量之外,深度学习的各种网络结构也被用来进行文本分析。比如对句子进行分类,可以使用卷积神经网络来实现。
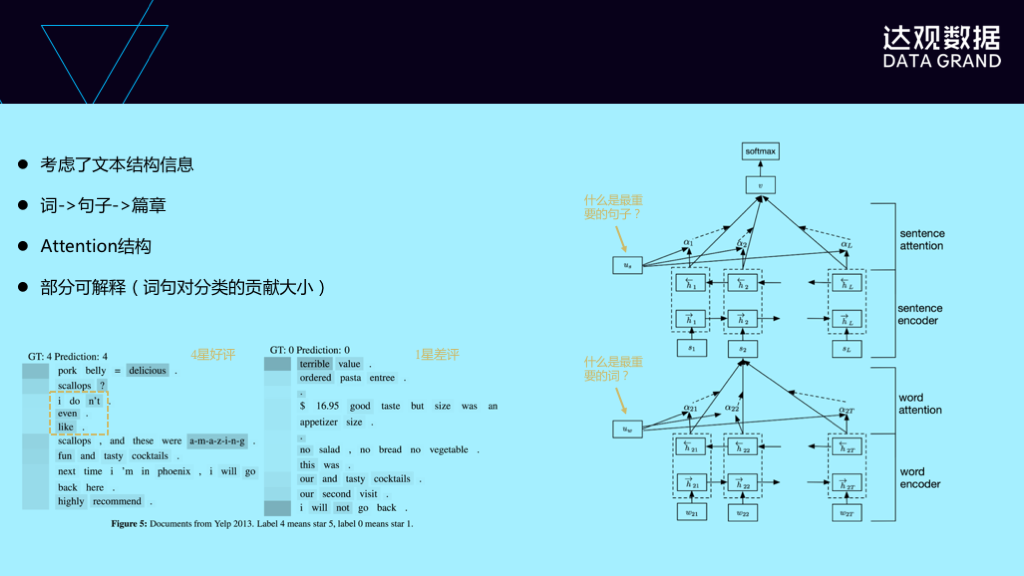
层次注意力模型是最新的一个网络,它最早被使用来对评论进行打分。层次注意力模型有一个非常大的优点,就是它考虑了文本或者是篇章的结构,它是从词开始,到句子的一个注意力模型,再到整个篇章是另一个注意力模型。它另外的一个优点是可以把整个网络结构的参数可视化出来,来解释词、句子对目标的贡献的大小。
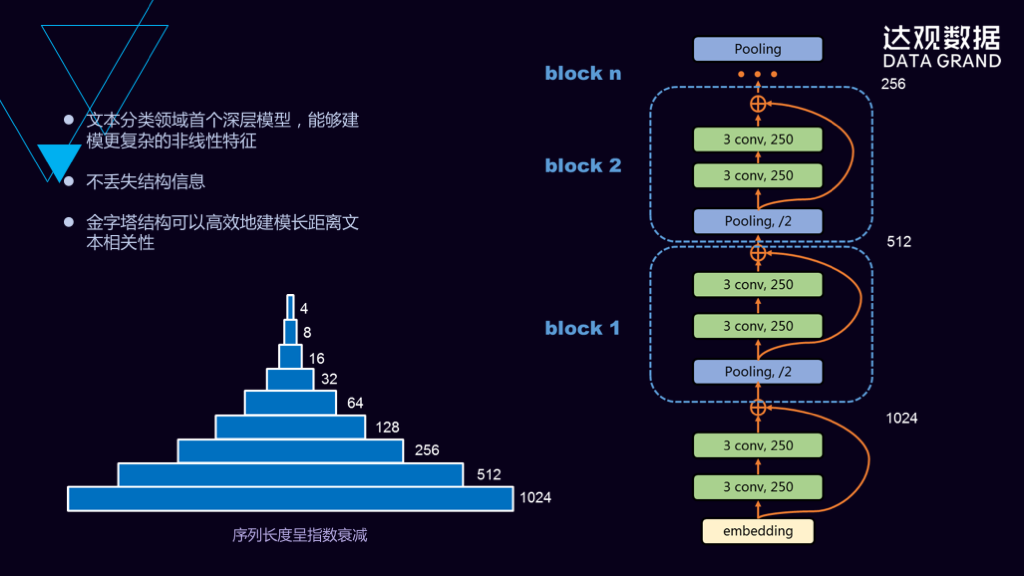
除此之外,另外一篇最新的论文所提出来的金字塔结构的卷积神经网络模型,可以非常高效的对长文本进行表示学习,最终达到一个非常好的分类效果或者标签提取效果。
除了分类和标签提取之外,信息抽取也可以用深度学习来实现,达观通常会把信息抽取问题转化成四种类型的分类问题来实现的,这样就可以充分利用前面所提到的各种网络结构,比如层次注意力模型和金字塔结构的卷积神经网络。
对于像NER或者分词这种任务来说,我们也会使用“深度学习+CRF”的方法来实现,这张PPT里面讲的就是使用“词向量+LSTM+CRF”方法来实现NER。
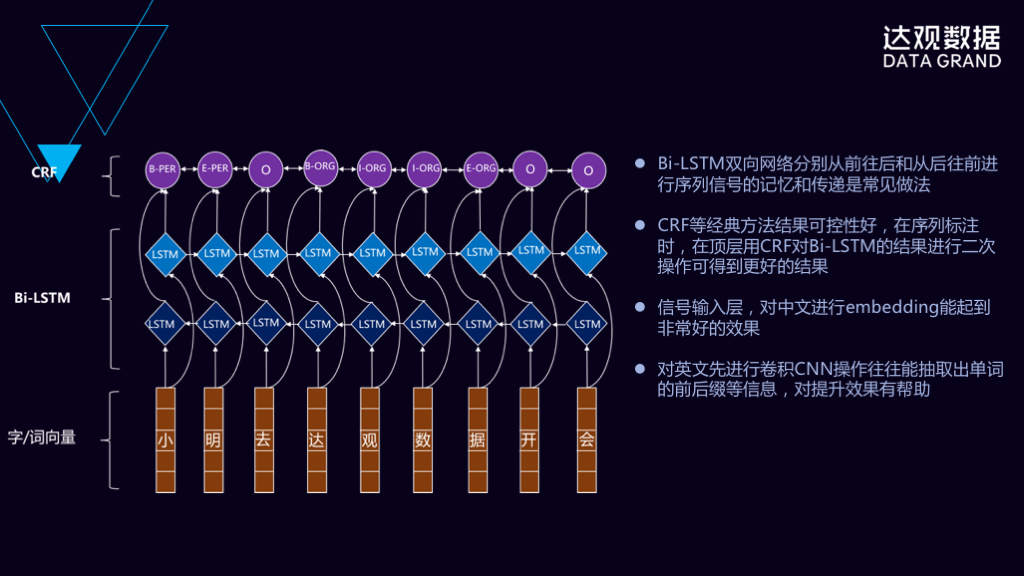
像这张使用“词向量+Bi-SLTM+CRF”通常情况下效果都是非常好的,但是对于某些特定场景下它还会有一些不足,比如非常专业的文献,像达观跟冀东石油合作的一个项目,是对石油里面的专业技术文档进行处理,这种情况下会遇到非常低频的词汇,如何对这些低频的词汇进行处理是我们需要考虑的一个问题。
达观数据采用了一个方法,是把低频词汇和专业领域的词汇通过某种表示,和原始的词向量一起拼接,作为LSTM和CRF的输入,来实现对这些低频词汇问题的解决。充分利用这些深度学习的模型和应用实践所总结出来的经验,我们可以非常高效的去处理像企业通常所遇到的合同、简历、工单、新闻、用户评论、产品说明这些文档。
四、推荐系统及其应用实践
推荐系统非常的火热,像今日头条和抖音这种通过算法推荐用户所感兴趣的东西,让用户不离开APP,都是非常成功的案例。国内类似于的趣头条等比较小的企业或者APP也非常多,它们往往会选择一家像达观这样的SaaS服务来实现它们的推荐系统。
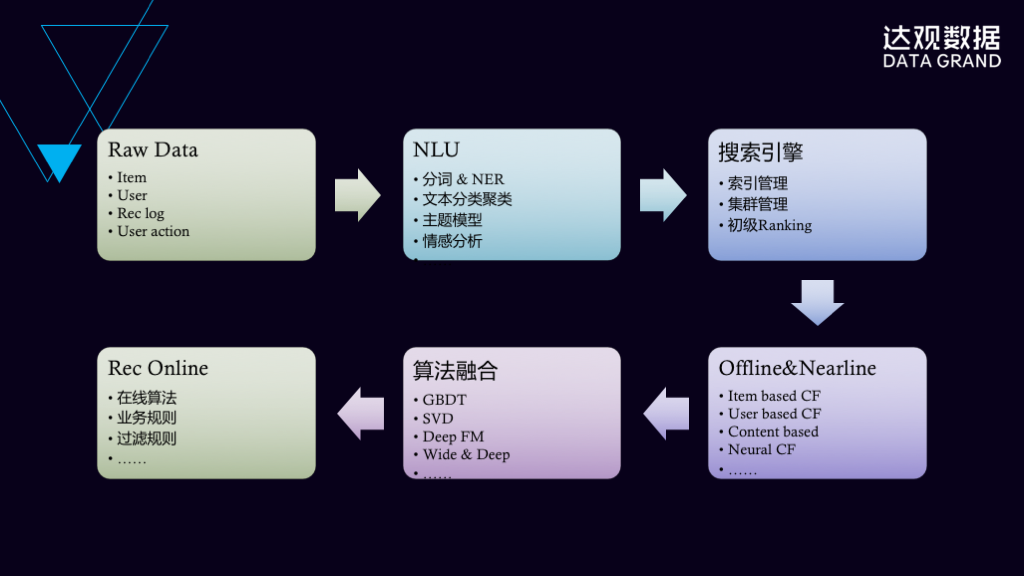
推荐系统的基本过程是像这张PPT里面所讲的一样,通过对原始的数据进行处理,使用到自然语言理解里面的分词和NER技术,使用文本的分类、主题模型、情感分析等,把这个分析结果放到搜索引擎,达观使用的搜索引擎是Elasticsearch集群,在这些集群里面会实现一个初步的Ranking处理。
以搜索引擎为基础,我们使用各种推荐算法,像协同过滤和基于内容的推荐算法,以及深度学习出来以后的神经网络协同过滤的方法,来对这种文档进行推荐。
不同的推荐算法会在同个场景下推荐出不同的内容,在这个基础上我们会使用一些融合算法,来把这些不同算法推荐的结果进行融合。我们常用的推荐融合算法包括GBDT、SVD等。
在深度学习上也有一些算法,像DeepFM这种算法也可以用来做算法融合,做推荐内容的融合。通过融合算法把不同推荐算法、推荐内容给融合起来之后,还会根据APP所要求的业务规则和过滤规则,来对这些内容进行过滤,最终把这些过滤好的结果发送给用户,这个是我们整个推荐系统的一个基本的过程。
对于推荐系统来说,底层的像协同过滤或者基于内容推荐非常成熟的算法,在算法之上如何获得更好的效果,我们会利用最前沿的深度学习推荐算法的技术。推荐系统的效果往往取决于算法的好坏。
除了传统的像CF这种算法之外,我们也尝试了非常多深度学习层面的算法,像Wide&Deep这个算法就是一个例子,Wide&Deep是我们尝试的一种算法。
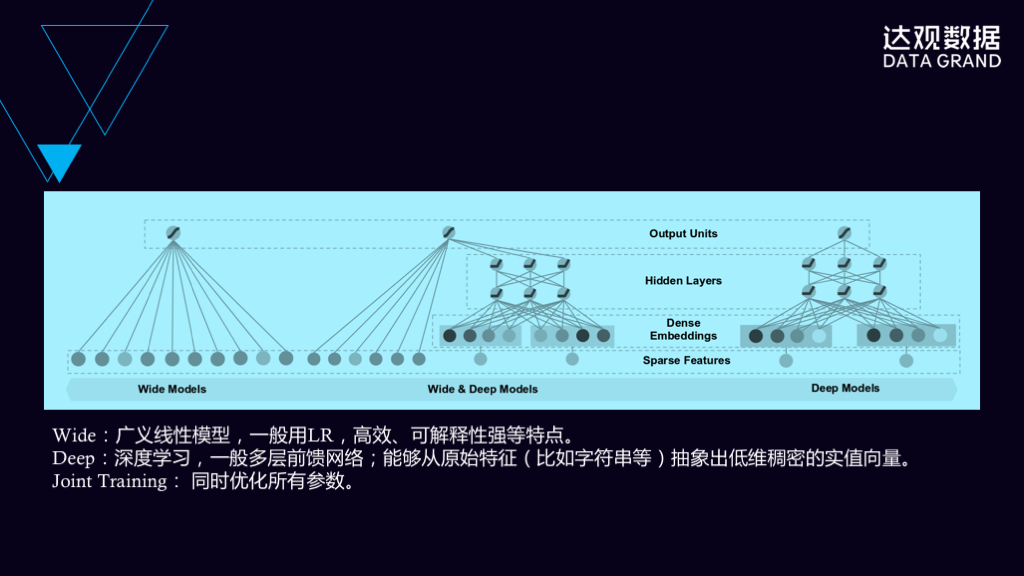
这张PPT讲的是Wide&Deep网络结构,左边是一个Wide模型,Wide模型它一般常用LR,它非常高效,可以对非常大的维度的输入进行非常高效的学习。这些输入一般是用户点击行为反馈数据。
Wide&Deep模型的Deep是右边这个模型所展示的,它是个多层的神经网络,多层神经网络可以对原始特征进行学习,学习出一些人工特征所无法抽象出来的一部分特征。通过联合训练,将Wide模型的输出和Deep神经网络的输出结合起来,获得更好的效果。
在实践中,Wide模型一般是用户反馈这种,通过LR这种非常高效的方法,把用户反馈实时的体现到推荐结果上。而Deep模型一般是用来训练像Item这种数据,可以通过离线的方法,使用非常长的时间,训练出一个更好的效果出来。Wide&Deep的优势是把实时反馈和对文章的深层理解结合起来,从而获得更好的效果。
在Wide&Deep之外,我们也尝试了神经网络协同过滤,神经网络协同过滤是在协同过滤的基础上、使用神经网络的方法来实现更好的效果。
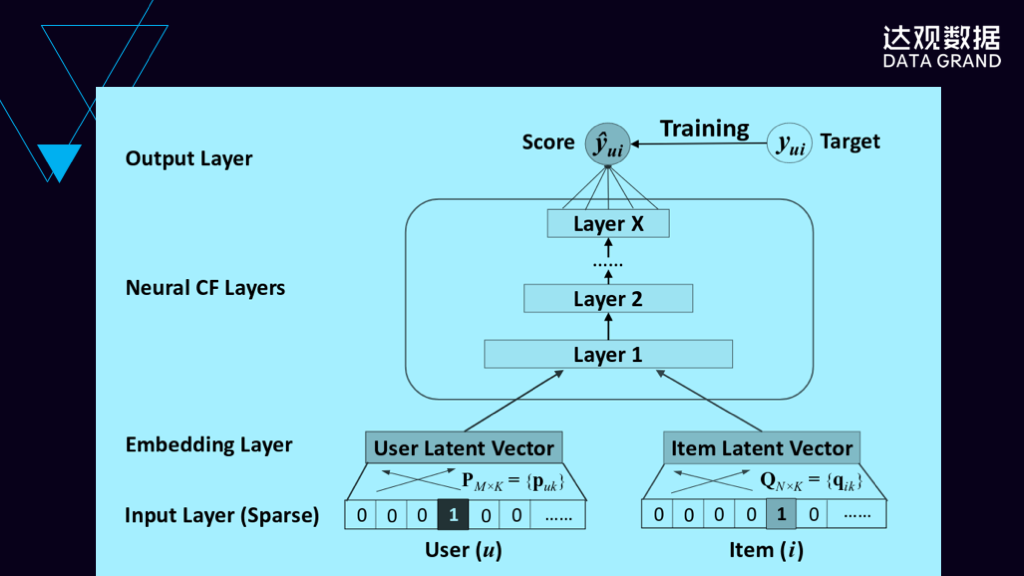
这是一个神经网络协同过滤的示意图,左下角这个输入是user层面的向量,而右下角这个输入是Item层面的向量,将user向量和Item向量输入到一个多层的神经网络上,可以通过大规模离线训练的方法,来获得一个比较好的协同过滤的效果。
这个网络结构和通常的网络结构非常相似的,一般情况下它是对user和Item通过embedding的方式,这个embedding就跟前面讲的word2vec是一样的,通过embedding把user和Item变成一个稠密编码,然后输入到一个多层的神经网络上。输入就是user、Item之间的分数值,这个网络就是一个简单的回归模型,通过非常多层的神经网络的非线形特性来实现比传统简单CF的效果会好非常多。
知识图谱是当前非常热门的一个方向。如何把知识图谱和深度学习结合起来应用到推荐系统里面,是我们去做的一个尝试。
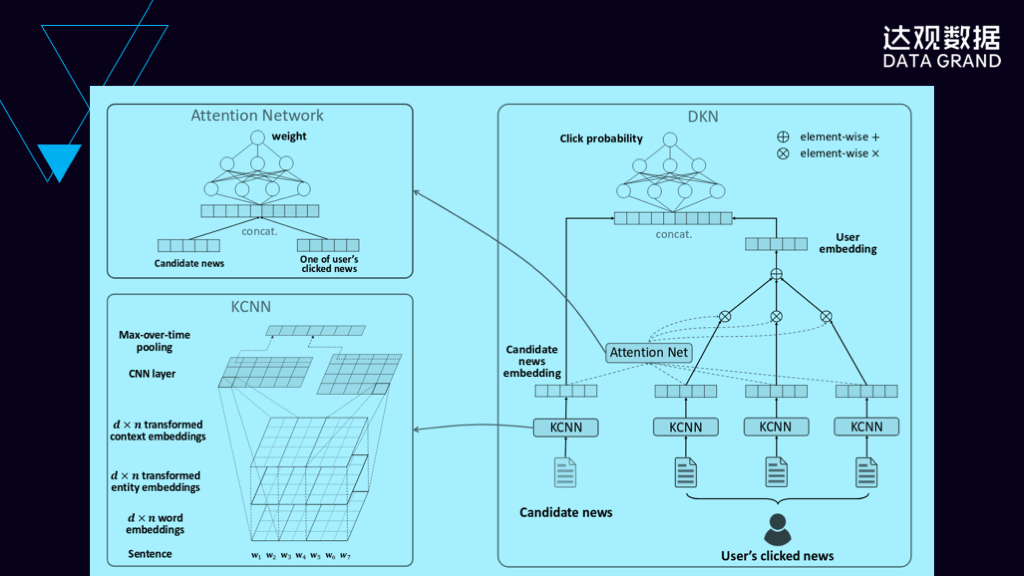
这张图可以简单的分成三个部分,左上角这部分是普通的注意力网络结构,它通过将用户所感兴趣的Item跟普通的候选集的Item进行学习,学习出一个权值,这个权值可以用来表示用户对这个新闻感兴趣的程度。左下角这个网络是是将item的内容通过表示学习学习出item的向量表示。右边大图是将左边这两个图学习出来的结果,用类似于前面提到的神经网络协同过滤的方式把它给组合起来,形成了推荐系统里对用户推荐内容候选级的学习过程。通过这种方法,在某种场景下我们可以得到更好的效果。
综合前面这些推荐算法形成的推荐系统,可以非常有效的去做好个性化推荐、相关推荐和热门推荐等各种内容,它可以广泛应用在像资讯推荐,也可以应用到简历推荐上。比如可以在HR发布一个JD的时候,给HR推荐满足这些JD要求的简历。对其他场景也可以使用推荐算法来实现,对于一个案件,可以推荐这个案件相关的其他案件,或者适用于这个案件的一些法律条文。商品推荐则是更常见的内容,它其实也是推荐系统最初使用的一个应用场景。
再简单的推销一下达观的推荐系统,它会结合前面提到的各种深度学习、自然语言理解和各种各样的算法,来实现一个非常好的推荐效果。除此之外,我们也有非常多行业应用经验,比如招商银行的掌上生活的个性化推荐,使用的就是达观给它们做的私有化部署推荐系统。像澎湃新闻APP,它们的新闻推荐系统是用我们的SaaS服务来实现的。
五、文档智能处理及其应用实践
我们在自然语言理解环节提到,文档的种类是非常丰富的,企业面临的文档也是非常多的,应用场景也是各种各样。比如对财务报表来说,需要的是信息抽取,如何把财务报表变成一个结构化的数据。而对于合同来说它包括两方面的内容,一方面是写合同的时候是否写得符合合同法和企业内部的法务规定;另一方面则是针对审核合同的人,是否放过了一个不符合合同规定的条款,或者,如何去防止合同里面阴阳合同的情况出现。
其他还包括文档的智能搜索,如何去搜一大篇几百页文章里的某些文字,然后把对应的字段给显示出来。应用场景包括,员工刚入职一家公司,需要一个公司手册一样的内容,想理解报销或者请假是怎么去走流程的时候,就要去搜这个文档。如何做到不需要展示给员工整个文档,而是直接给到员工对应的章节,对于企业则是一个能够确实提高员工工作效率的问题。这些问题都是达观所擅长解决的。
除了读、搜、审之外,还有一个场景是更好的利用深度学习和自然语言理解来帮助写文档的人更好更快的写作,比如辅助去写新闻、报告等。
下面,我以场景来做技术层面的解析,比如文本分类.前面提到了非常多深度学习的分类器,还包括一些传统学习的分类器,都可以用来做文本分类。传统学习的优势是在语料比较少的时候,比如JD就是职位描述,这种场景下一般企业的职位描述就是几百个或者几千个,从深度学习的方法去实现,可能效果并不是特别好,这种情况下我们会选择像传统的方法,决策数或者SVM来实现对JD的分类。而对于简历,简历的规模往往是JD的100倍以上,这种情况下我们就可以用前面提到的层次注意力模型和金字塔结构的CNN来实现对简历的分类。
除了分类之外,像信息抽取通常使用的是CRF,CRF可以达到一个比较好的效果,它的标注语料要求可能比较低,几百到一两千份就能够实现比较好的效果。当企业有更多语料的时候,我们就可以使用深度学习的方法来实现。前面已经提到过,我们可以把信息抽取转化成分类问题来实现,前面提到的各种分类算法,像金字塔结构的CNN和层叠注意力模型都可以用来做分类。
除此之外,我们在推荐系统环节所提到的像Wide&Deep这种算法,结合LR和深度网络的方法,也可以用来做这个信息抽取的事情。
这个方式说起来也比较简单,可以把CRF当作Wide模型,然后用深度网络Deep模型,用联合训练方法把它们结合起来,这样可以实现类似于迁移学习的效果,就是我们可以预先训练好一个深度网络,然后把深度网络给固化起来。在面对企业没有大量GPU的时候,我们只要重新去训练这个Wide,Wide模型可以使用比较简单的像CRFPP等工具来实现。这种方法可以很好的均衡资源的使用和效果。
除了企业对文档抽取有要求之外,其实文档的智能比对也是一个非常重要的应用场景,这种比对是在文档的信息抽取之上构建的。在信息抽取之上,我们通常使用规则来实现比对这个功能,只要信息抽取的效果足够好,比对效果一般都不会太差。
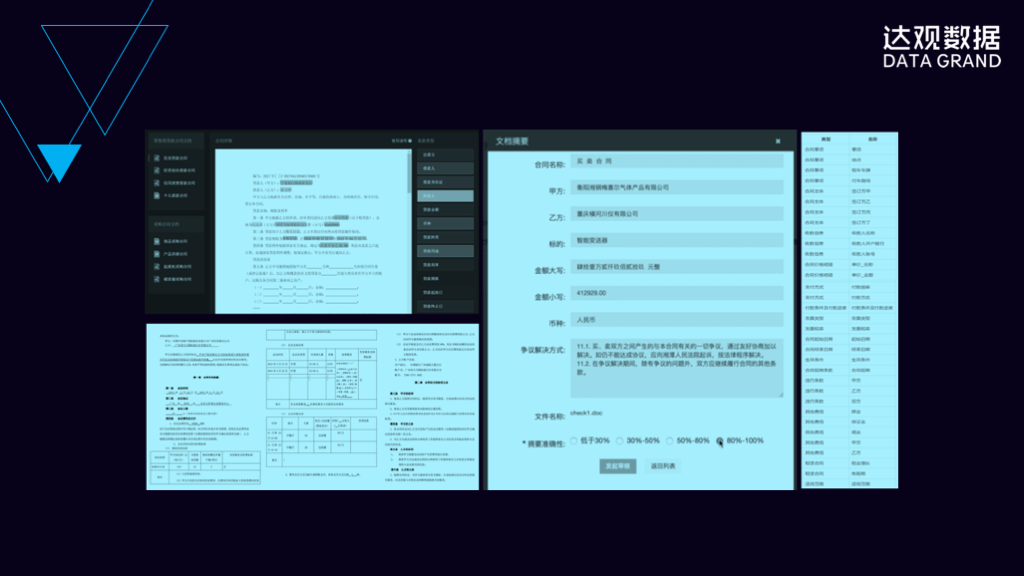
这是我们实际的一些应用场景,它通过信息抽取技术把关键信息给抽取出来,然后使用各种业务规则对合同进行智能审阅。这种简单的方法就可以达到非常高的效果,可以替企业节省大量的法务人员。单个文档的审阅时间节省得非常多,同时可以让企业节省200个法务的人力。人工智能和文本智能审阅的使用,可以给企业带来非常大的收益,同时可以让这200个人做更有意义的工作。这个是合同审阅的效果图。
六、总结
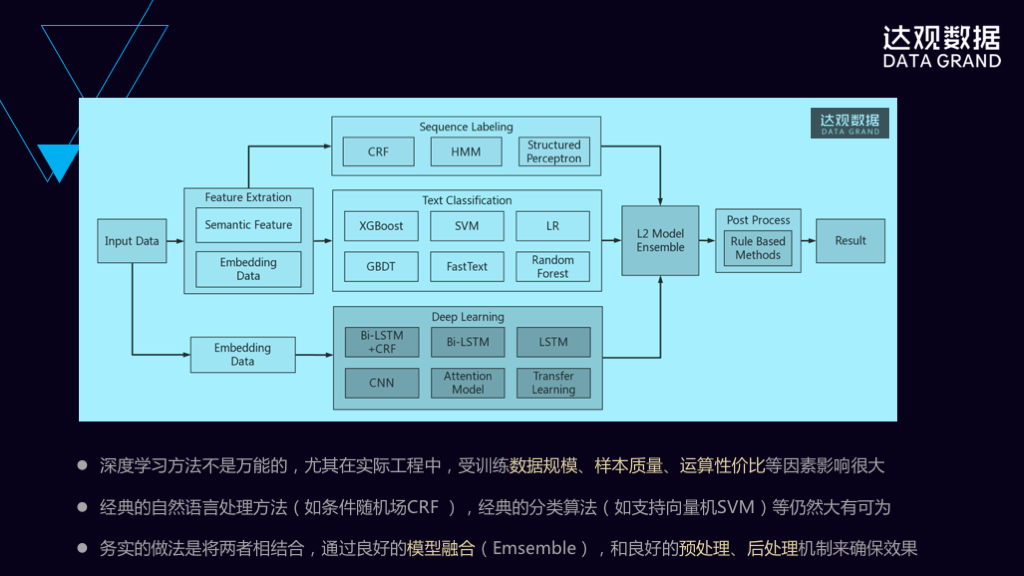
这是达观使用的架构图,我们可以把输入通过各种特征工程,使用传统的方法来做机器学习,也可以通过Embedding的方式使用各种深度网络来实现,最终会使用一些融合算法,来把不同模型的结果输出做算法融合,最后做些后处理,比如各种业务规则、各种过滤条件、各种在国内特殊国情所不能出现的内容都要过滤掉,得到一个结果出来。
并不仅仅是深度学习效果好就使用它,我们会根据具体的应用场景来选择。如当数据规模小的时候就无法使用深度学习来做,当资源要求比较高的情况下,我们也不会选择深度学习。

这是我们公司的获奖情况,若干年后很多基础文字处理工作都会被计算机替代,更多文员职位的人可以做更有意义的事情,我们未来会成为文本自动化处理方面的领军企业。





